
Agentic AI Certification Training Course
- 133k Enrolled Learners
- Weekend/Weekday
- Live Class
(63442)





 Copy Link!
Copy Link!The world of artificial intelligence is changing very quickly. Zero-shot learning (ZSL) is one of the most exciting and useful new developments. Because of this new method, models can accurately guess classes they have never seen while they were training. As AI systems get smarter, they need to be able to extend beyond what they’ve seen, and zero-shot learning is great for that.
In this blog, we’ll explore what zero-shot learning is, its types, how it works, why it’s useful, and its real-world impact. We’ll also delve into its methodologies and evaluate its strengths and limitations.
Zero-shot learning is a machine learning technique that enables models to recognize and predict previously unknown classes without requiring direct training on those classes. ZSL bridges the gap between known and unknown data by using auxiliary information such as textual descriptions, semantic embeddings, or class properties, rather than labeled instances for each class.
For example, a zero-shot image classifier trained on cats and dogs can recognize a horse by using textual descriptions of horses — even without ever seeing an image of a horse.
Zero-shot learning can be classified into three main types:
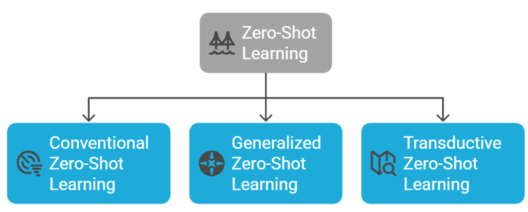
These variations help balance the trade-off between model generalization and specificity.
Zero-shot learning is gaining traction due to its numerous advantages:
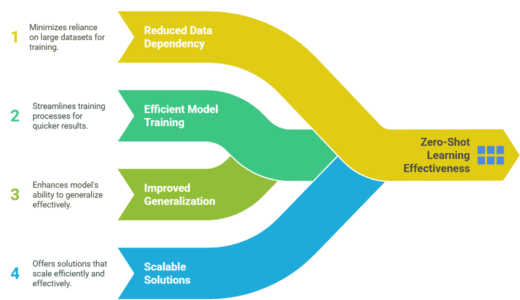
The power of zero-shot learning is in the ability to transfer information from seen to unseen data. Let us break down the important components:
ZSL relies on auxiliary data such as class descriptions, semantic attributes, and embeddings. This new context enables the model to distinguish between classes without requiring explicit training.
ZSL relies heavily on transfer learning. Pretrained models (such as BERT, CLIP, and ResNet) learn generic representations that can be easily applied to new classes.
</p>
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
text = "This gadget helps improve productivity."
labels = ["technology", "entertainment", "health"]
result = classifier(text, labels)
print(result)
Here, we use a zero-shot text classifier that matches the input text to the most relevant label without specific training for these categories.
To describe and discriminate between classes, attribute-based approaches use human-defined, interpretable properties. For example, in animal categorization, characteristics such as fur, number of legs, and environment can distinguish various species. This strategy works best when the attributes are informative and well-structured.
</p>
# Attribute-based classification example
class AnimalClassifier:
def __init__(self, attributes):
self.attributes = attributes
def classify(self, features):
for animal, attr in self.attributes.items():
if attr == features:
return animal
return "Unknown"
# Defining some animals by their attributes
attributes = {
'Dog': {'fur': True, 'legs': 4, 'habitat': 'domestic'},
'Bird': {'fur': False, 'legs': 2, 'habitat': 'wild'},
}
classifier = AnimalClassifier(attributes)
result = classifier.classify({'fur': True, 'legs': 4, 'habitat': 'domestic'})
print(result) # Output: Dog
Here, we define animals based on their attributes and match an input set of features to a known class.
Embedding-based approaches map both classes and instances into a shared vector space while preserving semantic links. These models frequently use word embeddings or other feature representations to connect visible and invisible categories.
</p>
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
# Simulated embeddings for classes and instances
class_embeddings = {
'Cat': np.array([0.9, 0.1]),
'Dog': np.array([0.8, 0.2]),
}
instance_embedding = np.array([0.85, 0.15])
# Finding the closest class based on cosine similarity
similarities = {cls: cosine_similarity([embedding], [instance_embedding])[0][0]
for cls, embedding in class_embeddings.items()}
closest_class = max(similarities, key=similarities.get)
print(closest_class) # Output: Cat
We embed both the instance and classes into a vector space and use cosine similarity to find the most similar class.
Generative models, such as GANs (Generative Adversarial Networks) or VAEs (Variational Autoencoders), enrich the training dataset by producing synthetic data for previously unseen classes based on their descriptions.
</p> import numpy as np class SimpleGAN: def generate(self, description_vector): # Simulate generation by adding noise to the description noise = np.random.normal(0, 0.1, size=description_vector.shape) return description_vector + noise # Description vector for an unseen class description_vector = np.array([0.5, 0.8]) # Generate synthetic samples gan = SimpleGAN() generated_sample = gan.generate(description_vector) print(generated_sample)
This simple GAN adds noise to a description vector to generate synthetic data, which could then be used to train classifiers on previously unseen classes. Attention Mechanism in Generative AI enhances this process by allowing the model to focus on specific parts of the input data, improving the quality and relevance of the generated data, especially when dealing with complex or long-range dependencies in the descriptions.
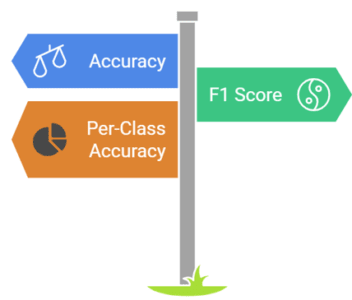
Evaluating zero-shot models requires specialized metrics:
Companies benefit from ZSL through:

Despite its advantages, ZSL has its challenges:
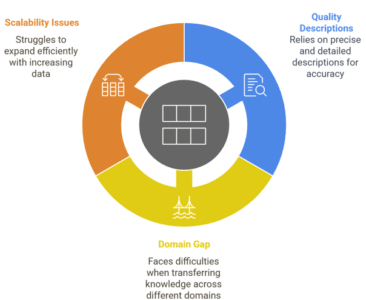
Zero-shot learning is transforming how AI models generalize and adapt, with enormous implications for corporations and researchers alike. ZSL expands innovation opportunities by lowering data dependency and enhancing scalability. As this field evolves, latent variable in Gen AI will further increase its impact on the technology landscape.
Detecting and classifying objects without any training examples for those object classes. Uses pretrained models with textual descriptions or semantic data.
from transformers import pipeline
detector = pipeline("zero-shot-object-detection", model="facebook/detr-resnet-50")
results = detector(image, candidate_labels=["cat", "dog"])
A Large Language Model (LLM) makes predictions without specific fine-tuning — using general knowledge from pretraining to answer unfamiliar tasks based only on natural language prompts.
from transformers import pipeline
llm = pipeline("text-classification", model="distilbert-base-uncased")
result = llm("Is this movie review positive or negative?")










 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP






