
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!Spark MLlib is Apache Spark’s Machine Learning component. One of the major attractions of Spark is the ability to scale computation massively, and that is exactly what you need for machine learning algorithms. But the limitation is that all machine learning algorithms cannot be effectively parallelized. Each algorithm has its own challenges for parallelization, whether it is task parallelism or data parallelism.
Having said that, Spark is becoming the de-facto platform for building machine learning algorithms and applications. Well, you can check out the Spark course curriculum curated by Industry Experts before going ahead with the blog. The developers working on the Spark MLlib are implementing more and more machine algorithms in a scalable and concise manner in the Spark framework. Through this blog, we will learn the concepts of Machine Learning, Spark MLlib, its utilities, algorithms and a complete use case of Movie Recommendation System.
Evolved from the study of pattern recognition and computational learning theory in artificial intelligence, machine learning explores the study and construction of algorithms that can learn from and make predictions on data – such algorithms overcome following strictly static program instructions by making data-driven predictions or decisions, through building a model from sample inputs.
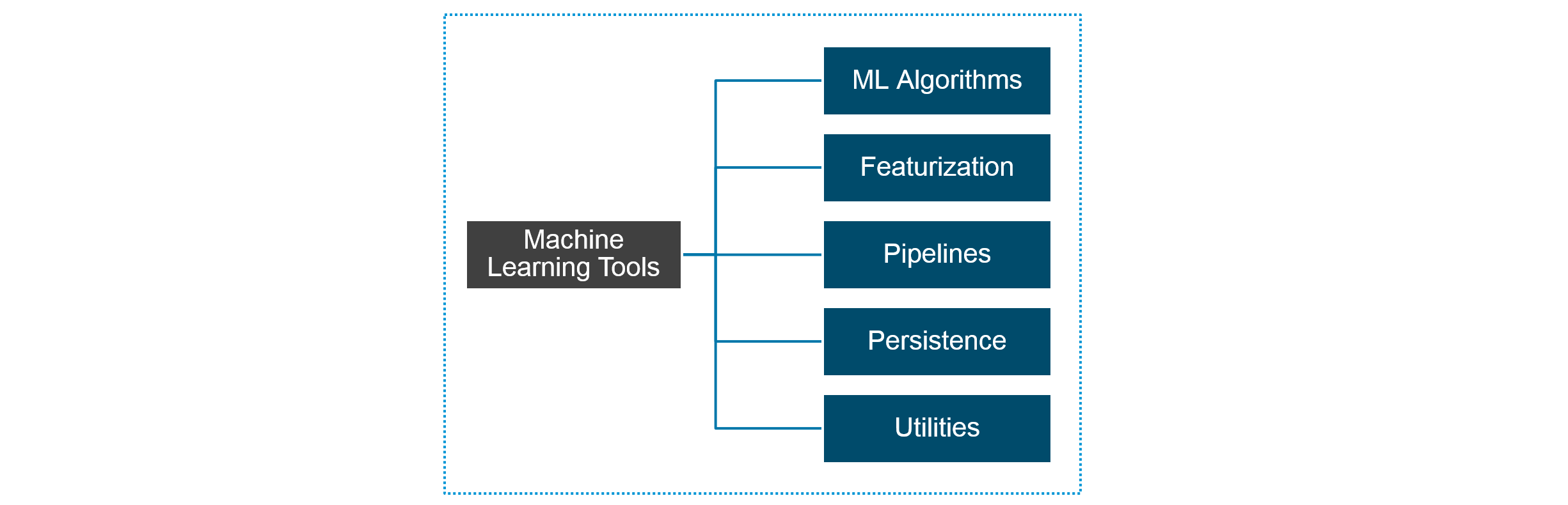 Figure: Machine Learning tools
Figure: Machine Learning tools
Machine learning is closely related to computational statistics, which also focuses on prediction-making through the use of computers. It has strong ties to mathematical optimization, which delivers methods, theory and application domains to the field. Within the field of data analytics, machine learning is a method used to devise complex models and algorithms that lend themselves to a prediction which in commercial use is known as predictive analytics.
There are three categories of Machine learning tasks:
Spark MLlib is used to perform machine learning in Apache Spark. MLlib consists popular algorithms and utilities.
MLlib Overview:
Spark MLlib provides the following tools:
The popular algorithms and utilities in Spark MLlib are:
Let us look at some of these in detail.
Basic Statistics includes the most basic of machine learning techniques. These include:
Regression analysis is a statistical process for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables when the focus is on the relationship between a dependent variable and one or more independent variables. More specifically, regression analysis helps one understand how the typical value of the dependent variable changes when any one of the independent variables is varied, while the other independent variables are held fixed.
 Regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning. Regression analysis is also used to understand which among the independent variables are related to the dependent variable, and to explore the forms of these relationships. In restricted circumstances, regression analysis can be used to infer causal relationships between the independent and dependent variables.
Regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning. Regression analysis is also used to understand which among the independent variables are related to the dependent variable, and to explore the forms of these relationships. In restricted circumstances, regression analysis can be used to infer causal relationships between the independent and dependent variables.
Classification is the problem of identifying to which of a set of categories (sub-populations) a new observation belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known. It is an example of pattern recognition.
Here, an example would be assigning a given email into “spam” or “non-spam” classes or assigning a diagnosis to a given patient as described by observed characteristics of the patient (gender, blood pressure, presence or absence of certain symptoms, etc.).
A recommendation system is a subclass of information filtering system that seeks to predict the “rating” or “preference” that a user would give to an item. Recommender systems have become increasingly popular in recent years, and are utilized in a variety of areas including movies, music, news, books, research articles, search queries, social tags, and products in general.
Recommender systems typically produce a list of recommendations in one of two ways – through collaborative and content-based filtering or the personality-based approach.
Further, these approaches are often combined as Hybrid Recommender Systems.
Clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters). So, it is the main task of exploratory data mining, and a common technique for statistical data analysis, used in many fields, including machine learning, pattern recognition, image analysis, information retrieval, bioinformatics, data compression and computer graphics.
Dimensionality Reduction is the process of reducing the number of random variables under consideration, via obtaining a set of principal variables. It can be divided into feature selection and feature extraction.
Feature Extraction starts from an initial set of measured data and builds derived values (features) intended to be informative and non-redundant, facilitating the subsequent learning and generalization steps, and in some cases leading to better human interpretations. This is related to dimensionality reduction.
Optimization is the selection of the best element (with regard to some criterion) from some set of available alternatives.
In the simplest case, an optimization problem consists of maximizing or minimizing a real function by systematically choosing input values from within an allowed set and computing the value of the function. The generalization of optimization theory and techniques to other formulations comprises a large area of applied mathematics. More generally, optimization includes finding “best available” values of some objective function given a defined domain (or input), including a variety of different types of objective functions and different types of domains.
Problem Statement: To build a Movie Recommendation System which recommends movies based on a user’s preferences using Apache Spark.
So, let us assess the requirements to build our movie recommendation system:
As we can assess our requirements, we need the best Big Data tool to process large data in short time. Therefore, Apache Spark is the perfect tool to implement our Movie Recommendation System.
Let us now look at the Flow Diagram for our system.
 As we can see, the following uses Streaming from Spark Streaming. We can stream in real time or read data from Hadoop HDFS.
As we can see, the following uses Streaming from Spark Streaming. We can stream in real time or read data from Hadoop HDFS.
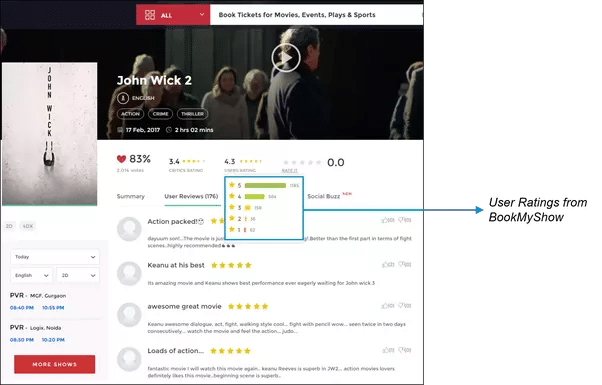
For our Movie Recommendation System, we can get user ratings from many popular websites like IMDB, Rotten Tomatoes and Times Movie Ratings. This dataset is available in many formats such as CSV files, text files and databases. We can either stream the data live from the websites or download and store them in our local file system or HDFS.

