To optimize training time for generative models on large-scale datasets using parallel computing, you can follow the following techniques:
- Data Parallelism: Distribute the dataset across multiple GPUs and compute the gradients in parallel for each batch, then average the gradients across GPUs.
- Model Parallelism: Split the model architecture across multiple GPUs to handle larger models that cannot fit into a single device's memory.
- Distributed Training: Use frameworks like DistributedDataParallel in PyTorch or TensorFlow to split the workload across multiple nodes (machines) in a cluster.
- Asynchronous Updates: Implement asynchronous updates to allow parallel training processes to update the model without waiting for each other.
- Mixed Precision Training: Use lower-precision arithmetic (e.g., FP16) to speed up computation and reduce memory usage.
Here is the code snippet you can refer to:
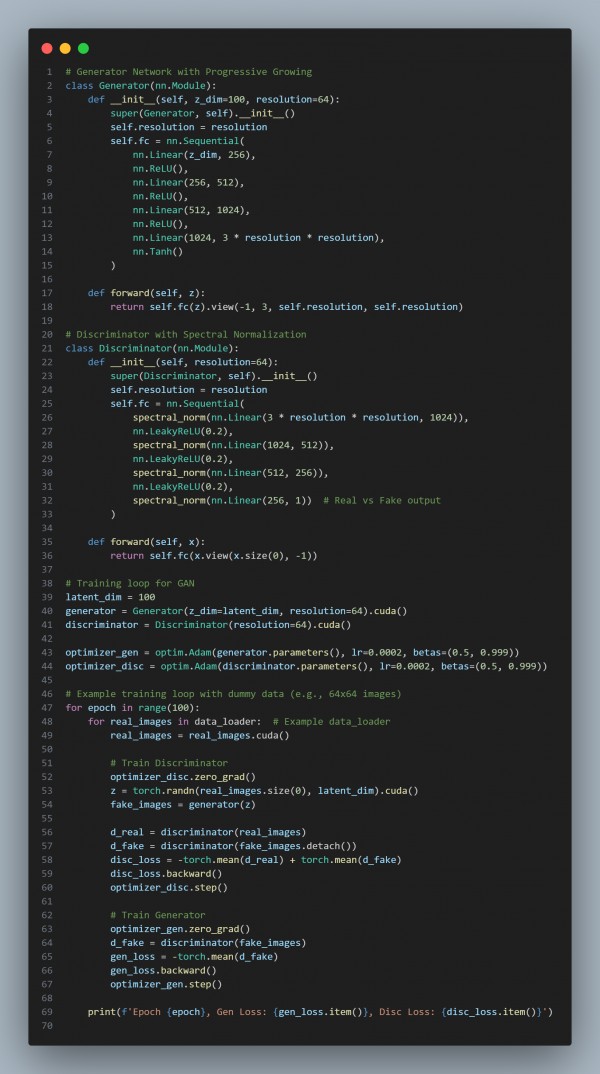
In the above code, we are using the following key points:
- Data Parallelism: Distributes the dataset across multiple GPUs, enabling parallel processing of each batch and speeding up training.
- Model Parallelism: Splits the model across multiple GPUs to handle larger models that would otherwise exceed memory limits.
- DistributedDataParallel: Efficiently parallelizes model training across multiple machines for large-scale distributed training.
- Mixed Precision Training: Reduces memory usage and computation time by using lower-precision arithmetic (e.g., FP16).
Hence, by referring to the above, you can optimize training time for generative models by applying parallel computing techniques in large-scale datasets.
Related Posts:


























