In today’s data-driven society, companies and groups are always looking for better methods to use data without letting users’ privacy or security suffer. Newly developed synthetic data, which mimics real-world data without incorporating any sensitive or personally identifiable information, is one of the most encouraging solutions. Synthetic data has grown in importance as a resource for research, model testing, and algorithm training due to the proliferation of ML and AI.
Table of Content
But precisely why is synthetic data so important, and how may it help sectors other than those listed here? Let us investigate what synthetic data is, why it is needed, the techniques used to create it, and the real-world uses transforming businesses all around.
What is Synthetic Data?
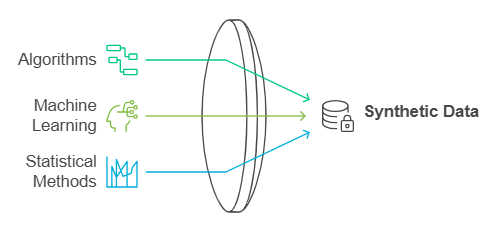
Synthetic data refers to datasets that are generated using algorithms, typically involving techniques like machine learning or statistical methods. Though they lack any actual personal or identifying information, these databases reflect the features of real-world data. This lets companies perform simulations, test systems, and training models using important data without running privacy issues. It is a means to avoid the possible risks connected with using actual data while enjoying the advantages of data-driven decision-making.
Why is Synthetic Data Required?
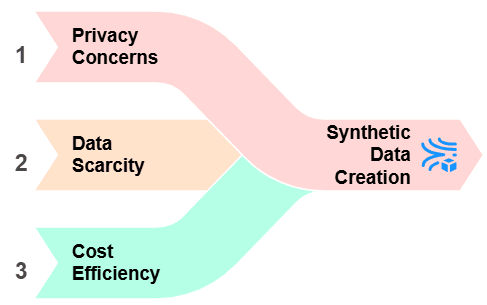
Businesses and technologies depend more on data, so they have some main difficulties working with actual data, including privacy issues and data shortages. It can assist in numerous respects to solve these problems:
Privacy Concerns: Real data might be difficult to use in line with laws like GDPR since it frequently includes sensitive or personal information. It offers a substitute free from real-world personal data, so removing this issue is important.
Data Scarcity: Real data may occasionally be difficult to find or absent. But, synthetic data can cover the gaps and generate strong datasets for analysis and model training, whether the reasons are logistical, financial, or just the rarity of particular events.
Cost Efficiency: Getting, organizing, and managing actual data takes time and money. Conversely, data production can be done rapidly and on a large scale, providing a more reasonably priced substitute.
Real Data vs. Synthetic Data
Real data is often the default starting point, but it’s not always ideal. Here’s how it compares with synthetic data in everyday use:
Real Data – Authentic data from actual sources Collected from real-world systems, transactions, or users. It’s highly reliable but may be messy, biased, or restricted by privacy regulations.
Synthetic Data – Artificially generated for simulation and model training Created using algorithms to replicate patterns of real data without using sensitive information. Great for testing, training, and privacy-focused tasks.
When to Use Real Data – For accurate insights and compliance Ideal for audits, real-world analytics, and production models where you need precision and regulatory trust.
When to Use Synthetic Data – For flexibility, scalability, and safety Useful in machine learning, simulation, and scenarios where real data is limited, imbalanced, or risky to expose.
Key Trade-off – Trust vs. Control Real data reflects reality but raises compliance concerns. On the other hand synthetic data offers control and privacy but must be carefully validated to avoid misleading results.
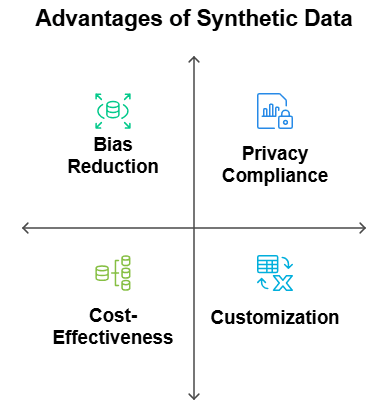
Advantages of Synthetic Data
For many companies and organizations, data presents various benefits that appeal. Of these advantages, some are:
Privacy Compliance: It lets companies produce datasets that follow privacy rules like GDPR and CCPA, free of the risk of data breaches since real personal data is not included.
Cost-Effectiveness: Collecting and organizing real-world data can be costly, time-consuming, and occasionally impractical—especially in unusual or difficult-to-collect circumstances. An attractive option is synthetic data since it can be produced rapidly and at a far cheaper cost.
Customization: Customizing it allows one to match certain needs or situations. This will enable companies to create precisely tailored data that meet their demands without regard to the extent of the accessible, genuine data.
Bias Reduction: Real-world data collecting sometimes carries prejudices depending on historical data or sample techniques. By means of synthetic data, one can decrease or eliminate these biases, hence producing more fair and accurate models.
Uses of Synthetic Data
Synthetic data has a wide range of applications, from improving AI models to enabling more precise simulations. Among the significant domains where it finds utility are:
Machine Learning and AI: Artificial intelligence and machine learning models are trained using synthetic data rather extensively. It offers a reasonably priced and quick way to train without depending on real data since big, labeled datasets are generally needed to train robust AI models.
Autonomous Vehicles: Self-driving cars depend on large volumes of data to learn how to negotiate various surroundings properly. It is used to replicate several driving situations, including weather, traffic patterns, and road scenarios, to enable autonomous systems to be trained.
Healthcare: It is used in healthcare to generate reasonable medical records, therefore enabling the development and testing of healthcare algorithms free from real patient data exposure. It can also replicate unusual medical diseases or treatments that might not be well reflected in actual data.