The below figure shows how we can collect dataset from popular websites.
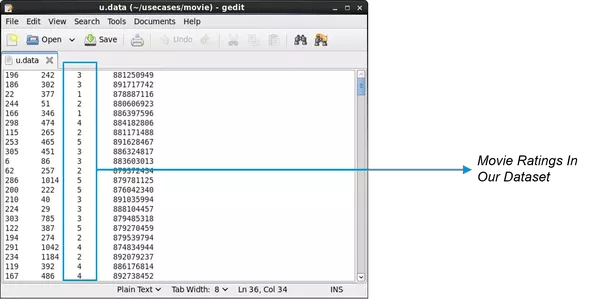
Once we stream the data into Spark, it looks somewhat like this.
The whole recommendation system is based on Machine Learning algorithm Alternating Least Squares. Here, ALS is a type of regression analysis where regression is used to draw a line amidst the data points in such a way so that the sum of the squares of the distance from each data point is minimized. Thus, this line is then used to predict the values of the function where it meets the value of the independent variable.
The blue line in the diagram is the best-fit regression line. For this line, the value of the dimension D is minimum. All other red lines will always be farther from the dataset as a whole.
Here is the pseudo code for our program:
import org.apache.spark.mllib.recommendation.ALS
import org.apache.spark.mllib.recommendation.Rating
import org.apache.spark.SparkConf
//Import other necessary packages
object Movie {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Movie").setMaster("local[2]")
val sc = new SparkContext(conf)
val rawData = sc.textFile(" *Read Data from Movie CSV file* ")
//rawData.first()
val rawRatings = rawData.map( *Split rawData on tab delimiter* )
val ratings = rawRatings.map { *Map case array of User, Movie and Rating* }
//Training the data
val model = ALS.train(ratings, 50, 5, 0.01)
model.userFeatures
model.userFeatures.count
model.productFeatures.count
val predictedRating = *Predict for User 789 for movie 123*
val userId = *User 789*
val K = 10
val topKRecs = model.recommendProducts( *Recommend for User for the particular value of K* )
println(topKRecs.mkString("
"))
val movies = sc.textFile(" *Read Movie List Data* ")
val titles = movies.map(line => line.split("|").take(2)).map(array => (array(0).toInt,array(1))).collectAsMap()
val titlesRDD = movies.map(line => line.split("|").take(2)).map(array => (array(0).toInt,array(1))).cache()
titles(123)
val moviesForUser = ratings.*Search for User 789*
val sqlContext= *Create SQL Context*
val moviesRecommended = sqlContext.*Make a DataFrame of recommended movies*
moviesRecommended.registerTempTable("moviesRecommendedTable")
sqlContext.sql("Select count(*) from moviesRecommendedTable").foreach(println)
moviesForUser. *Sort the ratings for User 789* .map( *Map the rating to movie title* ). *Print the rating*
val results = moviesForUser.sortBy(-_.rating).take(30).map(rating => (titles(rating.product), rating.rating))
}
}
Once we generate predictions, we can use Spark SQL to store the results into an RDBMS system. Further, this can be displayed on a web application.
