To prevent gradient vanishing during deep generative model training, you can follow the following key points:
- Use ReLU or Leaky ReLU Activations: These activations help maintain gradients, unlike sigmoid or tanh which are prone to vanishing gradients.
- Batch Normalization: Apply batch normalization to stabilize the activations and gradients.
- Use Residual Connections: Implement residual or skip connections to allow gradients to flow more easily through the network.
- Use He Initialization: Proper weight initialization, like He initialization, helps in maintaining gradient flow.
Here is the code snippet you can refer to:
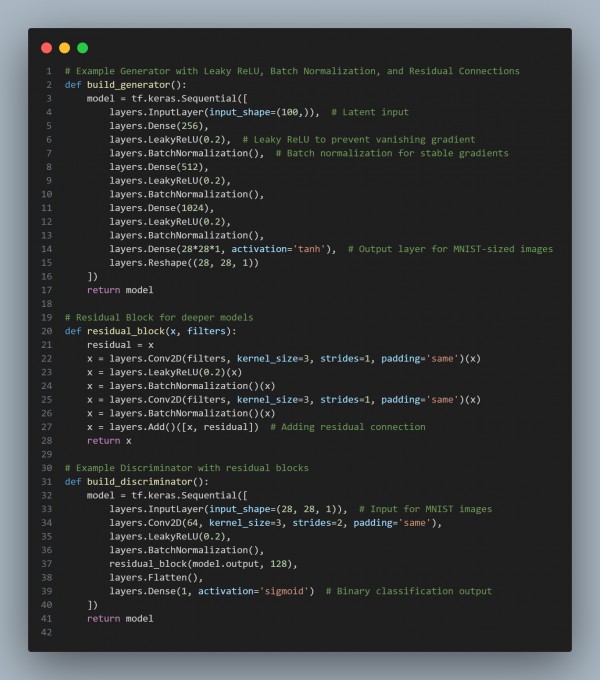
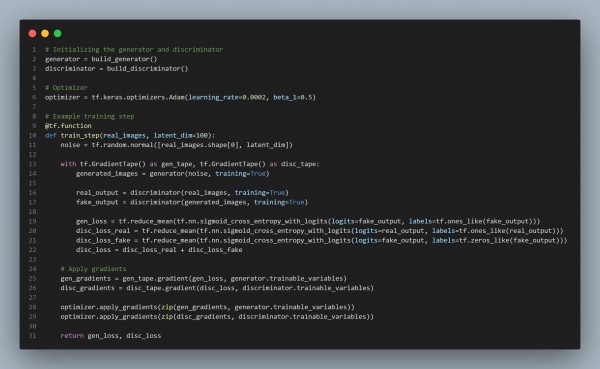
In the above code, we are using the following strategies:
- Leaky ReLU: Prevents the vanishing gradient problem by allowing a small negative slope.
- Batch Normalization: Normalizes activations to maintain stable gradients across layers.
- Residual Connections: Helps to counteract vanishing gradients by allowing the flow of gradients directly through skip connections.
- He Initialization: Proper weight initialization (default in Keras for ReLU) prevents gradients from vanishing at the beginning of training.
Hence, these techniques ensure the gradients do not vanish, enabling stable training in deep generative models.
Related Post: Managing gradient issues in deep generative models like GANs and VAEs


























