
Informatica Certification Training Course
- 22k Enrolled Learners
- Weekend/Weekday
- Live Class
(8700)





 Copy Link!
Copy Link!The recent tech market has seen a lot of revolution and changes taking place. It is no more a news that popularity of open source software has shot up with the growing interest in big data and analytics. Among all the open source ETL software present in the market, Talend is quite popularly used. As already discussed, Talend provides various open source integration software and services for big data, cloud storage, data integration etc. In this Talend Big Data Tutorial blog, I will talk all about how you can use Talend with various Big Data technologies like HDFS, Hive, Pig etc. You can get a better understanding of the concepts from the Hadoop Training.
Following are the topics that I will be discussing in this Talend Big Data Tutorial blog:
To get a better idea of how Talend works with big data, let’s start with the basics of big data itself. You may also go through this recording of Talend Big Data Tutorial where our Talend Training experts have explained the topics in a detailed manner with examples.
Talend Big Data Tutorial | Edureka
Big Data is the data sets that are extremely large and complex and can’t be processed using any conventional data management tool. These huge sets of data can be present in structured, semi-structured or unstructured format. These are generally the streams of data which can be composed of auto-generated reports, logs, results of customer behavior analysis or combination of various data sources. Following diagram shows the main features of Big Data. They are more popularly known as the 5 V’s of Big Data.
To analyze this kind of humongous data sets you need the distributed computing power of more than thousand computers which can parallelly analyze this data and store the results centrally. Hadoop, an open source software framework, fulfills this requirement perfectly. It is a distributed file system which splits up the gathered information into a number of data blocks which are in turn distributed across multiple systems on the network. It provides an enormous storage for almost all data types, immense processing ability along with the power of handling virtually limitless tasks or jobs executing simultaneously.
In the next section of this Talend Big Data Tutorial blog, I will be talking about how you can use big data and Talend together.
Talend Open Studio (TOS) for big data is built on the top of Talend’s data integration solutions. It is an open source software and provides an easy to use graphical development environment to the users. It is a powerful tool which leverages the Apache Hadoop Big Data platform and helps users to access, transform, move and synchronize the big data. It makes the user’s interaction with big data sources and other targets really simple as they don’t have to learn or write any complicated code to work with it.
All you need to do is configure the big data connection and then perform simple drag and drop. The Talend Open Studio (TOS) for Big Data, at the back end, will automatically generate the underlying code. Now you can easily deploy them as a service or stand-alone Job which natively runs on the big data cluster like HDFS, Hive, Pig etc. The best way to become a Data Engineer is by getting Microsoft Azure Data Engineering Certification Course (DP-203).
Following is a pictorial representation of the functional architecture of Talend big data.

But, before I introduce Talend Open Studio, let me first explain a little about HDFS and MapReduce and how they work without Talend.
Hadoop, as mentioned is a powerful tool for handling Big Data. But have you wondered how it manages to handle these huge datasets? Well, Hadoop is powered by two of its core modules which handle the big data quite efficiently. They are:
Get further details about Big Data from the Hadoop training in Atlanta.
Let’s talk about them one by one:
HDFS is the file management system of Hadoop platform which is used to store data across multiple servers in a cluster. In this, the datasets are broken down into a number of blocks and are distributed across various nodes throughout the cluster. On top of it, to maintain the data durability, HDFS keeps replications of these data blocks in various nodes. Thus, in case, one node fails, other live nodes will still hold a copy of the data block.
MapReduce is a data processing framework of Hadoop. It is used to create applications which can take advantage of the different files stored in a distributed environment such as HDFS. A MapReduce application mainly has two functions which run as tasks on various nodes in a cluster. Those two functions are:
Let’s see a simple example of how we can extract the unique values from a file using HDFS and MapReduce:
Here we have a text file in which some words are repeated.
Using MapReduce we will try to count the number of times those words appear in the file and store the output in a new file. For this, you need to have good knowledge of Java programming language.
package co.edureka.mapreduce;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.fs.Path;
public class WordCount
{
public static class Map extends Mapper<LongWritable,Text,Text,IntWritable> {
public void map(LongWritable key, Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
value.set(tokenizer.nextToken());
context.write(value, new IntWritable(1));
}
}
}
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException,InterruptedException {
int sum=0;
for(IntWritable x: values)
{
sum+=x.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf= new Configuration();
Job job = new Job(conf,"Counting Unique Words In A File");
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(args[1]);
//Configuring the input/output path from the filesystem into the job
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//deleting the output path automatically from hdfs so that we don't have to delete it explicitly
outputPath.getFileSystem(conf).delete(outputPath);
//exiting the job only if the flag value becomes false
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}Woohh!! Now that's a lot of coding you have to do. Especially if you are not familiar with coding, it can become a big headache. Also, it will take a lot of effort and time in coding and debugging this program. But no need to worry! Talend can save you from writing all this code and make your work much easier as you only need to drag and drop the components in the Talend's workspace. At the backend, Talend will automatically generate this code for you. But for this, you need to have Talend for Big Data installed.
In the next section of this blog on Talend Big Data Tutorial, I will show a step by step installation of TOS for BD.
STEP 1: Go to https://www.talend.com/products/talend-open-studio.
STEP 2: Click on ‘Download Free Tool’.
 STEP 3: If the download doesn't start, click on 'Restart download'.
STEP 3: If the download doesn't start, click on 'Restart download'.
 STEP 4: Now extract the zip file.
STEP 4: Now extract the zip file.
 STEP 5: Now go into the extracted folder and double-click on the TOS_BD-linux-gtk-x86_64 file.
STEP 5: Now go into the extracted folder and double-click on the TOS_BD-linux-gtk-x86_64 file.
 STEP 6: Let the installation finish.
STEP 6: Let the installation finish.
 STEP 7: Click on ‘Create a new project’ and specify a meaningful name for your project.
STEP 7: Click on ‘Create a new project’ and specify a meaningful name for your project.
 STEP 8: Click on ‘Finish’ to go to the Open Studio GUI.
STEP 8: Click on ‘Finish’ to go to the Open Studio GUI.
STEP 9: Right-click on the Welcome tab and select ‘Close’.

