
Advanced Certification in Agentic AI Engineer ...
- 66k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!Among the most fascinating developments in natural language processing (NLP) and machine learning is zero-shot categorization. Simply said, it’s a model’s capacity to project classes it has never seen before during training.. In this blog, we will cover everything from what zero-shot classification is, how it works for images and popular models, and how you can implement it.
Zero-shot classification is the capacity of a model to categorize data into categories it has never been explicitly trained on. A language model trained on a range of text, for instance, can forecast the sentiment of a movie review without having ever seen a review labeled for sentiment during training. The model makes predictions on unseen tasks using a broad knowledge acquired during pre-training rather than needing labeled data for every conceivable class.
In situations when labeled data is limited or the work is very specialized, this capacity enables models to generalize across jobs without depending on particular training samples for every one, thereby saving a useful tool.
Now that we understand the core concept of zero-shot classification, let’s explore some real-world applications where it proves to be highly valuable.
Zero-shot classification has numerous applications, including:
Sentiment Analysis: Sentiment (positive or negative) prediction in text data without using labeled samples during training.
Text Classification: Without concrete examples for each of the preset categories—news, sports, politics, etc.—text documents are categorized into them.
Content Moderation: Automatically identifying improper or dangerous content in text or photos without human labeled samples for every kind of dangerous content.
Object Detection in Images: Identifying and classifying items in photos without teaching the model on any one object class.
Given the wide array of applications, it’s important to understand which models are best suited for zero-shot classification. Let’s dive into some popular models.
Some of the most popular models used for zero-shot classification are:
BART (Bidirectional and Auto-Regressive Transformers): A sequence-to- sequence model able to perform zero-shot learning and be customized for different NLP tasks.
GPT-3 (Generative Pretrained Transformer 3): Developed by OpenAI, GPT-3 can identify tasks and respond to prompts without particular training for every category.
CLIP (Contrastive Language–Image Pretraining): A multimodal model able to conduct zero-shot classification for images depending on textual descriptions and comprehend both images and text.
RoBERTa (Robustly Optimized BERT Pretraining Approach): Pre-trained on a lot of text data and fine-tuned for several tasks, including zero-shot classification, this variation of BERT
Now that we have an overview of the models, let’s move on to understanding how to use them for zero-shot classification tasks.
Using zero-shot classification models typically involves:
Input Preparation: Offering comments in the form of words, maybe a sentence or a picture’s description.
Model Inference: Based on its learnt knowledge during pre-training, the model produces predictions or classifications of the input..
Output Interpretation: Though certain classes were never included into the model’s training data, the model generates the most likely class or probability distribution over all feasible classes.
Here is an example using Hugging Face’s transformers library to perform zero-shot text classification:
</p>
from transformers import pipeline
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification")
# Sample text and candidate labels
text = "I love playing football on weekends!"
candidate_labels = ["sports", "politics", "technology", "entertainment"]
# Perform zero-shot classification
result = classifier(text, candidate_labels)
print(result)
Output will be:

With text classification covered, let’s now explore the exciting world of zero-shot image classification and how it works.
Zero-shot image classification is the grouping of a picture into categories without reference to particular training data for those categories. Usually, this is accomplished by teaching a model on both photos and verbal descriptions and leveraging their interaction to extend to other image categories.
To better understand how zero-shot image classification works, let’s break it down into a step-by-step process.
Zero-shot image classification uses models that comprehend both text and images, such as Contrastive Language-Image Pretraining, or CLIP. The model learns to link textual descriptions with visual aspects, so it can forecast the most likely textual description or category connected with an image when it detects an image.
For example, CLIP can classify an image of a dog as “dog” or “animal” based on the textual description of the image. It doesn’t need to have seen specific images of dogs during training but understands the relationship between the visual and textual features.
Let’s see how we can implement zero-shot image classification using the CLIP model in the next section.
Here’s an example of how to implement zero-shot image classification using the CLIP model from Hugging Face:
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
# Load the CLIP model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Load an image
image = Image.open("dog_image.jpg")
# Define candidate labels
labels = ["dog", "cat", "car", "tree"]
# Process the image and text inputs
inputs = processor(text=labels, images=image, return_tensors="pt", padding=True)
# Perform zero-shot image classification
outputs = model(**inputs)
# Get the logits for each label
logits_per_image = outputs.logits_per_image # this is the similarity score between image and each label
# Find the label with the highest score
probs = logits_per_image.softmax(dim=1) # Convert logits to probabilities
predicted_label = labels[torch.argmax(probs)]
print(f"Predicted label: {predicted_label}")
The output would be:

Having seen how easy it is to implement zero-shot image classification, let’s look at the benefits of using zero-shot models and how they can impact various applications.
No Need for Labeled Data: For every class, you cannot make predictions using labeled examples.
Flexibility: Zero-shot models can without retraining classify images or text over a broad spectrum of tasks.
Scalability: Applied to any task, zero-shot learning models are valuable for a great range of uses.
Although zero-shot classification models offer significant advantages, there are some challenges and restrictions to consider.
Prebuilt pipelines offer a straightforward and effective approach to apply zero-shot classification models without requiring careful model architecture management or written significant code. The transformers library from Hugging Face offers numerous prebuilt pipelines for jobs like zero-shot categorization, which let users use modern models with little preparation straight-forwardly.
Benefits of Using a Prebuilt Pipeline
Ease of Use: Prebuilt pipelines call for little coding and are easy for usage. The fundamental model architecture or data loading and processing techniques are not causes of concern for you.
Quick Deployment: Using a prebuilt pipeline, you may rapidly begin generating predictions for text, photos, or other data forms.
Optimized Performance: These pipelines use optimum parameters for each operation, ensuring that you obtain the greatest performance possible for most use scenarios.
Access to State-of-the-Art Models: Hugging Face pipelines let you apply zero-shot classification tasks with just a few lines of code by providing simple access to models such BART, GPT-3, CLIP, and more.
Here’s how you can use Hugging Face’s transformers library to perform zero-shot text classification with a prebuilt pipeline:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification")
# Sample text and candidate labels
text = "I love playing football on weekends!"
candidate_labels = ["sports", "politics", "technology", "entertainment"]
# Perform zero-shot classification
result = classifier(text, candidate_labels)
print(result)
The output would be:
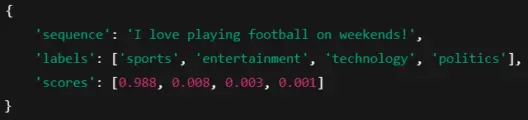
In this example, the text “I love playing football on weekends!” is classified into the “sports” category with the highest probability, showing that the model can predict categories it has never specifically trained on.
This approach works seamlessly for many NLP tasks such as sentiment analysis, topic classification, and more, without the need for manually fine-tuning or configuring the model.
Although prebuilt pipelines are fast and effective, occasionally you may choose to manually apply zero-shot categorization to have more process control. Manual implementation lets you use custom architectures, fine-tune, or change the behavior of the model to better fit your particular requirements.
Flexibility: You can customize the architecture and behavior of the model to suit more complex tasks or specific requirements.
Fine-tuning: You have the ability to fine-tune the model for your own datasets and tasks.
Advanced Use Cases: Manual implementation allows for the use of advanced techniques such as combining models or incorporating additional input features that prebuilt pipelines may not support.
Optimization: You can manually optimize the model and pipeline for performance, using techniques like batching, gradient checkpointing, or memory management.
Let’s go through the steps to manually implement zero-shot classification using the Hugging Face transformers library. We’ll use the same example as before but with more control over the model and tokenizer.
First, load a model that supports zero-shot classification. For this example, we will use BART, which is a versatile model for NLP tasks.
from transformers import AutoModelForSequenceClassification, AutoTokenizer import torch # Load pre-trained BART model for zero-shot classification model_name = "facebook/bart-large-mnli" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
Next, we need to tokenize both the input text and the list of candidate labels. This is necessary for the model to understand both inputs.
# Sample input text and candidate labels
text = "I love playing football on weekends!"
candidate_labels = ["sports", "politics", "technology", "entertainment"]
# Tokenize the text and candidate labels
inputs = tokenizer(text, candidate_labels, padding=True, truncation=True, return_tensors="pt")
# Perform inference
with torch.no_grad():
outputs = model(**inputs)
# Extract the logits (raw predictions) from the model
logits = outputs.logits
# Calculate probabilities using softmax
probabilities = torch.nn.functional.softmax(logits, dim=1)
# Get the predicted label and its probability
predicted_label = candidate_labels[torch.argmax(probabilities)]
predicted_probability = torch.max(probabilities).item()
print(f"Predicted label: {predicted_label} with probability {predicted_probability:.4f}")
The output would be:

In this manual implementation, we have complete control over how the model processes inputs and generates predictions. You can modify the pipeline to handle more complex tasks, such as multi-class classification or other forms of NLP tasks.
No Need for Labeled Data: You don’t need labeled examples for each class to make predictions.
Flexibility: Zero-shot models can classify images or text across a wide range of tasks without retraining.
Scalability: Zero-shot learning models can be applied to any task, making them useful for a wide variety of applications.
Although zero-shot classification models offer significant advantages, there are some challenges and restrictions to consider.

Accuracy: Zero-shot models may not perform as well as fine-tuned models for highly specialized tasks.
Bias: Models trained on large, general datasets may show biases or inaccuracies when dealing with specific or rare categories.
Computational Costs: Zero-shot models like CLIP and GPT require significant computational power to run efficiently.
Despite these challenges, zero-shot models have a promising future, and innovations are underway to make them even more effective.
Future developments may bring more effective zero-shot models that increase performance using less resources. Zero-shot models can also be fine-tuned to maximize accuracy on particular tasks while preserving generalizing ability. Combining zero-shot classification with other methods like few-shot learning could also help these models to be even more potent.
To summarize, let’s wrap up with a conclusion that highlights the importance and potential of zero-shot classification.
Zero-shot classification is transforming machine learning by allowing models to classify tasks and comprehend data they’ve never seen before. Zero-shot classification models offer flexible, scalable solutions for a wide range of real-world applications, including text, pictures, and multimodal activities. As these models grow, they have the potential to simplify complex jobs and allow AI to tackle a broader range of problems without requiring vast volumes of labeled data.
For a wide range of courses, training, and certification programs across various domains, check out Edureka’s website to explore more and enhance your skills!
1. What is zero-shot intent classification?
Zero-shot intent classification refers to a model’s capacity to categorize the intent of a user input (such as a statement or query) into predefined categories (or intents) without explicitly training on all potential categories. In zero-shot learning, the model does not encounter any labeled examples from the target class during training, but instead uses a general grasp of language to categorize the input based on semantic similarities between the input and the class labels.
For example, in a customer support chatbot, a zero-shot intent classification model could predict the intent behind the query “I need help with billing” as related to a “Billing” intent, even if the model has never been trained specifically on billing-related examples.
2. What is zero-shot image segmentation model?
Zero-shot image segmentation refers to a model’s capacity to categorize photos into certain classes (such as “dog,” “car,” and “tree”) without having seen labeled instances of these classes during training. A zero-shot image segmentation model usually employs a big pretrained model that comprehends both images and textual descriptions. Using the semantic relationship between textual labels and visual attributes, the model can execute picture segmentation based on textual descriptions it has never seen before..
For example, using models like CLIP or other multimodal models, the model can classify and segment parts of an image by associating it with descriptive labels such as “person,” “sky,” or “water,” even though the model has not been explicitly trained on those specific image types.
3. What is zero-shot and few-shot classification?
Zero-Shot Classification: In zero-shot classification, a model can categorize an input into categories it has never encountered during training. It is predicated on the model’s ability to generalize across tasks and categories using prior knowledge obtained from a diverse set of training data. Essentially, the model produces predictions without being exposed to labeled instances from the target class during training.
Few-Shot Classification: Usually in the range of 1–100, few-shot classification is a learning situation when a model is given a relatively small number of labeled instances from every target class. From these few samples, the model learns to generalize and classifies fresh data depending on this little information. Usually speaking, few-shot learning is more efficient than conventional supervised learning, in which a lot of labeled data is needed.
4. Why is it called zero-shot?
It is known as “zero-shot” since the model essentially handles a “shot,” or task without any training examples, making predictions or classifications on tasks it has never seen during training. Relying instead on the model’s capacity to generalize from previously learnt knowledge, the “zero” in “zero-shot” denotes that the model lacks any direct instances or “shots” from the target task to influence its predictions.
5. What is few shot classification?
In machine learning, few-shot classification is the situation when a model is trained to categorize data into groups depending just on a few labeled instances for every category. Particularly in situations when obtaining vast volumes of labeled data is challenging, few-shot learning is a method of increasing data-efficiency of machine learning models. Few-shot learning lets the model view a few number of instances per class (usually between 1 and 100) and generalize from them to handle new, unseen examples inside the same classes unlike zero-shot learning, which requires no labeled data for the target class.
















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


