There are various methods you may employ to successfully increase the variety and caliber of training data for text-based generative models. Here is optimized reference :
Techniques for Data Augmentation
Similar to image processing, diversity can be increased by augmenting text data. You can accomplish this by:
Synonym Replacement: To make sentences more varied, swap out terms for their synonyms.
Back translation is the process of translating text into another language and then back again to provide data that has been paraphrased.
An illustration of nltk-based synonym replacement:
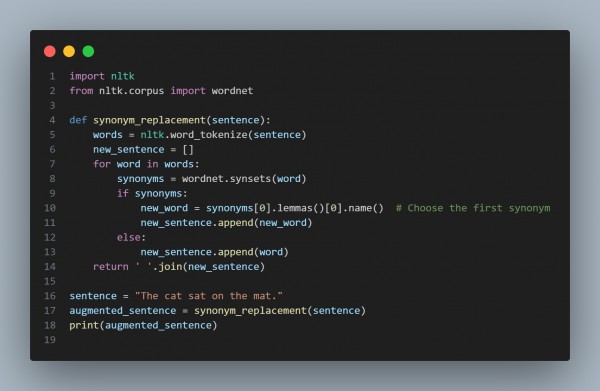
Gather Information from Various Sources
To create a comprehensive and diverse training set, collect data from several sources and domains. This may consist of:
Public Datasets: Make use of publicly available datasets such as news articles or Common Crawl.
Create your own web scrapers to gather information from pertinent websites that belong to your target domain.
Make Use of Transfer Learning
Start with pre-trained models (like GPT or BERT) that have been refined on your own data after being trained on a sizable and varied corpus. This method aids in preserving a healthy balance between domain-specific knowledge and general language comprehension.
Produce Artificial Information
Use alternative generative models (such as GPT-2 or GPT-3) to generate synthetic training data for domains with limited data. Be sure to assess this artificial data.
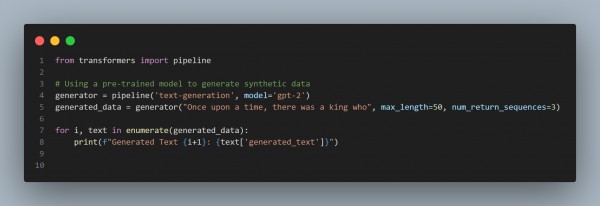
Sort and Enhance the Information
Use strategies such as these to make sure your training data is varied:
Eliminate redundant sentences or sections to avoid overfitting to recurring patterns.
To ensure that only pertinent and high-quality content is kept, use models or algorithms to weed out low-quality data.
These are the five efficient data augmentation techniques you can use.
Related Post: Data Augmentation Techniques


























