The best way to split a dataset while preserving the target distribution in Scikit-learn is by using train_test_split with stratify=y or StratifiedShuffleSplit, ensuring that class proportions remain balanced in both training and testing sets.
Here is the code snippet you can refer to:
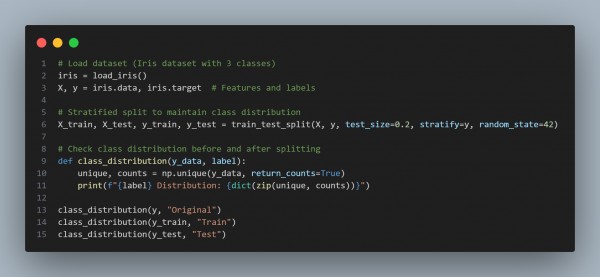
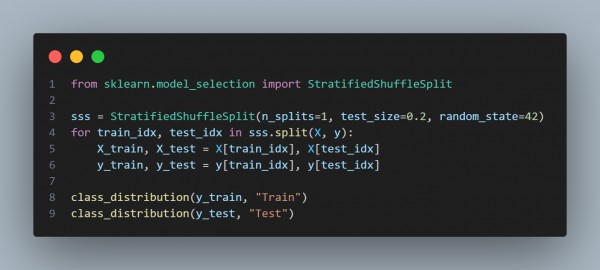
In the above code, we are using the following code snippets:
-
Preserves Class Distribution (stratify=y)
- Ensures proportions of target classes remain the same in train and test sets.
-
Prevents Imbalance in Training Data:
- Especially useful for imbalanced datasets where one class is significantly underrepresented.
-
Works for Both Multi-Class & Binary Classification:
- Maintains balanced class representation, improving model generalization.
-
Use StratifiedShuffleSplit for Fine-Tuned Splitting:
- Ideal for multiple resampling iterations while keeping class proportions.
-
Ensures Reproducibility (random_state=42)
- Allows for consistent splits across different runs.
Hence, using train_test_split with stratify=y or StratifiedShuffleSplit ensures balanced class distributions in training and testing sets, leading to more reliable model evaluation
Check out our How to structure training loops in your generative AI code post to know more!


























