To reduce latency in your chatbot that employs a GPT model, you can adopt the following strategies:
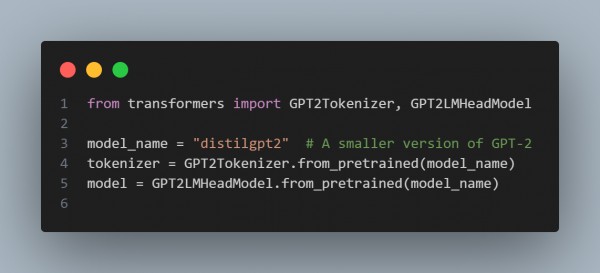
Optimize Model Size: Consider utilizing a smaller GPT model. While larger models produce faster replies, smaller models can significantly cut response time. Consider employing models such as GPT-2 or distilled versions of GPT3.
Batch Processing: If your program is capable of handling it, process numerous user requests at once. This way, you may take advantage of the model's parallel processing capabilities.

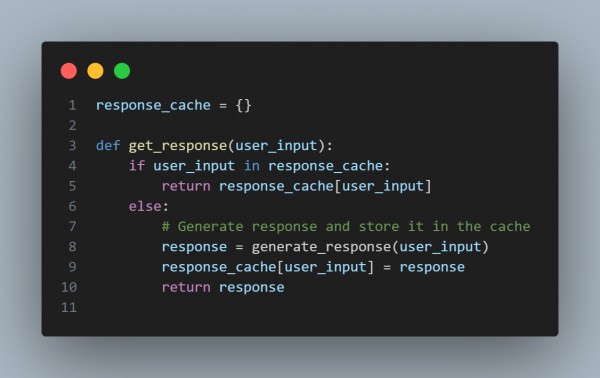
Caching Responses: Create a cache for commonly requested queries or common responses. If the chatbot receives the same input, it can return the cached output without reprocessing it.
Asynchronous Processing: Asynchronous Processing allows you to handle requests without interrupting the main thread. This allows your application to continue processing other activities while the model generates a response.

Server Location: If you're hosting your model on a server, make sure it's close to where your users are. This reduces network latency dramatically.
Using these strategies, you can handle issues related to latency in your real-time applications, like, in this case, a chatbot that uses the GPT model.
Related Post: How can I reduce latency when using GPT models in real-time applications


























