Multi-GPU training can become slower due to communication overhead, inefficient batch sizes, or improper data parallelism strategies.
Here is the code snippet you can refer to:
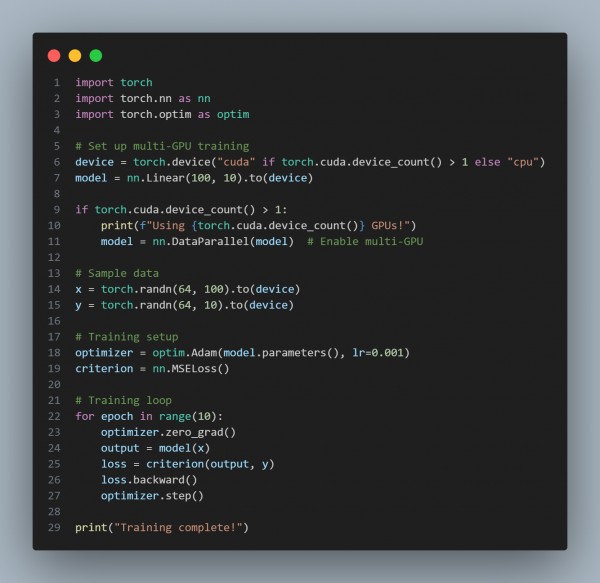
In the above code, we are using the following key points:
- Communication Overhead: Multi-GPU requires synchronization, which can slow down performance.
- Inefficient Batch Size: Small batch sizes may not fully utilize GPU power.
- Imbalanced Workload: Uneven distribution across GPUs can cause bottlenecks.
- Data Transfer Delays: Slow PCIe or memory bandwidth can impact training.
- Optimization Required: Techniques like torch.nn.DataParallel or torch.distributed can improve efficiency.
Hence, By referring to above, you can know why multi-GPU training slower than single-GPU training.
 REGISTER FOR FREE WEBINAR
X
REGISTER FOR FREE WEBINAR
X
 Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
























