
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!Contributed by Prithviraj Bose
Here’s a blog on the stuff that you need to know about Spark accumulators. With Apache Spark Certification being a key skill that most IT recruiters hunt for, its growth and demand in the industry has been exponential since its inception.
Accumulators are variables that are used for aggregating information across the executors. For example, this information can pertain to data or API diagnosis like how many records are corrupted or how many times a particular library API was called.
To understand why we need accumulators, let’s see a small example.
Here’s an imaginary log of transactions of a chain of stores around the central Kolkata region.
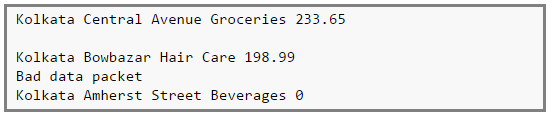
There are 4 fields,
Field 1 -> City
Field 2 -> Locality
Field 3 -> Category of item sold
Field 4 -> Value of item sold
However, the logs can be corrupted. For example, the second line is a blank line, the fourth line reports some network issues and finally the last line shows a sales value of zero (which cannot happen!).
We can use accumulators to analyse the transaction log to find out the number of blank logs (blank lines), number of times the network failed, any product that does not have a category or even number of times zero sales were recorded. The full sample log can be found here.
Accumulators are applicable to any operation which are,
1. Commutative -> f(x, y) = f(y, x), and
2. Associative -> f(f(x, y), z) = f(f(x, z), y) = f(f(y, z), x)
For example, sum and max functions satisfy the above conditions whereas average does not.
Now why do we need accumulators and why not just use variables as shown in the code below.


This guarantees that the accumulator blankLines is updated across every executor and the updates are relayed back to the driver.
We can implement other counters for network errors or zero sales value, etc. The full source code along with the implementation of the other counters can be found here.
People familiar with Hadoop Map-Reduce will notice that Spark’s accumulators are similar to Hadoop’s Map-Reduce counters.
When using accumulators there are some caveats that we as programmers need to be aware of,
To be on the safe side, always use accumulators inside actions ONLY.
The code here shows a simple yet effective example on how to achieve this.
For more information on accumulators, read this.
Got a question for us? Mention them in the comment section and we will get back to you.
Related Posts:





































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








https://spark.apache.org/docs/2.3.0/streaming-kafka-0-8-integration.html .
In this documentation there is a datastructure created which conflicts the original thought variables cannot be updated across executors and drivers.
AtomicReference offsetRanges = new AtomicReference<>(); directKafkaStream.transformToPair(rdd -> { OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges(); offsetRanges.set(offsets); return rdd;
}).map(
...
).foreachRDD(rdd -> { for (OffsetRange o : offsetRanges.get()) {
System.out.println(
o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset()
); } ...
});
System.out.println(Arrays.toString(offsetRanges.get()));
I have added a print statement after the narrow transformations so that statement gets exceuted on the driver.
By your logic when I print it in the end i should get empty value as none of the offsets are updated back to the driver. But that is not the case.