To optimize the training of generative models using gradient-based optimization methods, you can follow the following approaches:
- Use of Efficient Optimizers: Employ optimizers like Adam or RMSprop, which adapt learning rates for each parameter and help stabilize training.
- Gradient Clipping: Prevent exploding gradients by clipping gradients during backpropagation.
- Learning Rate Scheduling: Gradually decrease the learning rate to improve convergence towards the optimal solution.
- Weight Initialization: Proper initialization of weights (e.g., Xavier or He initialization) can help improve convergence.
- Gradient Penalty: Apply techniques like Wasserstein loss with gradient penalty (WGAN-GP) to stabilize GAN training.
Here is the code snippet you can refer to:
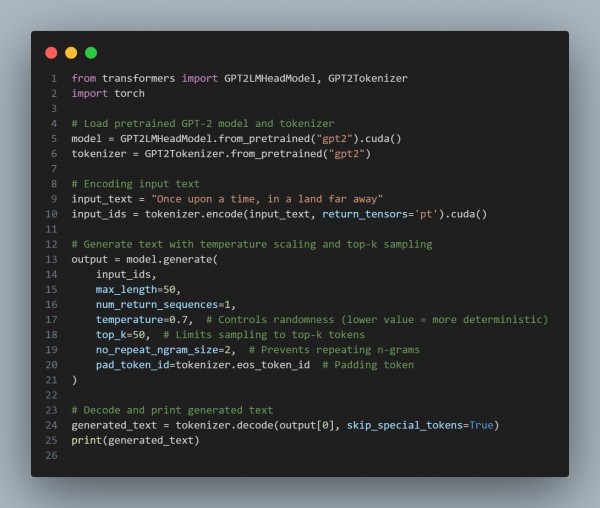
In the above code, we are using the following key points:
- Adam Optimizer: Used for both generator and discriminator, adapts learning rates to stabilize training.
- Gradient-Based Optimization: Updates model parameters through backpropagation, using gradients to minimize the loss.
- Adversarial Loss: Ensures that the generator produces realistic images and the discriminator can distinguish between real and fake photos.
- Learning Rate Scheduling: This can be implemented to reduce the learning rate over time for finer training adjustments (not shown here but can be added for better convergence).
Hence, by referring to the above, you can optimize the training of generative models using gradient-based optimization methods
Related Posts: