
Advanced Certification in Agentic AI Engineer ...
- 64k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!Few-shot learning (FSL) is changing data science by allowing models to make correct predictions using very little labeled data. Unlike traditional guided learning, which needs a lot of data, Few-Shot Learning (FSL) is about learning from just a few examples. This makes FSL perfect for situations where data is limited or difficult to get.
In this blog, we’ll explore Few-shot learning, its main ideas, and how it differs from traditional learning methods. This will help you understand its ability to transform various industries.
Few-shot learning (FSL) is a type of machine learning that helps models make good predictions using very little labeled data. It is different from traditional supervised learning. While traditional methods require large amounts of labeled data for each category, FSL trains models using only a few examples, sometimes just one or two for each category.
 Few-shot learning is designed to replicate how humans can quickly understand new ideas with little experience. For example, if a person sees a few pictures of a rare animal, they can usually identify that animal in other situations without needing to see hundreds of cases. FSL uses this idea to help with situations where it is hard, costly, or almost impossible to collect data, like:
Few-shot learning is designed to replicate how humans can quickly understand new ideas with little experience. For example, if a person sees a few pictures of a rare animal, they can usually identify that animal in other situations without needing to see hundreds of cases. FSL uses this idea to help with situations where it is hard, costly, or almost impossible to collect data, like:
Few-shot learning is part of a larger category called n-shot learning, which has different types, including:
Instead of just classifying known examples, FSL tries to learn how to learn. This means teaching models to recognize how data points are connected and different from each other. For instance, even if the model hasn’t been trained on specific types like squirrels or pangolins, it can still determine if two pictures are from the same group by examining their features.
To learn more about advanced AI topics, check out our blog on What is Generative AI.
Now that we understand what few-shot learning is and why it’s important, let’s take a look at the key prerequisites to get started with it.
Before you begin with few-shot learning, make sure you have the following:
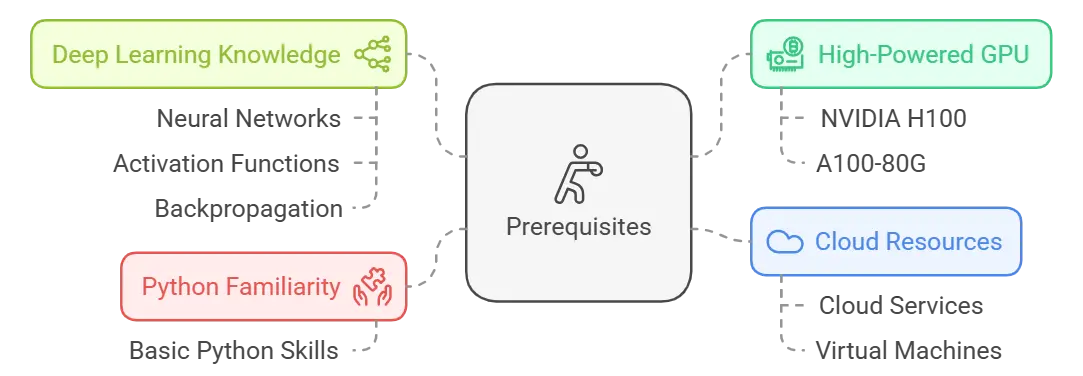 Access to a High-Powered GPU: Use a strong NVIDIA GPU, like the H100 or A100-80G, to run deep learning models effectively. Weaker GPUs can be used, but they might work more slowly. Learn more about GPU requirements for deep learning from NVIDIA.
Access to a High-Powered GPU: Use a strong NVIDIA GPU, like the H100 or A100-80G, to run deep learning models effectively. Weaker GPUs can be used, but they might work more slowly. Learn more about GPU requirements for deep learning from NVIDIA.Follow a detailed guide to set up a GPU Droplet, connect to it via SSH, and set up an environment (e.g., Jupyter Notebook) for coding and visualization.
Before diving into Few-Shot Learning, explore our Generative AI Course for foundational AI knowledge.
With the prerequisites in place, let’s explore why few-shot learning is gaining traction and how it addresses the limitations of traditional learning methods.
Traditional supervised learning relies heavily on large sets of labeled data to be accurate. This method has some drawbacks, such as requiring a lot of time, effort, and computer power to gather, label, and handle the data. Moreover, these models struggle with domain shift, where the statistical distribution of training data varies from that of new data (e.g., images from a mobile phone versus those from a DSLR camera).
