






Multi Node Cluster in Hadoop 2.x
From our previous blog in Hadoop Tutorial Series, we learnt how to setup a Hadoop Single Node Cluster. Now, I will show how to set up a Hadoop Multi Node Cluster. A Multi Node Cluster in Hadoop contains two or more DataNodes in a distributed Hadoop environment. This is practically used in organizations to store and analyze their Petabytes and Exabytes of data. Learning to set up a multi node cluster gears you closer to your much needed Hadoop certification.
Here, we are taking two machines – master and slave. On both the machines, a Datanode will be running.
Let us start with the setup of Multi Node Cluster in Hadoop.
Prerequisites
- Cent OS 6.5
- Hadoop-2.7.3
- JAVA 8
- SSH
Setup of Multi Node Cluster in Hadoop
We have two machines (master and slave) with IP:
Master IP: 192.168.56.102
Slave IP: 192.168.56.103
STEP 1: Check the IP address of all machines.
Command: ip addr show (you can use the ifconfig command as well)


STEP 2: Disable the firewall restrictions.
Command: service iptables stop
Command: sudo chkconfig iptables off

STEP 3: Open hosts file to add master and data node with their respective IP addresses.
Command: sudo nano /etc/hosts
Same properties will be displayed in the master and slave hosts files.

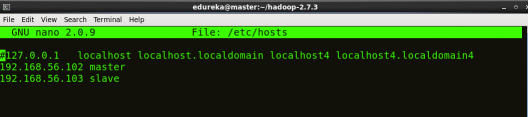
STEP 4: Restart the sshd service.
Command: service sshd restart

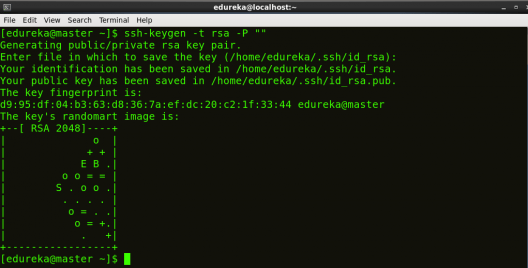
STEP 5: Create the SSH Key in the master node. (Press enter button when it asks you to enter a filename to save the key).
Command: ssh-keygen -t rsa -P “”
STEP 6: Copy the generated ssh key to master node’s authorized keys.
Command: cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

STEP 7: Copy the master node’s ssh key to slave’s authorized keys.
Command: ssh-copy-id -i $HOME/.ssh/id_rsa.pub edureka@slave

STEP 8: Click here to download the Java 8 Package. Save this file in your home directory.
STEP 9: Extract the Java Tar File on all nodes.
Command: tar -xvf jdk-8u101-linux-i586.tar.gz

STEP 10: Download the Hadoop 2.7.3 Package on all nodes.
Command: wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz

STEP 11: Extract the Hadoop tar File on all nodes.
Command: tar -xvf hadoop-2.7.3.tar.gz

STEP 12: Add the Hadoop and Java paths in the bash file (.bashrc) on all nodes.
Open. bashrc file. Now, add Hadoop and Java Path as shown below:
Command: sudo gedit .bashrc

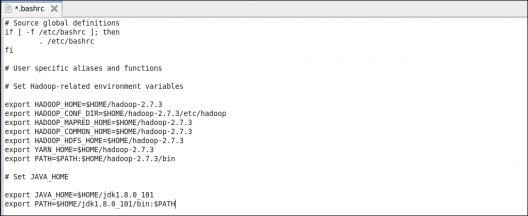
Then, save the bash file and close it.
For applying all these changes to the current Terminal, execute the source command.
Command: source .bashrc

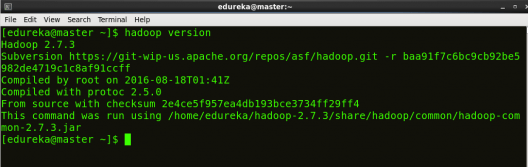
To make sure that Java and Hadoop have been properly installed on your system and can be accessed through the Terminal, execute the java -version and hadoop version commands.
Command: java -version

Command: hadoop version
Now edit the configuration files in hadoop-2.7.3/etc/hadoop directory.
STEP 13: Create masters file and edit as follows in both master and slave machines as below:
Command: sudo gedit masters

STEP 14: Edit slaves file in master machine as follows:
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/slaves

STEP 15: Edit slaves file in slave machine as follows:
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/slaves

STEP 16: Edit core-site.xml on both master and slave machines as follows:
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/core-site.xml

STEP 7: Edit hdfs-site.xml on master as follows:
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/hdfs-site.xml

STEP 18: Edit hdfs-site.xml on slave machine as follows:
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
STEP 19: Copy mapred-site from the template in configuration folder and the edit mapred-site.xml on both master and slave machines as follows:
Command: cp mapred-site.xml.template mapred-site.xml
Command: sudo gedit /home/edureka/hadoop-2.7.3/etc/hadoop/mapred-site.xml


STEP 21: Format the namenode (Only on master machine).
Command: hadoop namenode -format

STEP 22: Start all daemons (Only on master machine).
Command: ./sbin/start-all.sh

STEP 23: Check all the daemons running on both master and slave machines.
Command: jps
On master

On slave

At last, open the browser and go to master:50070/dfshealth.html on your master machine, this will give you the NameNode interface. Scroll down and see for the number of live nodes, if its 2, you have successfully setup a multi node Hadoop cluster. In case, it’s not 2, you might have missed out any of the steps which I have mentioned above. But no need to worry, you can go back and verify all the configurations again to find the issues and then correct them.
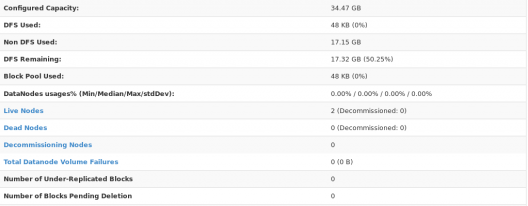
Here, we have only 2 DataNodes. If you want, you can add more DataNodes according to your needs, refer our blog on Commissioning and Decommissioning Nodes in a Hadoop Cluster.
I hope you would have successfully installed a Hadoop Multi Node Cluster. If you are facing any problem, you can comment below, we will be replying shortly. In our next blog of Hadoop Tutorial Series, you will learn some important HDFS commands and you can start playing with Hadoop.
Now that you have understood how to install Hadoop Multi Node Cluster, check out the Hadoop training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka’s Big Data Engineering Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.








































Permission denied (publickey,password).
I’m getting this error again and again. I don’t know where to get that password for slave from.
this below command is not working…
./sbin/start-all.sh
try bash start-all.sh
when jps command is typed then i cant see other connections.
it only shows jps.
i also cant run this command given below
cp mapred-site.xml.template mapred-site.xml.
plz help me out..
Hai everyone,i have windows 10 pro and i installed hadoop but i getting this error “Error: JAVA_HOME is incorrectly set.
Please update E:hadoop-2.8.1etchadoophadoop-env.cmd
‘-Xmx512m’ is not recognized as an internal or external command,
operable program or batch file”
can anyone plz help me.
Hello,
I have four nodes, all setting is according to the tutorial as mentioned above. But, My master node is working but slave nodes are not running. error is given below:
node-two: datanode running as process 2387. Stop it first.
node-three: datanode running as process 2387. Stop it first.
node-four: datanode running as process 2387. Stop it first.
Kindly anybody help me out. Thanks in Advance
Thanks Mr. Sinha, I have setup a single node cluster. But each time i try to run my jar file, I get “Waiting, RM needs to allocate resource to AM”, then the job hangs and cant move further. Please help
hello i have same issue .. can u help me … if u resolved the issue .. kindly ping me .. 7838054527
I reinstalled the hadoop. I was using Hadoop-2.7.4 and later
reinstalled Hadoop-2.8.2. I also changed the installation path to
reflect the new version of hadoop i.e.: changed :
“/usr/local/hadoop/hadoop-2.7.4/etc/hadoop” to this “/usr/local/hadoop/hadoop-2.8.2/etc/hadoop” , to avoid any conflict. This solves the problem for me.
Hey Abbey! That is indeed what you need to do fix the resource allocation problem. Let us know if you have any other query.
@EdurekaSupport:disqus , Hi I have an issue when trying to run a mapreduce Jar file using HIPI and Opencv. How do I resolve this. The error message is as follows:
/MyWorkSpace/MapReduceWorkSpace$ hadoop jar ImageCountProjJob2.jar FaceCount TestImage.hib FacecountoutputX
Exception in thread “main” java.lang.NoClassDefFoundError: hipi/imagebundle/mapreduce/ImageBundleInputFormat
at FaceCount.run(FaceCount.java:155)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:90)
at FaceCount.main(FaceCount.java:186)
Thanks Mr. Sinha. Very useful tutorial. My issue is resolved. Need to set permissions 644 and 700 respectively on .ssh and authorized_keys folder.
Also went through haddop.apache.org -> hadoop cluster setup to change “dfs.permissions” -> “dfs.permissions.enabled” as true