The performance degradation in a Transformer model for machine translation is likely due to overfitting, learning rate decay issues, poor regularization, or vanishing gradients in deep layers, and can be mitigated using learning rate scheduling (warmup), dropout, gradient clipping, data augmentation, and layer normalization.
Here is the code snippet you can refer to:
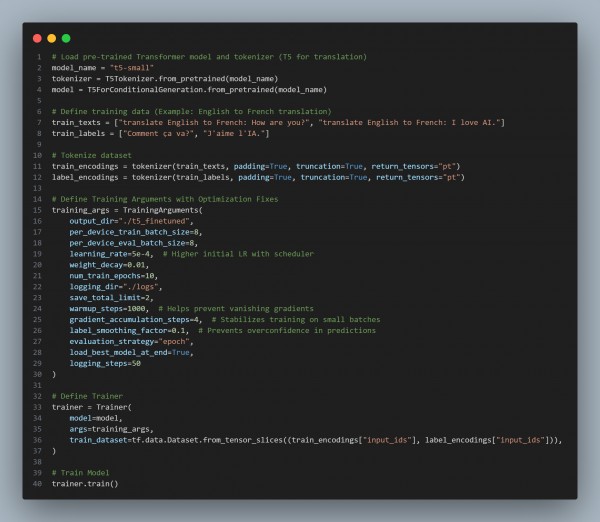
In the above code we are using the following key approaches:
-
Uses Warm-Up Learning Rate Scheduling:
- Prevents vanishing gradients by gradually increasing the learning rate at the start (warmup_steps=1000).
-
Applies Gradient Accumulation (gradient_accumulation_steps=4)
- Reduces training instability on small batch sizes without increasing GPU memory usage.
-
Implements Label Smoothing (label_smoothing_factor=0.1)
- Prevents overconfidence in predictions, reducing overfitting in translation tasks.
-
Includes Weight Decay (weight_decay=0.01) for Regularization
- Prevents overfitting by discouraging extreme weight updates.
-
Saves Best Model and Evaluates Performance on Each Epoch (load_best_model_at_end=True)
- Ensures the best-performing checkpoint is used for inference.
Hence, implementing warm-up learning rates, gradient accumulation, label smoothing, and regularization stabilizes Transformer training, preventing performance degradation in machine translation.


























