TPU Pods enable large-scale parallelism by distributing model and data across multiple TPU cores, accelerating BERT training significantly.
Here is the code snippet you can refer to:
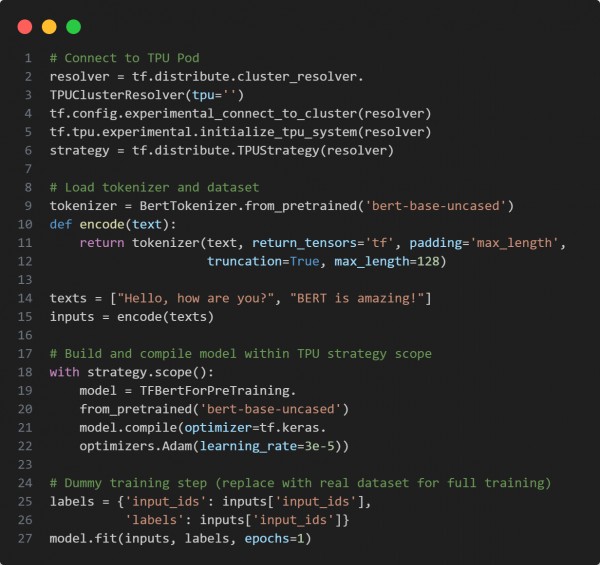
In the above code, we are using the following key points:
-
TPUClusterResolver: Detects and connects to the TPU Pod.
-
TPUStrategy: Distributes training across all TPU cores in the pod.
-
HuggingFace's TFBertForPreTraining: Loads pretrained BERT for fine-tuning or large-scale training.
-
Tokenization with padding/truncation: Prepares inputs for uniform TPU batch processing.
-
Model compilation and training inside strategy scope ensures it runs on TPU.
Hence, TPU Pods scale BERT training efficiently by leveraging distributed computation across multiple cores.
 REGISTER FOR FREE WEBINAR
X
REGISTER FOR FREE WEBINAR
X
 Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
