Finance: For financial simulations, fraud detection systems, and risk model testing, it is absolutely vital. It enables financial firms to replicate several economic variables and market situations without leveraging private client data.
Types of Synthetic Data
There are various sorts of synthetic data, each suitable to a distinct applied action or industry. Here are some of the major types:
Tabular Data: Often seen in corporate analytics and financial systems, synthetic tabular data replicas conventional data records. It can copy organized information, including inventory logs, sales records, or client files.
Image Data: Applications, including computer vision, can leverage synthetic image data to teach image recognition algorithms. Industries, including healthcare (for medical imaging) and autonomous driving (for object identification), find this very helpful.
Text Data: Text data production entails producing synthetic text for applications such as natural language processing (NLP). This can help train chatbots, language models, and sentiment analysis systems.
Time Series Data: Industries include finance, where predictive modeling depends on data over time—such as stock prices or economic indicators—often employ synthetic time series data.
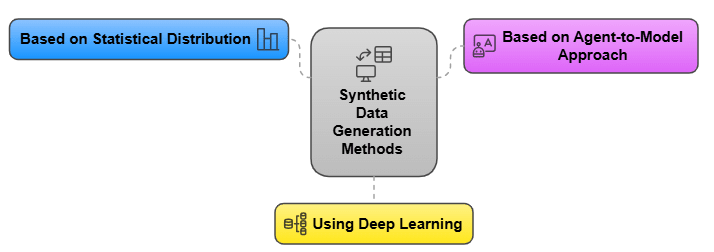
Synthetic Data Generation Methods
Now that we understand the importance, let us look at how it is created. The method of producing synthetic data has evolved dramatically, allowing for high-quality datasets that replicate the intricacies of real-world data.
Based on the Statistical Distribution
It is produced in part by modeling real-world data using statistical distributions. For instance, a dataset might show a normal distribution for customer ages. Sampling from this distribution generates the data by means of new instances reflecting the same statistical characteristics as the original data.
Based on an Agent-to-Model Approach
In more complex simulations, the data is produced by constructing agents (virtual representations of real-world entities) that interact with a model or environment. In traffic simulations, for example, automobiles (agents) can be programmed to travel in accordance with traffic rules, resulting in synthetic traffic data for AI models.
Using Deep Learning
Particularly in picture and video synthesis, deep learning methods such as Generative Adversarial Networks (GANs) have become well-known for creating quite realistic data by training two neural networks—one producing the data and another assessing its authenticity—GANs help to raise the quality of produced data continuously.
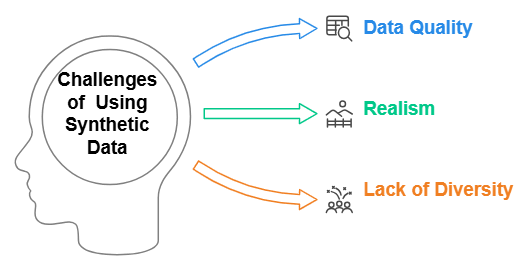
Challenges and Limitations While Using Synthetic Data
Synthetic data has certain difficulties and restrictions even if it has many advantages:
Data Quality: Data quality is highly influenced by the techniques and algorithms applied in their generation. Inaccurate models and unsatisfactory findings can follow from poorly produced synthetic data.
Realism: It may not always reflect all the subtleties and complexity of natural data, even if it is meant to replicate it. In some situations where the model must handle extremely complex or erratic real-world scenarios, this can make it less efficient.
Lack of Diversity: It is produced depending on a small set of assumptions or patterns could not reflect the variety found in actual data. Models made from this could be less strong and less suited to manage unusual or rare events.
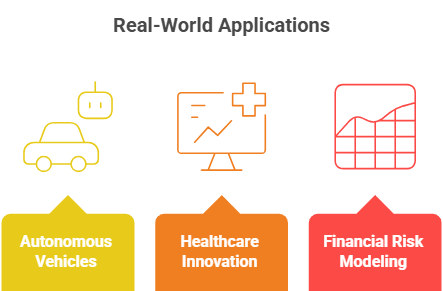
Real-World Applications
Already having a major influence in many different sectors, it offers creative ideas in fields including banking, healthcare, autonomous cars, and more. Among the more intriguing practical uses are some like:
Training Autonomous Vehicles: It helps self-driving cars to replicate many driving situations, hence enhancing safety and efficiency. AI models may learn to negotiate safely in any environment by creating several weather conditions, traffic scenarios, and road designs
Healthcare Innovation: It enables the construction of artificial patient records for use in training AI models for disease prediction and therapy recommendations in the context of healthcare. It aids in areas like uncommon diseases or experimental treatments when actual data is rare or delicate.
Financial Risk Modeling: Financial organizations create it to test investment strategies, replicate market behavior, and project market moves. Simulating many economic situations and scenarios helps banks better equip themselves for changes in the real-world market.
Future of Synthetic Data
As artificial intelligence and machine learning keep developing, data’s importance should only become more apparent. It will become a more common answer as privacy rules get tougher and the demand for vast information rises. The future could see even more advanced techniques for creating extremely accurate data. Hence, this tool is essential for businesses in all spheres.
Conclusion
Synthetic data is an exciting and innovative technology that is shaping the future of AI and machine learning. By addressing privacy concerns, reducing costs, and enabling the generation of customized datasets, synthetic data is helping businesses and organizations build better models, conduct more effective research, and stay ahead in an increasingly data-driven world.
While challenges remain, such as ensuring data quality and realism, synthetic data holds immense potential in solving real-world problems across industries. As techniques and tools continue to evolve, the use of synthetic data is likely to expand, making it a key player in the world of AI and data science. If you’re interested in exploring this field further, Edureka’s Generative AI & Prompt Engineering program offers a solid starting point.