Fine-tuning the GPT model on the domain-specific or task-oriented data improves their performance dramatically in specific tasks or domains. Here are some techniques about fine-tuning with GPT models, along with an example, to assist you in the fine-tuning process.
Techniques about Fine-Tuning GPT Models
Data Preparation
- Data Cleaning: Cleaning is one of the key phases where all the datasets are ensured to be correct and cleaned with proper format so that they do not carry unnecessary information or duplication and also remove noises.
- Tokenization: In tokenization, the same pre-trained tokenizer would be reused again to maintain consistency and compatibility of the output in both cases.
- Formatting: Format your data in a suitable format such as JSON or CSV, where the input and output represent every entry.
Pre-trained Models
- Hugging Face's Transformers has a library of pre-trained models along with tools to fine-tune them.
Training Strategies
- Learning Rate Scheduling: The training schedule can be adjusted based on the learning rate to avoid overshooting the optimal parameters.
- Batch Size: Experiment with different batch sizes to find the right balance between using more memory and training time.
- Gradient Accumulation: If memory is limited, use gradient accumulation to simulate larger batch sizes.
Evaluation
- Validation Set: Divide your dataset into training and validation sets to monitor performance and avoid overfitting.
- Metrics: Choose the appropriate metrics (like perplexity and accuracy) to measure model performance.
Hyperparameter Tuning
To optimize the training, experiment with hyperparameters such as learning rate, batch size, and number of epochs.
Model Checkpointing:
Save model checkpoints during training to resume later or to prevent data loss in case of interruptions.
Example: Fine-Tuning GPT-2 Using Hugging Face Transformers
Here's a step-by-step example of how to fine-tune a GPT-2 model using the Hugging Face Transformers library in Python.
Step 1: Install Required Libraries
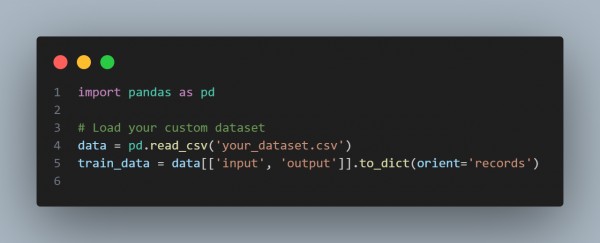
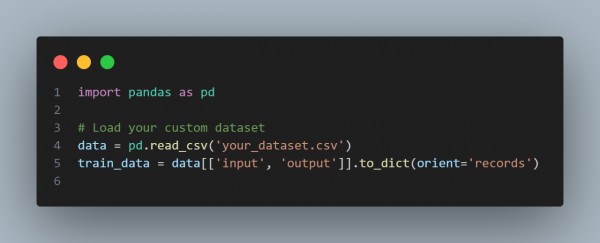
Step 2: Prepare Your Dataset
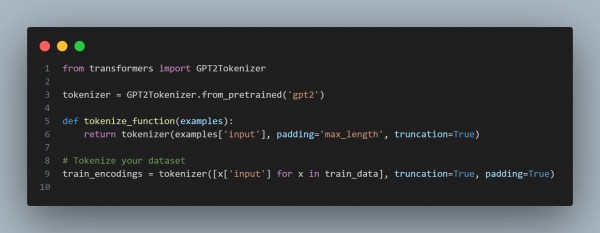
Step 3: Tokenize the Dataset
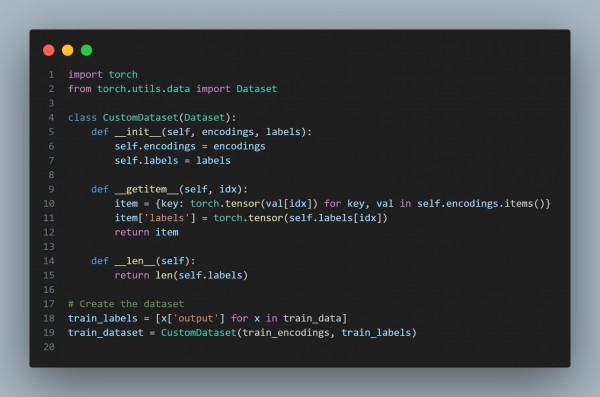
Step 4: Create a Dataset Class
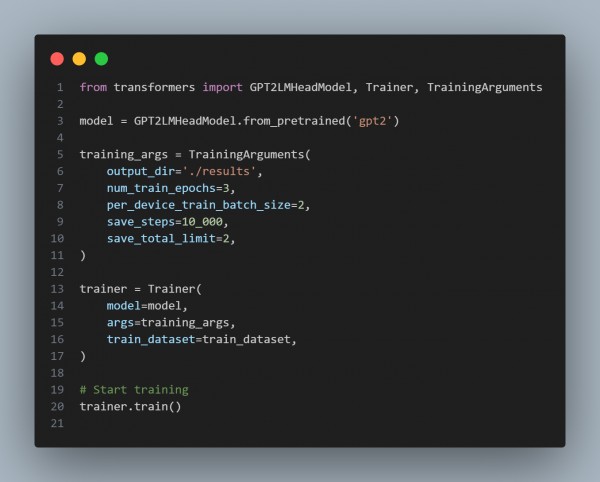
Step 5: Fine-Tune the Model
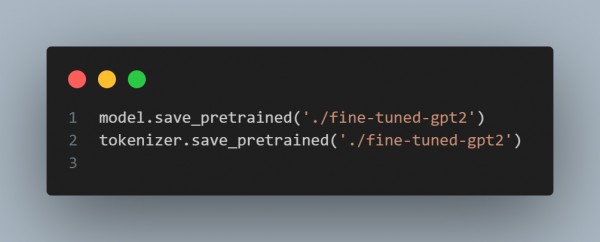
Step 6: Save the Fine-Tuned Model