You can refer to the following methods to speed up the training of autoregressive models for text generation:
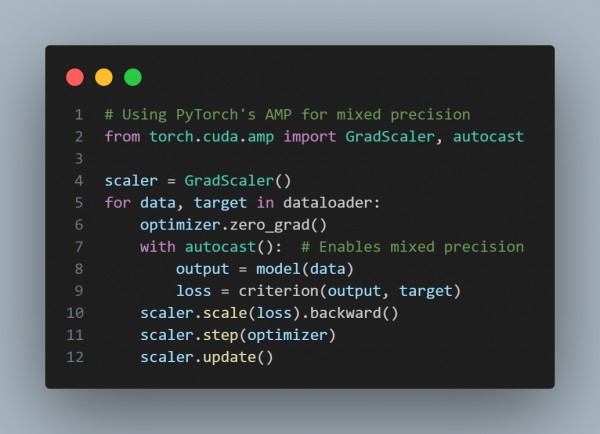
- Mixed Precision Training: Reduces memory usage and speeds up training by using lower precision (e.g., FP16) without a significant loss in accuracy.
- The code below uses Mixed precision to reduce computation time and memory by using lower precision without major accuracy loss.
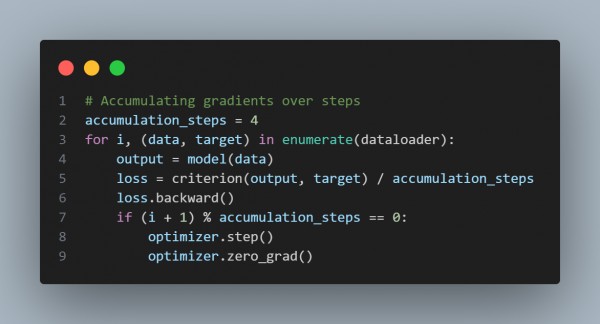
- Gradient Accumulation: Accumulates gradients over several batches to simulate a larger batch size without increasing memory usage.
- The code below simulates larger batch sizes by accumulating gradients, reducing memory needs per batch.
- Sequence Length Truncation: Truncate input sequences to a maximum length, reducing computation on long inputs that contribute less to training.
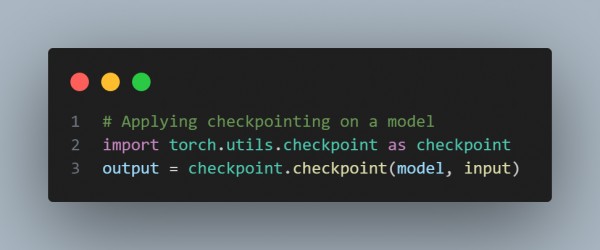
- The code below reduces memory usage by not storing intermediate activations and recomputing them as needed.
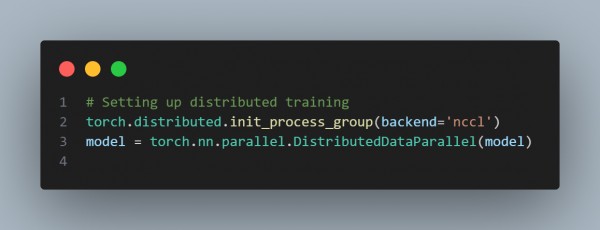
- Data Parallelism: Distribute data across multiple GPUs to process batches in parallel, speeding up training.
- The code below avoids redundant calculations by reusing cached tokens in an autoregressive generation.

- Gradient Checkpointing: It saves memory by trading some compute: it recomputes certain layers in the backward pass rather than storing intermediate activations.
- The code below parallelizes training across GPUs, allowing larger batches and reducing time.
Hence, using these practical methods, you can speed up the training of autoregressive models for text generation.


