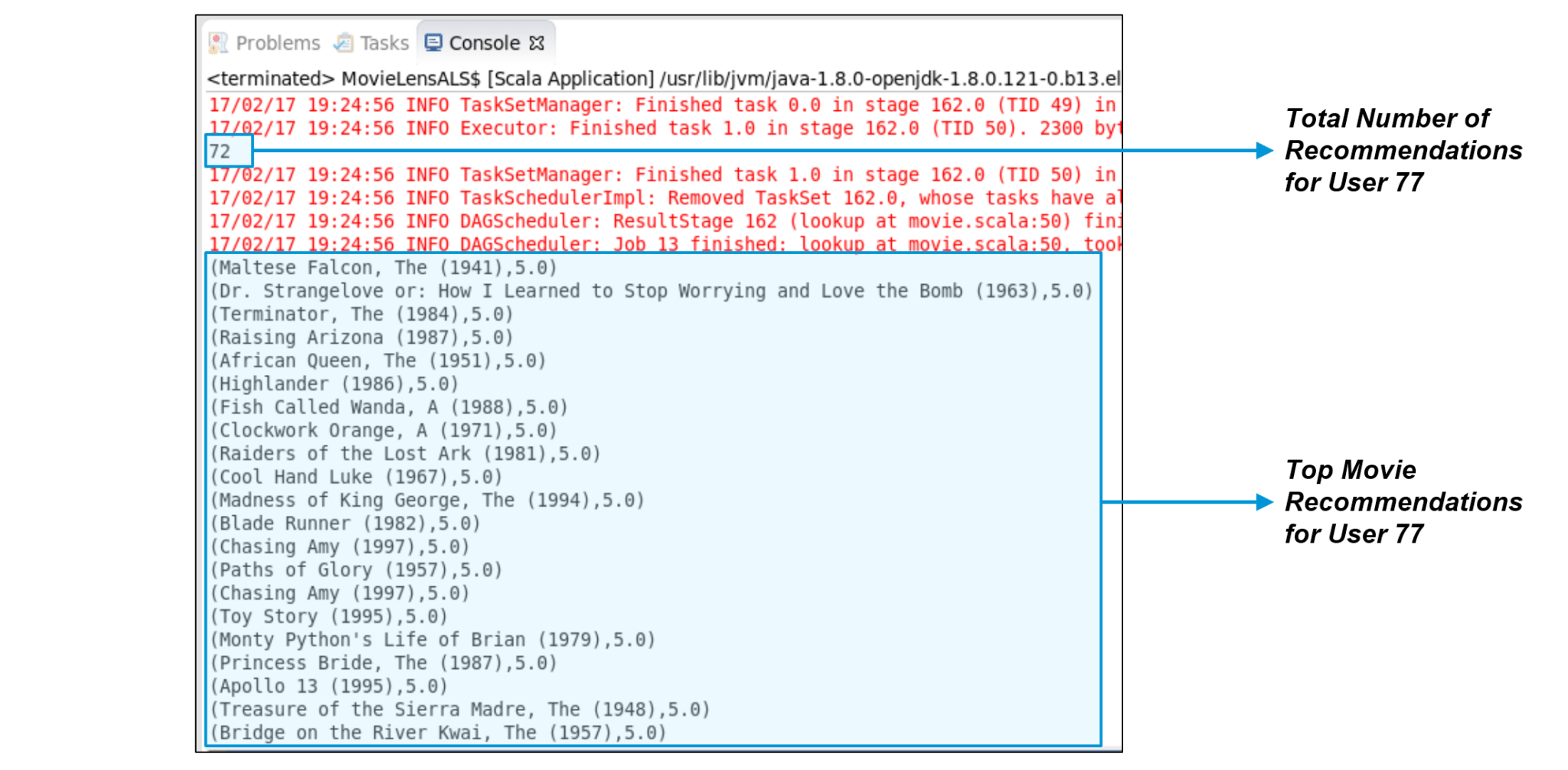 Figure: Movies recommended for User 77
Figure: Movies recommended for User 77
Hurray! We have thus successfully created a Movie Recommendation System using Apache Spark. With this, we have covered just one of the many popular algorithms Spark MLlib has to offer. We will learn more about Machine Learning in the upcoming blogs on Data Science Algorithms.
Taking forward, you can continue learning Apache Spark with Spark Tutorial, Spark Streaming Tutorial, and Spark Interview Questions. Edureka is dedicated towards providing the best learning experience possible online.
Do check out our Apache Spark Certification Training if you wish to learn Spark and build a career in the domain of Spark and build expertise to perform large-scale Data Processing using RDD, Spark Streaming, SparkSQL, MLlib, GraphX and Scala with real life use-cases.Upskill your data engineering skills with our Microsoft fabric certification Training course




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








Where you can download, the example data. But it is not possible to follow it.
I haven’t received source code yet. I submitted my response yesterday.
I haven’t received any email from edureka support regarding source code. I have submitted my response today morning.
Thank you for the effort. I’m trying to download the full code source but I don’t receive anything on my email
+Chaimae Ouedi, thanks for checking out our blog. We’re glad you liked it.
Our team sent out the emails yesterday. Hope you received it. Apologies about the delay.
Cheers!
I submitted a request to get this source code last week. When can I expect to receive it?