Challenges of multi-head attention in transformers for real-time applications are as follows:
-
High Computational Cost: Multi-head attention involves multiple matrix multiplications per head, which can be computationally expensive. Each head needs separate key, query, and value projections, increasing the model’s complexity.
-
Memory Usage: Storing and processing multiple attention heads and their weights can lead to high memory consumption, especially in large models. It limits scalability on devices with constrained memory, like edge devices or mobile platforms.
-
Latency Issues: High-dimensional matrix multiplications and the sequential nature of the attention mechanism introduce latency. This latency may be impractical for real-time applications, where prompt responses are crucial.
-
Inefficient Parallelization: Attention operations can be challenging to parallelize due to dependencies between layers and heads. This limitation hinders the potential speed-up when using GPUs or other accelerators.
-
Energy Consumption: Multi-head attention is computationally dense and demands significant energy, which can be a problem for real-time, energy-sensitive applications.
You can optimize these challenges by referring to the following:
- Reducing the Number of Attention Heads: Reducing the number of attention heads can decrease computation, though it might slightly impact model accuracy.
- The code snippet below shows how you can reduce the number of attention heads.
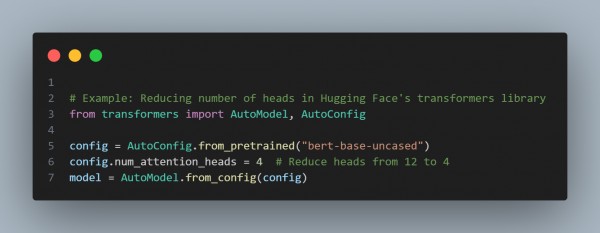
- Use Low-Rank Matrix Factorization: To reduce memory and computation, you can approximate attention matrices using low-rank decomposition (e.g., SVD).
- The code snippet below shows how you can implement the use of low-rank matrix factorization.

-
Sparse Attention Mechanisms: You can implement sparse attention to reduce the number of computations by focusing on the most important attention weights. Libraries like OpenAI’s Sparse Transformer implement sparse patterns.
-
Quantization: You can quantize the model weights (e.g., from 32-bit to 8-bit) to reduce memory footprint and increase speed without significant accuracy loss.
- The code snippet below shows how you can use quantization using PyTorch.
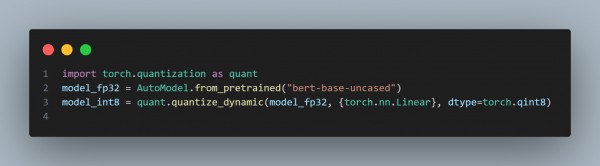
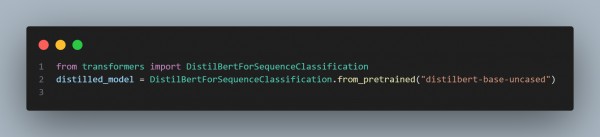
By using these optimization techniques, you can handle the challenges of multi-head attention in transformers for real-time applications.
Learn the best practices for fine-tuning a Transformer model with custom data to achieve optimized, task-specific performance.
Related Post: advantages and challenges of using attention mechanisms in GANs


























