
Data Science and Machine Learning Internship ...
- 22k Enrolled Learners
- Weekend/Weekday
- Live Class
(8500)





 Copy Link!
Copy Link!Regular Expressions can be used to search, edit and manipulate text. This opens up a vast variety of applications in all of the sub-domains under Python. Python RegEx is widely used by almost all of the startups and has good industry traction for their applications as well as making Regular Expressions an asset for the modern day programmer.
To get in-depth knowledge on Python along with its various applications, you can enroll now for the best Python course online training with 24/7 support and lifetime access.
In this Python RegEx blog, we will be checking out the following concepts:
To answer this question, we will look at the various problems faced by us which in turn is solved by using Regular Expressions.
Consider the following scenario:
You have a log file which contains a large sum of data. And from this log file, you wish to fetch only the date and time. As you can look at the image, readability of the log file is low upon first glance.

Regular Expressions can be used in this case to recognize the patterns and extract the required information easily.
Consider the next scenario – You are a salesperson and you have a lot of email addresses and a lot of those addresses are fake/invalid. Check out the image below:

What you can do is, you can make use of Regular Expressions you can verify the format of the email addresses and filter out the fake IDs from the genuine ones.
The next scenario is pretty similar to the one with the salesperson example. Consider the following image:

How do we verify the phone number and then classify it based on the country of origin?
Every correct number will have a particular pattern which can be traced and followed through by using Regular Expressions.
Next up is another simple scenario:

We have a Student Database containing details such as name, age, and address. Consider the case where the Area code was originally 59006 but now has been changed to 59076. To manually update this for each student would be time-consuming and a very lengthy process.
Basically, to solve these using Regular Expressions, we first find a particular string from the student data containing the pin code and later replace all of them with the new ones.
Regular expressions can be used with multiple languages. Such as:
There is other ‘n’ number of scenarios in which Regular Expressions help us. I will be walking you through the same in the upcoming sections of this Python RegEx blog.
So, next up on this Python RegEx blog, let us look at what Regular Expressions actually are.
A Regular Expression is used for identifying a search pattern in a text string. It also helps in finding out the correctness of the data and even operations such as finding, replacing and formatting the data is possible using Regular Expressions.
Consider the following example:
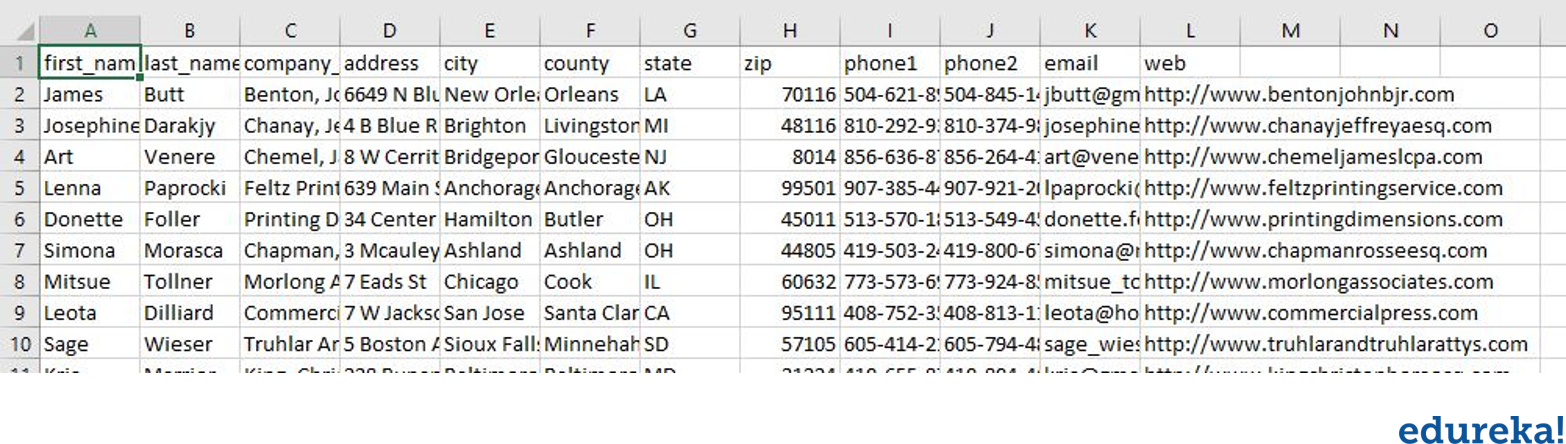
Among all of the data from the given string, let us say we require only the City. This can be converted into a dictionary with just the name and the city in a formatted way. The question now is that, can we identify a pattern to guess the name and the city? Also, we can find out the age too. With age, it is easy, right? it is just an integer number.
How do we go about with the name? If you take a look at the pattern, all of the names start with an uppercase. With the help of the Regular expressions, we can identify both the name and the age using this method.
Consider the following code:
import re
Nameage = '''
Janice is 22 and Theon is 33
Gabriel is 44 and Joey is 21
'''
ages = re.findall(r'd{1,3}', Nameage)
names = re.findall(r'[A-Z][a-z]*',Nameage)
ageDict = {}
x = 0
for eachname in names
ageDict[eachname] = ages[x]
x+=1
print(ageDict)
There is no need to worry about the syntax at this point of time but since Python has amazing readability, you could very well guess what is happening the Regular Expression part of the code.
{'Janice': '22', 'Theon': '33', 'Gabriel': '44', 'Joey': '21'}Next up on this Python RegEx blog, let us check out all the operations we can perform using Regular Expressions.
There are many operations you can perform by making use of Regular Expressions. Here, I have listed a few which are very vital in helping you understand the usage of Regular Expressions better.
Let us begin this Python RegEx blog by first checking out how we can find a particular word in a string.
Finding a word in the string:
Consider the following piece of code:
import re
if re.search("inform","we need to inform him with the latest information"):
print("There is inform")
All we are doing here to search if the word inform exists in our search string. And if it does, then we get an output saying There is inform.
We can up this a little bit by writing a method which will do a similar thing.
import re
allinform = re.findall("inform","We need to inform him with the latest information!")
for i in allinform:
print(i)
Here, in this particular case inform will be found twice. One from the inform and the other from the information.
And it is as simple as this to find a word in a Regular Expression as shown above.
Next up on this Python RegEx blog, we will check out how we can generate an iterator using Regular Expressions.
Generating an iterator:
Generating an iterator is the simple process of finding out and reporting the starting and the ending index of the string. Consider the following example:
import re
Str = "we need to inform him with the latest information"
for i in re.finditer("inform.", Str):
locTuple = i.span()
print(locTuple)
For every match found, the starting and the ending index is printed. Can you take a guess of the output that we get when we execute the above program? Check it out below.
Output:
(11, 18) (38, 45)
Pretty simple, right?
Next up on this Python RegEx blog, we will be checking out how we can match words with patterns using Regular Expressions.
Matching words with patterns:
Consider an input string where you have to match certain words with the string. To elaborate, check out the following example code:
import re
Str = "Sat, hat, mat, pat"
allStr = re.findall("[shmp]at", Str)
for i in allStr:
print(i)
What is common in the string? You can see that the letters ‘a’ and ‘t’ are common among all of the input strings. [shmp] in the code denotes the starting letter of the words to be found. So any substring starting with the letters s, h, m or p will be considered for matching. Any among that and compulsorily followed by ‘at’ at the end.
Output:
hat mat pat
Do note that they are all case sensitive. Regular expressions have amazing readability. Once you get to know the basics, you can start working on them in full swing and it’s pretty much easy, right?
Next up on this Python RegEx blog, we will be checking out how we can match a range of characters at once using Regular Expressions.
Matching series of range of characters:
We wish to output all the words whose first letter should start in between h and m and compulsorily followed by at. Checking out the following example we should realize the output we should get is hat and mat, correct?
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[h-m]at", Str)
for i in someStr:
print(i)
Output:
hat mat
Let us now change the above program very slightly to obtain a very different result. Check out the below code and try to catch the difference between the above one and the below one:
import re
Str = "sat, hat, mat, pat"
someStr = re.findall("[^h-m]at", Str)
for i in someStr:
print(i)
Found the subtle difference? We have added a caret symbol(^) in the Regular Expression. What this does it negates the effect of whatever it follows. Instead of giving us the output of everything starting with h to m, we will be presented with the output of everything apart from that.
The output we can expect is words which are NOT starting with letters in between h and m but still followed by at the last.
Output:
sat pat
Next up on this Python RegEx blog, I will explain how we can replace a string using Regular Expressions.
Replacing a string:
Next up, we can check out another operation using Regular Expressions where we replace an item of the string with something else. It is very simple and can be illustrated with the following piece of code:
import re
Food = "hat rat mat pat"
regex = re.compile("[r]at")
Food = regex.sub("food", Food)
print(Food)
In the above example, the word rat is replaced with the word food. The final output will look like this. The substitute method of the Regular Expressions is made use of this case and it has a vast variety of practical use cases as well.
Output:
hat food mat pat
Next up on this Python RegEx blog, we will check out a unique problem to Python called the Python Backslash problem.
The Backslash Problem:
Consider an example code shown below:
import re randstr = "Here is Edureka" print(randstr)
Output:
Here is Edureka
This is the backslash problem. One of the slashes vanished from the output. This particular problem can be fixed using Regular Expressions.
import re randstr = "Here is Edureka" print(re.search(r"Edureka", randstr))
The output can be as follows:
<re.Match object; span=(8, 16), match='Edureka'>
As you can check out, the match for the double slashes has been found. And this is how simple it is to solve the backslash problem using Regular Expressions.
Next up on this Python RegEx blog, I will walk you through how we can match a single character using Regular Expressions.
Matching a single character:
A single character from a string can be individually matched using Regular Expressions easily. Check out the following code snippet:
import re
randstr = "12345"
print("Matches: ", len(re.findall("d{5}", randstr)))
The expected output is the 5th number that occurs in the given input string.
Output:
Matches: 1
Next up on this Python RegEx blog, I will walk you through how we can remove newline spaces using Regular Expressions.
Removing Newline Spaces:
We can remove the newline spaces using Regular Expressions easily in Python. Consider another snippet of code as shown here:
import re
randstr = '''
You Never
Walk Alone
Liverpool FC
'''
print(randstr)
regex = re.compile("
")
randstr = regex.sub(" ", randstr)
print(randstr)
Output:
You Never Walk Alone Liverpool FC You Never Walk Alone Liverpool FC
As you can check out from the above output, the new lines have been replaced with whitespace and the output is printed on a single line.
There are many other things you could use as well depending on what you want to replace the string with. They are listed as follows:
Consider another example as shown below:
import re
randstr = "12345"
print("Matches:", len(re.findall("d", randstr)))
Output:
Matches: 5
As you can see from the above output, d matches the integers present in the string. However if we replace it with D, it will match everything BUT an integer, the exact opposite of d.
Next up on this Python RegEx blog, let us walk through some important practical use-cases of making use of Regular Expressions in Python.
We will be checking out 3 main use-cases which are widely used on a daily basis. Following are the concepts we will be checking out:
Let us begin this section of Python RegEx tutorial by checking out the first case.
Phone Number Verification:
Problem Statement – The need to easily verify phone numbers in any relevant scenario.
Consider the following Phone numbers:
The general format of a phone number is as follows:
We will be using w in the example below. Note that w = [a-zA-Z0-9_]
import re
phn = "412-555-1212"
if re.search("w{3}-w{3}-w{4}", phn):
print("Valid phone number")
Output:
Valid phone number
E-mail Verification:
Problem statement – To verify the validity of an E-mail address in any scenario.
Consider the following examples of email addresses:
Manually, it just takes you one good glance to identify the valid mail IDs from the invalid ones. But how is the case when it comes to having our program do this for us? It is pretty simple considering the following guidelines are followed for this use-case.
Guidelines:
All E-mail addresses should include:
Code:
import re
email = "ac@aol.com md@.com @seo.com dc@.com"
print("Email Matches: ", len(re.findall("[w._%+-]{1,20}@[w.-]{2,20}.[A-Za-z]{2,3}", email)))
Output:
Email Matches: 1
As you can check out from the above output, we have one valid mail among the 4 emails which are the inputs.
This basically proves how simple and efficient it is to work with Regular Expressions and make use of them practically.
Web Scraping
Problem Statement – Scrapping all of the phone numbers from a website for a requirement.
To understand web scraping, check out the following diagram:

We already know that a single website will consist of multiple web pages. And let us say we need to scrape some information from these pages.
Web scraping is basically used to extract the information from the website. You can save the extracted information in the form of XML, CSV or even a MySQL database. This is achieved easily by making use of Python Regular Expressions.
import urllib.request
from re import findall
url = "http://www.summet.com/dmsi/html/codesamples/addresses.html"
response = urllib.request.urlopen(url)
html = response.read()
htmlStr = html.decode()
pdata = findall("(d{3}) d{3}-d{4}", htmlStr)
for item in pdata:
print(item)
Output:
(257) 563-7401 (372) 587-2335 (786) 713-8616 (793) 151-6230 (492) 709-6392 (654) 393-5734 (404) 960-3807 (314) 244-6306 (947) 278-5929 (684) 579-1879 (389) 737-2852 (660) 663-4518 (608) 265-2215 (959) 119-8364 (468) 353-2641 (248) 675-4007 (939) 353-1107 (570) 873-7090 (302) 259-2375 (717) 450-4729 (453) 391-4650 (559) 104-5475 (387) 142-9434 (516) 745-4496 (326) 677-3419 (746) 679-2470 (455) 430-0989 (490) 936-4694 (985) 834-8285 (662) 661-1446 (802) 668-8240 (477) 768-9247 (791) 239-9057 (832) 109-0213 (837) 196-3274 (268) 442-2428 (850) 676-5117 (861) 546-5032 (176) 805-4108 (715) 912-6931 (993) 554-0563 (357) 616-5411 (121) 347-0086 (304) 506-6314 (425) 288-2332 (145) 987-4962 (187) 582-9707 (750) 558-3965 (492) 467-3131 (774) 914-2510 (888) 106-8550 (539) 567-3573 (693) 337-2849 (545) 604-9386 (221) 156-5026 (414) 876-0865 (932) 726-8645 (726) 710-9826 (622) 594-1662 (948) 600-8503 (605) 900-7508 (716) 977-5775 (368) 239-8275 (725) 342-0650 (711) 993-5187 (882) 399-5084 (287) 755-9948 (659) 551-3389 (275) 730-6868 (725) 757-4047 (314) 882-1496 (639) 360-7590 (168) 222-1592 (896) 303-1164 (203) 982-6130 (906) 217-1470 (614) 514-1269 (763) 409-5446 (836) 292-5324 (926) 709-3295 (963) 356-9268 (736) 522-8584 (410) 483-0352 (252) 204-1434 (874) 886-4174 (581) 379-7573 (983) 632-8597 (295) 983-3476 (873) 392-8802 (360) 669-3923 (840) 987-9449 (422) 517-6053 (126) 940-2753 (427) 930-5255 (689) 721-5145 (676) 334-2174 (437) 994-5270 (564) 908-6970 (577) 333-6244 (655) 840-6139
We first being by importing the packages which are needed to perform the web scraping. And the final result comprises of the phone numbers extracted as a result of the web scraping done using Regular Expressions.
I hope this Python RegEx tutorial helps you in learning all the fundamentals needed to get started with using Regular Expressions in Python.
This will be very handy when you are trying to develop applications that require the usage of Regular Expressions and similar principles. Now, you should also be able to use these concepts to develop applications easily with the help of Regular Expressions and Web Scraping too.
After reading this blog on Python RegEx tutorial, I am pretty sure you want to know more about Python. To know more about Python you can refer the following blogs:
Got a question? Please mention it in the comments section of this “Python RegEx Tutorial” blog and I will get back to you as soon as possible.







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








I m not able to extract the all number from file get some numbers only please help.
File Link: http://py4e-data.dr-chuck.net/regex_sum_594709.txt
My Code:
import re
hand=open(‘/Users/apple/Downloads/regex_sum_594709.txt’)
numlist=list()
total=0
for line in hand:
line=line.rstrip()
stuff=re.findall(‘[0-9]+s’,line)
print(stuff)
if len(stuff)!=1:continue
for n in stuff:
num=int(n)
print(num)
numlist.append(num)
total=total+num
print(numlist)
print(total)
I m not