Few-shot learning addresses these challenges by: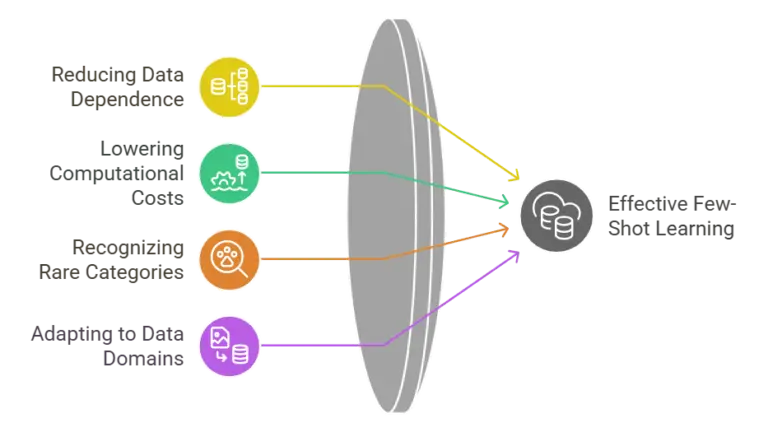
Few-shot learning is a helpful method that addresses some problems with traditional supervised learning. It allows models to be trained well even when there isn’t much data available and can be used in different areas.
For a broader understanding of how AI is transforming industries, you can read about Artificial Intelligence Applications. Agentic AI refers to AI systems with decision-making capabilities. Our agentic AI course teaches you how to develop and deploy these advanced models.
Now that we understand why Few-Shot Learning is important, let’s dive into how it actually works and the key techniques behind it.
Few-shot learning (FSL) focuses on creating a function that determines how similar classes are in two groups: the support set and the question set. This function checks how alike or different data sets are. The result of this similarity function usually shows a chance, which indicates how likely it is that two samples are in the same category.
N-Shot Learning is a machine learning technique where a model learns to perform a task with N examples. This is especially useful when you have limited data. It’s widely used in natural language processing, image recognition, and few-shot classification.
Example Prompt:
“Translate ‘How are you?’ to Spanish.”
Output: “¿Cómo estás?”
One-Shot Learning
Example:
Let’s look at a situation involving electronic gadgets. In an ideal situation, two pictures of the same smartphone model should have a similarity score of 1.0, showing they look the same.

If you compare a picture of a smartphone to a picture of a laptop, they should have a similarity score of 0.0 because they are very different products.

In reality, slight differences can occur because of things like lighting, angles, or backgrounds. For example:
This measure of closeness is very important in few-shot learning. The aim is to determine which category a sample from the question set fits into by comparing it with samples in the support set.
A big-named dataset like ImageNet is used to teach the model how to understand similarities in a supervised way. When this pre-trained model is ready, it can help in Few-Shot Learning by predicting new samples based on their similarity to the reference set.
In Few-Shot Learning, we often use neural networks to compare similarities, and one well-known model for this is the Siamese Network. Siamese describes a type of network made up of two or more similar neural networks that use the same settings. These networks handle data at the same time and then check the results.
In this method, the Siamese network is taught with two examples from the dataset. If the samples belong to the same class, the model assigns a closeness label of 1.0, and if they belong to different classes, it assigns a label of 0.0. This method teaches the network how to measure similarity by using examples that are already named. After the samples go through the pre-trained feature generator, the network measures how similar they are and then adjusts its settings using backpropagation.
Here’s a small snippet of code to calculate the cosine similarity between two samples:
import torch import torch.nn as nn input1 = torch.randn(100, 128) input2 = torch.randn(100, 128) cos = nn.CosineSimilarity(dim=1, eps=1e-6) output = cos(input1, input2)
In Python, you can use the SiameseDataset class to manage datasets. This class helps you load pairs of pictures that are either from the same category (positive samples) or from different categories (negative samples).
