



Full Stack Web Development Internship Program
- 29k Enrolled Learners
- Weekend/Weekday
- Live Class
(11300)





 Copy Link!
Copy Link!The field of artificial intelligence (AI) is changing quickly, and DeepSeek AI is becoming a strong rival to OpenAI’s ChatGPT and other LLMs. But what makes DeepSeek AI work? How does its structure compare to other AI models? What makes it work well?
 In this blog, we will explore DeepSeek AI’s architecture, breaking down its neural network structure, training methodology, data handling, and optimization techniques. Let’s see DeepSeek Architecture.
In this blog, we will explore DeepSeek AI’s architecture, breaking down its neural network structure, training methodology, data handling, and optimization techniques. Let’s see DeepSeek Architecture.
DeepSeek AI’s Architecture
DeepSeek AI is built on a transformer-based architecture, similar to GPT (Generative Pre-trained Transformer) models. However, it integrates advanced optimizations to improve efficiency, scalability, and multilingual processing.
 Transformer-based deep learning model
Transformer-based deep learning modelDeepSeek AI uses the pre-training + fine-tuning method, which makes it useful for many things, such as natural language processing (NLP), code, business automation, and helping people speak more than one language.
Now, with that in mind, let us look at the Neural Network Architecture of DeepSeek
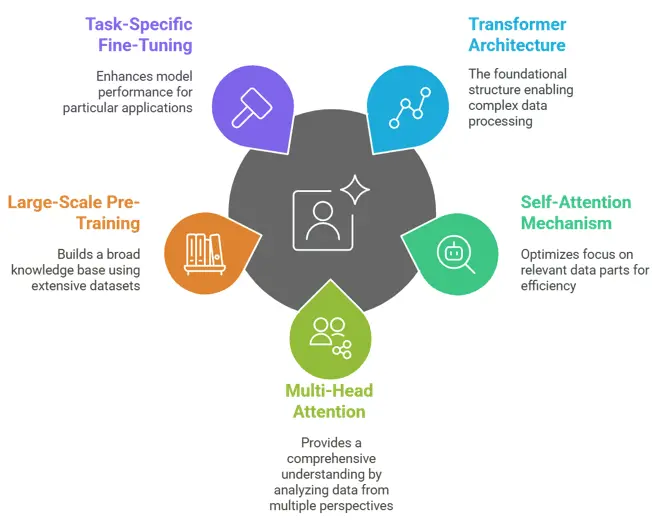
 Transformer-Based Model
Transformer-Based ModelDeepSeek AI follows the transformer model architecture, which consists of:
DeepSeek AI handles long-range relationships more quickly by using a better self-attention system. It finds the best attention weights while using less computing power than other transformers.
The model uses multi-head attention to pick up on different parts of a sentence’s meaning, which helps it understand the context better.
Like GPT-4, DeepSeek AI is trained on billions of parameters, enabling it to:
Now, let us also explore Training Methodologies
DeepSeek AI is pre-trained on a large-scale dataset, including:
This lets a lot of information be shown, which means the model can be used in many fields, languages, and industries.
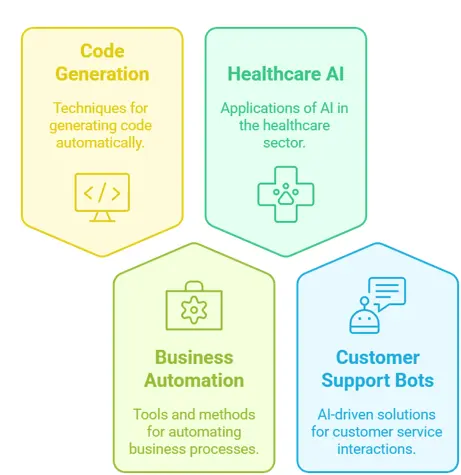
After pre-training, fine-tuning is applied using task-specific datasets. Fine-tuning allows DeepSeek AI to improve performance on domain-specific applications such as:
RLHF (Reinforcement Learning with Human Feedback) is used by DeepSeek AI to make sure that its answers are in line with what people want and with ethical AI rules.
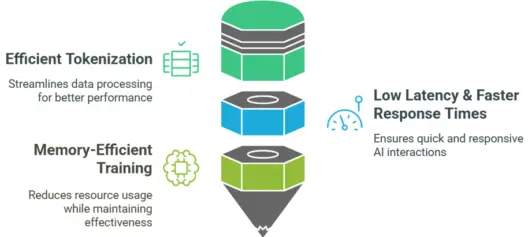
These techniques reduce training costs while improving model efficiency.
Now let us compare DeepSeek’s Architecture with Traditional AI
| Feature | DeepSeek AI | GPT-4 (ChatGPT) |
|---|---|---|
| Architecture | Transformer-based | Transformer-based |
| Self-Attention Optimization | Yes | Yes |
| Multi-Head Attention | Yes | Yes |
| Parameter Efficiency | Optimized | Large-scale but computationally expensive |
| Training Data | Diverse & multilingual | Primarily English, web-based |
| Speed & Latency | Faster | Moderate |
| Multimodal Capabilities | Limited | Supports text, images, and code |
With that in mind, let us look at the Applications of DeepSeek AI
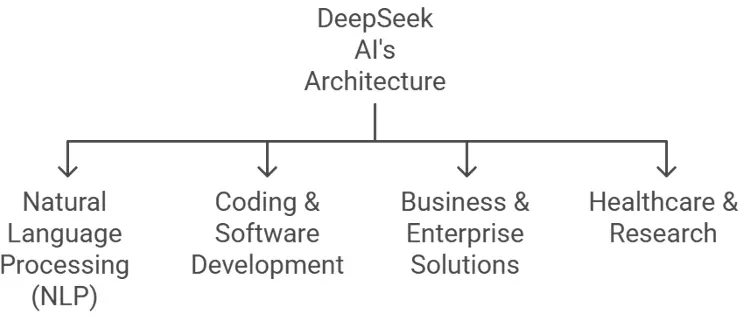 1. Natural Language Processing (NLP)
1. Natural Language Processing (NLP)Since we know, the applications let us look at the future improvements that can be made to improve this AI over time
Despite its powerful architecture, DeepSeek AI faces certain challenges, such as:
Future Enhancements:
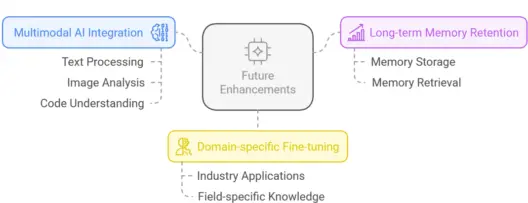
The DeepSeek AI model architecture is a strong, well-tuned transformer-based system made for quick responses, support for multiple languages, and better AI efficiency. DeepSeek AI is a great choice if you need an AI that works well and has low latency for international apps. GPT-4 is still a good option if you need AI that can work with writing, images, and code and can remember things for a long time.
Each type of AI has its own strengths, and DeepSeek AI is still changing, which makes it an interesting competitor in the AI field.
If you’re passionate about Artificial Intelligence, Machine Learning, and Generative AI, consider enrolling in Edureka’s Postgraduate Program in Generative AI and ML or their Generative AI Master’s Program. These courses provide comprehensive training, covering everything from fundamentals to advanced AI applications, equipping you with the skills needed to excel in the AI industry.
Additionally, we have created an in-depth video comparison of DeepSeek Training cost, breaking down their features, performance, and best use cases. Watch the video to get a detailed visual analysis of these two AI powerhouses!

Like GPT models, DeepSeek AI is based on a transformer-based design, but it has been tweaked for faster processing, support for multiple languages, and better training. For better performance, it has multi-head attention, better self-attention methods, and tokenization that works better.
Both models use transformer-based designs, but DeepSeek AI is more efficient and has lower latency, which makes it faster and better at using resources. GPT-4, on the other hand, can remember things for longer, use more than one mode of communication, and think more deeply about what they mean.
You can use big, multilingual datasets, DeepSeek AI uses a method called “pre-training + fine-tuning.” Reinforcement Learning with Human Feedback (RLHF) and gradient checkpointing are also used to make it more accurate and efficient.
Many people use DeepSeek AI for natural language processing (NLP), content creation, AI-powered code, business automation, and creating AI chatbots that can speak more than one language. Its design makes it perfect for AI apps that need to be fast and scalable.
Some problems are that it’s hard to remember things for a long time, it’s not possible to use more than one mode of communication (like making images), and it needs to be fine-tuned all the time to get better at everything. But these problems are being looked into right now in order to find solutions.



























