Embedding pooling improves Generative AI for document similarity tasks by aggregating token-level embeddings into a fixed-size vector, making comparisons efficient and robust.
Here is the code snippet you can refer to:
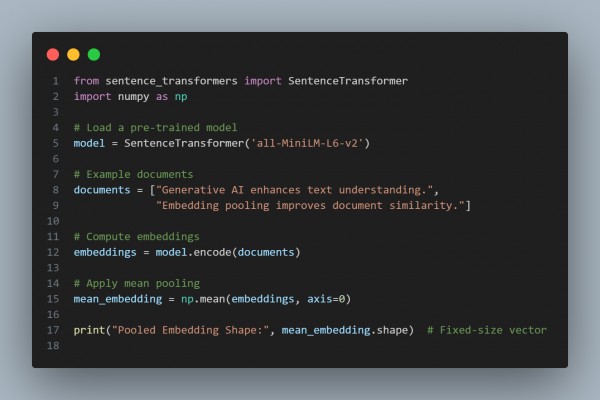
In the above code, we are using the following key points:
- Dimensionality Reduction: Converts variable-length text into a fixed-size vector.
- Improved Similarity Computation: Enables efficient cosine similarity or distance-based comparisons.
- Robustness: Reduces noise and captures essential semantic meaning.
- Scalability: Efficiently processes large-scale document sets.
Hence, by referring to the above, you can improve Generative AI for document similarity tasks
 REGISTER FOR FREE WEBINAR
X
REGISTER FOR FREE WEBINAR
X
 Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
Thank you for registering
Join Edureka Meetup community for 100+ Free Webinars each month
JOIN MEETUP GROUP
