import random from PIL import Image import torch from torch.utils.data import Dataset class SiameseDataset(Dataset): def __init__(self, folder, transform=None): self.folder = folder # Type: torchvision.datasets.ImageFolder self.transform = transform # Type: torchvision.transforms def __getitem__(self, index): # Random image set as anchor image0_tuple = random.choice(self.folder.imgs) random_val = random.randint(0, 1) if random_val: # If random_val = 1, output a positive class sample while True: # Find "positive" Image image1_tuple = random.choice(self.folder.imgs) if image0_tuple[1] == image1_tuple[1]: break else: # If random_val = 0, output a negative class sample while True: # Find "negative" Image image1_tuple = random.choice(self.folder.imgs) if image0_tuple[1] != image1_tuple[1]: break image0 = Image.open(image0_tuple[0]) image1 = Image.open(image1_tuple[0]) if self.transform is not None: image0 = self.transform(image0) image1 = self.transform(image1) # Return the two images and their similarity label return image0, image1, int(random_val) def __len__(self): return len(self.folder.imgs)
In the Triplet Loss method, the model uses three images instead of just two. These images are: an anchor image, a positive image (which is from the same category as the anchor), and a negative image (which is from a different category). The aim is to bring the anchor and positive samples closer in the embedding area and move the anchor and negative samples further apart.
Here’s how the TripletMarginLoss is implemented in PyTorch:
import torch import torch.nn as nn</pre> triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2) anchor = torch.randn(100, 128, requires_grad=True) positive = torch.randn(100, 128, requires_grad=True) negative = torch.randn(100, 128, requires_grad=True) output = triplet_loss(anchor, positive, negative) output.backward()
To handle the dataset for the triplet loss method, you’ll need to change the class so that it gives you triplets, which include an anchor, a positive sample, and a negative sample.
import random from PIL import Image import torch from torch.utils.data import Dataset class TripletDataset(Dataset): def __init__(self, folder, transform=None): self.folder = folder # Type: torchvision.datasets.ImageFolder self.transform = transform # Type: torchvision.transforms def __getitem__(self, index): # Random image set as anchor anchor_tuple = random.choice(self.folder.imgs) while True: # Find "positive" Image positive_tuple = random.choice(self.folder.imgs) if anchor_tuple[1] == positive_tuple[1]: break while True: # Find "negative" Image negative_tuple = random.choice(self.folder.imgs) if anchor_tuple[1] != negative_tuple[1]: break anchor = Image.open(anchor_tuple[0]) positive = Image.open(positive_tuple[0]) negative = Image.open(negative_tuple[0]) if self.transform is not None: anchor = self.transform(anchor) positive = self.transform(positive) negative = self.transform(negative) return anchor, positive, negative def __len__(self): return len(self.folder.imgs)
Few-shot learning is a useful method that allows models to make correct predictions using very little data by learning how things are similar. Methods like Siamese Networks and Triplet Loss are important for making Few-Shot Learning effective, and they can be used in many different areas.
To expand your knowledge on similar AI models, check out this Generative AI Tutorial.
Now that we understand the fundamentals of few-shot learning, let’s dive into how few-shot classification specifically operates.
Few-shot learning (FSL) focuses on making correct guesses using only a small amount of labeled data. It usually uses transfer learning and meta-learning strategies, or a combination of both.
Most FSL methods are about classification, which means their main goal is to identify new categories using only a few examples. Here’s how these methods are important:
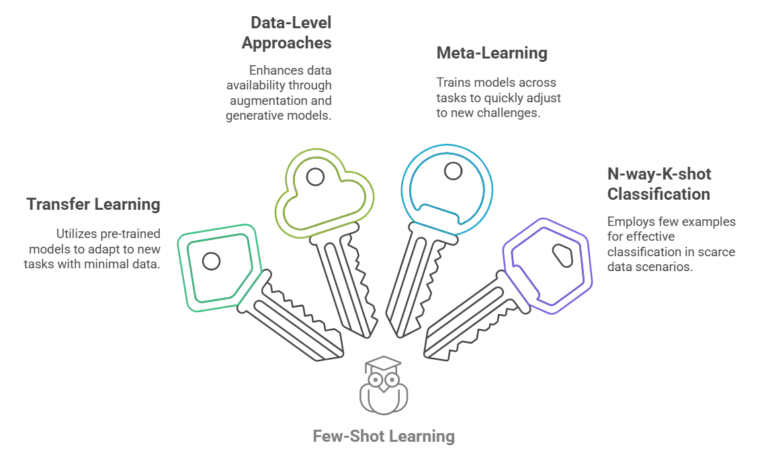 1. Transfer Learning
1. Transfer LearningTransfer learning means using a model that has already learned from a big set of data and adjusting it to perform a new, similar task with less data. This method uses what the model has learned to prevent overfitting, a frequent problem when working with small datasets. For example, a model that learns to recognize different types of birds might only need a few extra labeled images to identify a new type because it already knows important things like feathers and beaks. Tweaking the model or changing its design helps it perform better on new tasks.
To address the lack of named data, we use methods like data augmentation or generative models, such as GANs or VAEs. These methods create extra samples similar to the original data, which helps the model work better without needing more real data. For example, in medical applications or for identifying rare species, these methods help create more examples for training.
Meta-learning, or learning to learn, is a way of training a model on many tasks so it can find a general method to solve new tasks using less data. Instead of teaching a model for just one task, meta-learning helps the model learn how to quickly adjust to new tasks by spotting similarities in different areas. This helps the model apply prior information to unseen data, which is especially useful in few-shot classification tasks.
Few-shot learning usually uses the N-way-K-shot method. In this setup, N is the number of classes, and K is the number of cases for each class. In a 3-way-2-shot job, the model receives 2 examples from each of 3 different groups and is then asked to classify new examples using these few samples. This setup helps the model learn and make predictions with only a few named examples, which is important when data is scarce.
Few-shot classification uses techniques like transfer learning, data enrichment, and meta-learning to help models perform well even with a small amount of labeled data. Using methods like N-way-K-shot, these models can learn from small amounts of data and quickly adjust to new jobs.
Now that we’ve covered how few-shot classification works, let’s explore one of the key techniques used in this area: Metric-Based Meta-Learning.
N-Shot Learning is a machine learning technique where a model learns to perform a task with N examples. This is especially useful when you have limited data. It’s widely used in natural language processing, image recognition, and few-shot classification.
Example:
prompt = """ Review: "I love this phone!" Sentiment: Positive Review: "The battery life is terrible." Sentiment: Negative Review: "Amazing camera quality." """
# Output: Positive
Metric-based meta-learning algorithms focus on figuring out how similar data samples are instead of creating models to separate different groups. These methods create continuous values, known as vector embeddings, to describe data points. They then develop a function to measure the distance between these points to make predictions.
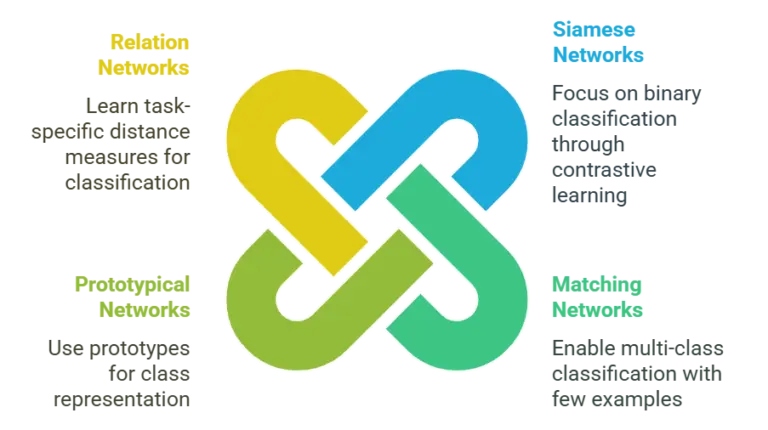 Siamese Networks
Siamese NetworksSiamese networks are one of the first methods that use a metric-based approach to solve binary classification problems through contrastive learning. The network compares pairs of samples to guess whether they match. The aim is to make the distance between matching pairs of vector embeddings as small as possible, while making the distance between non-matching pairs as large as possible. This method works well when the training samples are hard to tell apart, often needing extra data to improve the outcome.
Matching networks build on Siamese networks to allow for classifying items into multiple categories. This method creates an embedding for each sample in both the support and query sets. It predicts the classification by comparing the cosine distance between the embedding of the question sample and the embeddings in the support set. It’s one of the first methods created for learning with only a few examples.
Prototypical networks use a unique method of finding an average model (called a prototype) for each class using all the available samples. A data point is categorized by how close it is to these example points using a method called Euclidean distance. This method has been improved by using techniques like label propagation to improve the testing process.
Relation networks work like matched and prototypical networks, but they use a different method to calculate the distance between embeddings. Other methods use set distance functions, like cosine or Euclidean distance. In contrast, relation networks use a special module that learns the best way to measure distance for a specific classification job, which makes them more flexible and accurate.
While metric-based meta-learning focuses on comparing data through similarity measures, optimization-based meta-learning takes a different approach. It fine-tunes model parameters to enable rapid adaptation to new tasks.
Optimization-based meta-learning aims to improve neural network’s ability to learn quickly from just a few examples by improving their training process. Traditional deep learning uses a method called gradient descent to make changes repeatedly. It also needs a lot of labeled data to work effectively. On the other hand, optimization-based methods try to reduce the number of changes required by improving the training process itself.
MAML is a well-known method that can be used with different types of AI models. It adjusts a model’s starting settings so they can be easily updated for new jobs. The process includes two steps for updating parameters:

Notable Variants: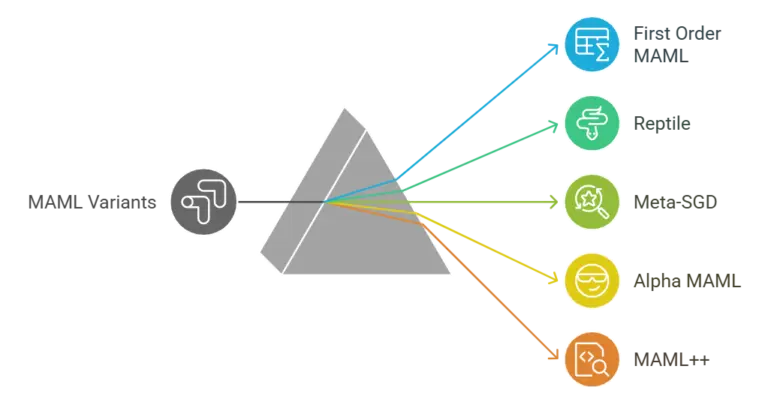
Long-short term memory (LSTM) networks act as learners that understand both short-term tasks and long-term patterns. This method helps train classifiers to adapt better to different jobs.
LEO works in a low-dimensional embedding space, optimizing parameters through a generative distribution akin to variational autoencoders (VAEs). This makes the calculations easier without losing effectiveness.
Meta-learning that focuses on optimization helps models improve how they learn new tasks. Now, let’s look at different methods that address the problems of few-shot learning, each with its way of boosting performance using very little data.
Few-shot learning methods are divided into four main strategies, each focused on solving the problems that come with having very little labeled data:
Data-level methods aim to improve the dataset by adding more cases to address the lack of labeled data. Methods include:
These methods add more data for training, which helps the model work better and reduces the chances of making mistakes
Parameter-level methods adjust the model’s settings to improve learning from small amounts of data. In this case:
These methods allow for accurate predictions even with few samples by smartly managing the parameters.
These methods depend on measuring lengths between data points in the embedding space. Some common methods are:
Metric-level methods are great for finding connections between query and reference samples using similarity scores.
Gradient-based methods use a teacher-student setup to improve the model’s settings.
This two-part learning method helps explore different options effectively and improves how well tasks can be adjusted.
Let’s explore a tougher version of Few-Shot Learning, called One-Shot Learning. In this version, we have only one case for each class.
One-shot learning is challenging because there is only one example for each class in the support set. It requires effective learning methods with little help or background knowledge. For example, the face recognition feature in today’s smartphones uses One-Shot Learning.
An example of a good method is the One-Shot Semantic Segmentation technique. This method uses a special design with two branches:
This design has several benefits compared to standard fine-tuning methods:
One-Shot Learning is a type of Few-Shot Learning that works well with little data. It has many uses in different areas, changing how we handle jobs in computer vision, robotics, and natural language processing.
Few-Shot Learning (FSL) has become important in many areas because it works well even when there isn’t much data available. Let’s look at some important ways FSL has been used successfully:
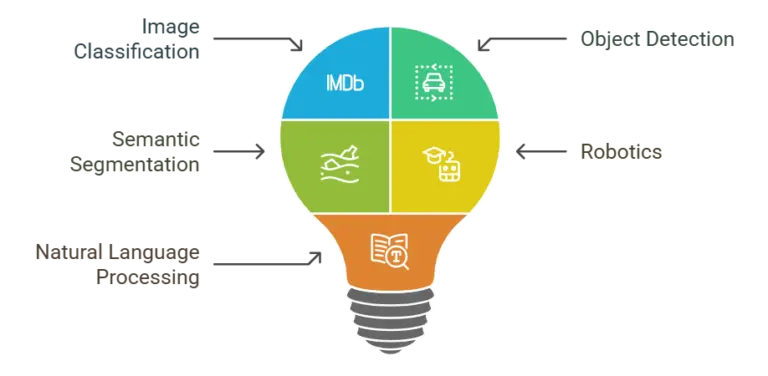 1. Image Classification
1. Image ClassificationFew-shot learning is commonly used in image classification, providing new ways to handle problems when little classified data is available.