STEP 10: Now you should be able to see the TOS main page.

Talend provides a wide range of components, which you can use to interact with HDFS and MapReduce.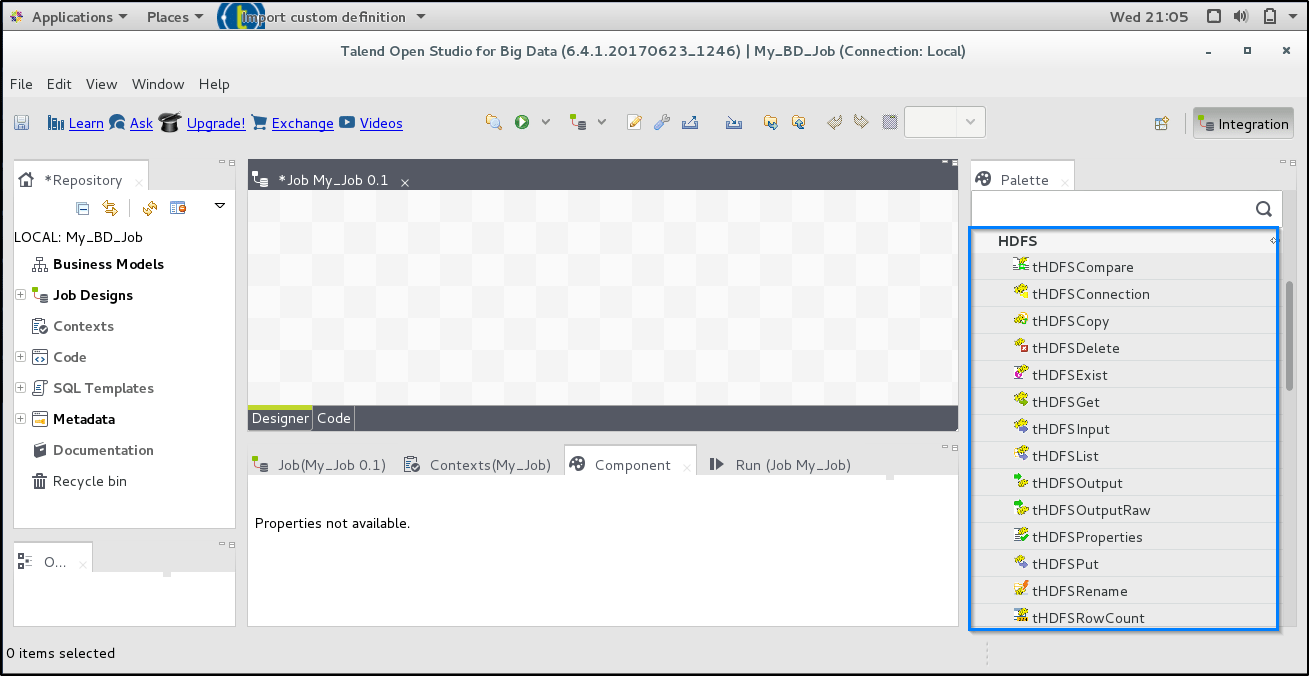
In this Talend big data tutorial blog, I will explain the most important components belonging to the Big Data family: You can even check out the details of Big Data with the DP 203 Certification Course.
Now let us try to execute the same program using Talend and see how Talend helps in executing this program easily.
STEP 1: Open Talend Studio For Big Data and create a new job.
STEP 2: Add tHDFSConnection Component and provide the necessary details in its component tab to set up the connection.
STEP 3: Now add a tHDFSPut component in order to upload your file on HDFS. Go to its component tab specify the necessary details as shown:
 STEP 4: Now add rest of the components and link them together as shown:
STEP 4: Now add rest of the components and link them together as shown:
 STEP 5: Go to the component tab of tHDFSInput component and enter the required details.
STEP 5: Go to the component tab of tHDFSInput component and enter the required details.

STEP 6: In the component tab of tNormalize component, specify the details as shown:
STEP 7: Go to the component tab of tAggregate component provide the details as shown:

STEP 8: Double-click on the tMap component and in the pop-up window, map the input table with the required output table as shown:

STEP 9: In the component tab of the tHDFSOutput component specify the required details.

STEP 10: From the Run tab, click on run to execute the job. A successfully executed job will look like below:
STEP 11: It will give you the output on HDFS:

So, this brings us to the end of this blog on Talend Big Data Tutorial. I tried my best to keep the concepts short and clear. Hope it helped you in understanding Talend and how it works with big data.
Now that you are through with this blog, check out the Hadoop training in Chicago by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe.
Got a question for us? Please mention it in the comments section and we will get back to you.































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


Hi,
I was not getting the “hHiveOutput” component. Can you tell where did you find it ?
Thank you very much for this article
Hey Imen, thank you for appreciating our efforts! :)