To remove stopwords using NLTK's stopwords corpus in generative AI pipelines, you can filter out common words (e.g., "the", "is", "in") that don't contribute much meaning, improving model performance by focusing on more relevant tokens.
Here is the code snippet you can refer to:
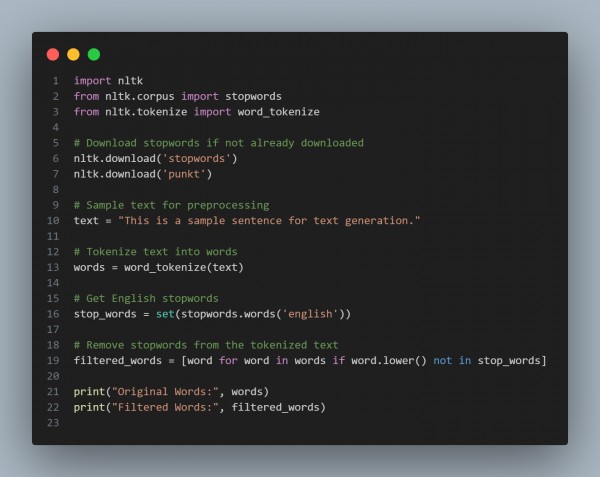
In the above code, we are using the following:
- Tokenize Text: Use word_tokenize to break the text into words.
- Get Stopwords: Use NLTK's stopwords.words('english') to get a list of common stopwords.
- Filter Stopwords: Remove stopwords from the tokenized words list to retain only meaningful words for training.
Hence, by removing stopwords, your model can focus on the more relevant parts of the text, improving the quality and accuracy of generated content.
 REGISTER FOR FREE WEBINAR
X
REGISTER FOR FREE WEBINAR
X
 Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
























