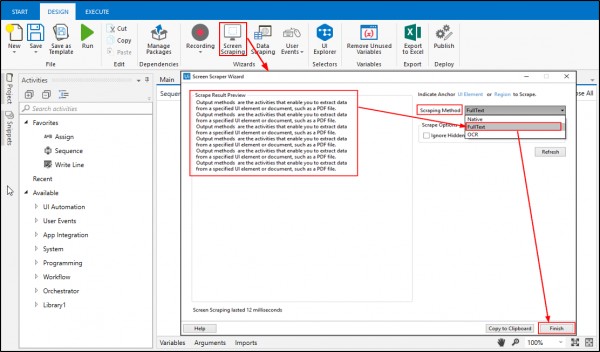
Hey @Amar, Output methods are the activities that enable you to extract data from a specified UI element or document, such as a PDF file. The 3 main methods of screen scraping are as follows:
1. Full Text: Full Text is the default output method and it is fastest and accurate. But it cannot extract the screen coordinates of the text and it work only on desktop applications. It works in the background and also extracts the hidden text.
2. Native: Native method extracts the text with its position on the screen, as well as retrieve the exact position of each word. This method doesn't allow background execution and hidden text extraction also. Native method only works with apps that are built to render text with the Graphics Device Interface (GDI).
3. OCR: OCR is not 100% accurate, but can be useful to extract text that the other two methods could not, as it works with all applications including Citrix. Studio uses two OCR engines, by default: Google Tesseract and Microsoft Modi.
To start extracting text from various sources, click the Screen Scraping button, in the Wizards group, on the Design ribbon tab. The screen scraping wizard enables you to point at a UI element and extract text from it, using one of the three output methods described above. Studio automatically chooses a screen scraping method for you, and displays it at the top of the Screen Scraper Wizard window.