To add different attention mechanisms in a Keras Dense layer, use self-attention, additive attention, or multiplicative attention to dynamically weight input features before passing them to the Dense layer.
Here is the code snippet you can refer to:
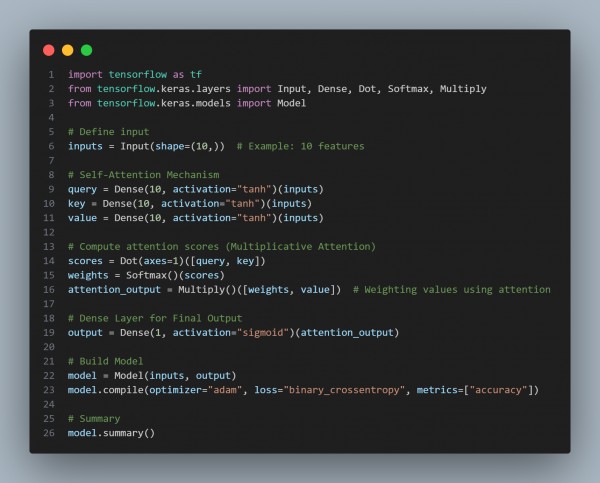
In the above code we are using the following key points:
- Uses Query, Key, and Value layers for attention score computation.
- Multiplicative Attention (Dot Product) is applied to calculate attention weights.
- Softmax normalization ensures proper weighting of input features.
- Final Dense layer receives weighted attention-enhanced inputs for classification.
Hence, different attention mechanisms like self-attention or multiplicative attention can be integrated before a Dense layer to enhance feature selection and improve model performance.
 REGISTER FOR FREE WEBINAR
X
REGISTER FOR FREE WEBINAR
X
 Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP