To adapt transformers for long-form text generation and mitigate context length limitations, you can follow the following steps:
- Efficient Attention Mechanisms: Replace standard attention with Longformer, BigBird, or Linformer to handle longer contexts efficiently.
- Chunking and Recurrence: Process text in smaller chunks, using recurrent mechanisms to pass context between chunks.
- Memory-Augmented Models: Incorporate memory to retain context across chunks, such as Retrieval-Augmented Generation (RAG) or Compressive Transformers.
- Hierarchical Models: Use hierarchical architectures to encode and generate text at multiple levels (sentence, paragraph).
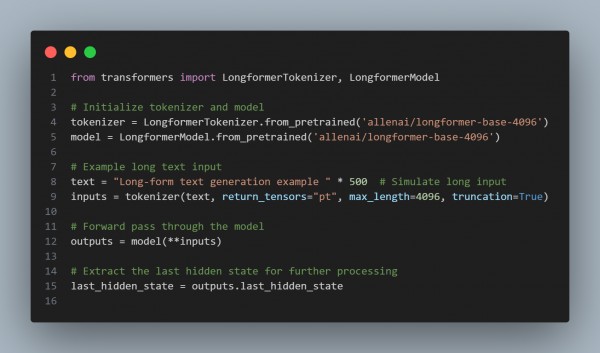
In the above code, we are using the following key points:
- Efficient Attention: Scales attention quadratically for local and sparse global attention.
- Chunk Processing: Allows processing long text in segments without losing important context.
- Memory-Augmented Approaches: Enables context persistence across segments.
- Pretrained Models: Use specialized models like Longformer for efficient long-context handling.
Hence, by referring to the above, you can adapt transformers for long-form text generation to reduce issues with context length limitation.
Related Post: long-form text generation using GPT