MongoDB is a NoSQL database, whereas Hadoop is a framework for storing & processing Big Data in a distributed environment.
MongoDB
MongoDB is a document oriented NoSQL database. MongoDB stores data in flexible JSON like document format. The fields can vary from document to document, and it gives you the flexibility to change the schema any time. MongoDB is a distributed database, so it provides high availability & horizontal scalability. You can perform real-time aggregations & ad-hoc querying. You can easily map the documents to your applications.
To know more go through this blog:
https://www.edureka.co/blog/mongodb-the-database-for-big-data-processing/
Hadoop
Hadoop is a collection of software which is used to store & process big data.
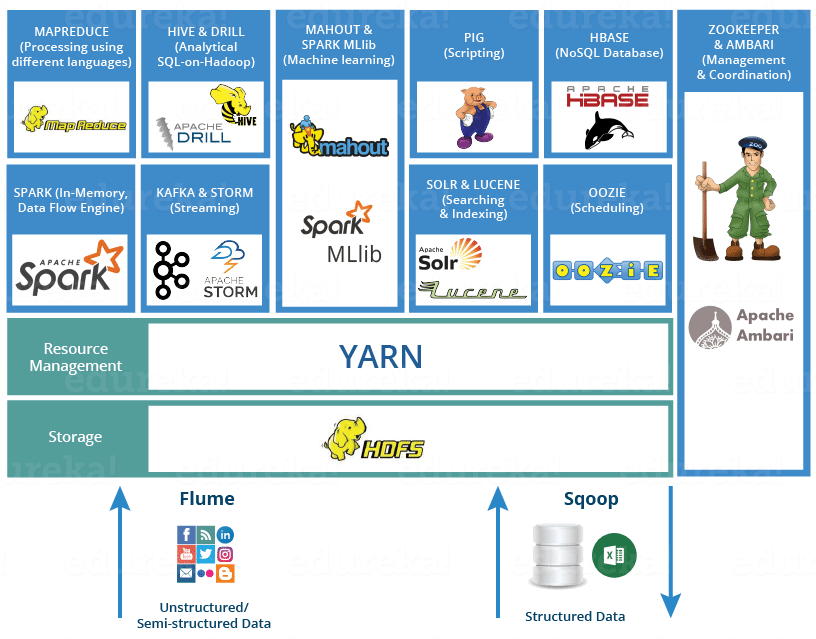
Core components of Hadoop are HDFS & YARN.
HDFS (Hadoop Distributed File System) is the storage part of Hadoop. HDFS file system stores data in a distributed environment, so that data can be processed in a parallel manner. YARN (Yet Another Resource Negotiator) is the resource manager in Hadoop. YARN is the one which allocates resources to various job which are getting submitted to Hadoop.
On top of YARN, you have multiple tools which can be used to process data. You can either write Mapreduce programs or execute Pig or Hive queries. HBase is again a column oriented NoSQL database which runs on top of Hadoop.
I would recommend you to go through these Hadoop Tutorial & hadoop ecosystem blog:
https://www.edureka.co/blog/hadoop-tutorial
https://www.edureka.co/blog/hadoop-ecosystem
You can even check out the details of Big Data with the Azure Data Engineer Course.
Hope this will help!
To know more about it, get your Mongodb certification today.
Thanks.


