Object detection finds and locates objects in an image or video. This job can be tricky because there are often many objects in one picture.
Semantic segmentation labels each pixel in a picture, which is useful for analyzing images in detail.
For example, Liu suggested a Semi-Supervised Few-Shot Semantic Segmentation framework with part-aware prototypes for capturing diverse object features.
Using unlabeled images helps the model better deal with differences within the same class and allows it to go beyond small sets of labeled pictures.
This allows for better and more complete separation, even when there is little labeled data.
Few-shot learning is being used in robotics to help robots understand and perform tasks based on only a few examples.
FSL is becoming popular in natural language processing (NLP) jobs because it can be hard and expensive to get labeled data.
To understand how Few-Shot Learning is so adaptable, it’s important to know the difference between two main parts: the Support Set and the Training Set.
In few-shot learning, the support set is a word often used in meta-learning. It means a small group of examples with labels that are used in testing to help make better guesses. This is different from the training set, which is bigger and used to train deep neural networks in regular machine learning.
And, if we talk about the differences between the Support Set and the Training Set:
| Aspect | Support Set | Training Set |
| Purpose | Used to evaluate the performance of the model during the learning phase. | Used to train the model by learning patterns and making predictions. |
| Data Size | Typically smaller than the training set. | Larger as it contains more data to learn from. |
| Usage | Helps fine-tune and optimize model parameters. | Helps the model learn and generalize patterns in data. |
| Content | Contains examples not used during training but related to the task. | Contains labeled examples that the model uses to learn. |
| Goal | Assesses the model’s capability to adapt to unseen tasks. | Ensures the model learns the foundational patterns in data. |
| Relation to Model Updates | Does not update the model directly; it is used for evaluation only. | Directly influences model weights and parameters during training. |
To train a deep neural network using standard machine learning, you need a lot of examples for each category. In a support set, each class might have just a few cases. This small set of data helps during tests by allowing the model to learn and make predictions based on relationships and patterns instead of just memorizing information.
Now that we’ve looked at the difference between the Support Set and Training Set, let’s talk about learn to learn and how it’s important for Few-Shot Learning.
Imagine taking a child to the zoo. He spots a soft animal in the water that he’s never seen before and excitedly asks, What is this? Now, you give him a set of cards that show pictures of animals along with their names. Although the animals on the cards are new to him and he has never seen the one in the water, the child is smart enough to understand. He looks at the animal in the water and compares it to the cards to find the best match. The power to learn on his own is the core idea of meta-learning.
Here’s the twist: before going to the zoo, the child already knew how to compare animal’s similarities and differences. In this situation, the strange animal in the water is called the question, and the cards it uses to learn are called the support set. Learning to learn on your own is called meta-learning.
If the child only needs one card for each species to recognize them, that’s called one-shot learning. Meta-learning in machine learning focuses on quickly understanding and adjusting to new situations with little knowledge.
Now that we understand what learn to learn means, let’s look at how few-shot learning, an important part of meta-learning, is different from traditional guided learning.
In supervised learning, a model learns from a large set of data with labels for each piece of information. Once the model is learned, we use it to make predictions. The process is easy: We show a test sample, and the model identifies it using what it has learned from the training data.
On the other hand, few-shot learning poses a different problem. Here, the example given to the model is brand new; it comes from a category the model has never seen before. The main difference between the two methods is that in guided learning, the model learns from already-known categories, while in few-shot learning, the model needs to learn to identify new categories with just a few examples.
Now that you know the main differences between them, let’s look at some important terms that will help you understand how few-shot learning works.
Let’s explain some important terms in few-shot learning:
In short, we describe the support set as k-way and n-shot to show how many classes (k) and how many samples for each class (n) it has.
Now that we’ve discussed the important terms in few-shot learning, let’s look at how these ideas affect prediction accuracy in these learning tasks.
When performing few-shot learning, the prediction accuracy is affected by two factors: the number of ways (k-way) and the number of shots (n-shot).
Why does this occur? Let’s consider an example: you give a child 3 cards and ask them to choose the right one. This is a job that involves three parts and is done in one attempt. What if you let the child pick from 6 cards? That’s called 6-way 1-shot learning. Which one do you think is easier?
It’s clear that picking from three choices is easier than picking from six options. In general, learning in 3 parts is more accurate than learning in 6 parts.
Now that we know how prediction accuracy is affected by few-shot learning, let’s explore the main idea behind this method—how it teaches a model to recognize similarities.
The basic idea of few-shot learning is to train a function that predicts the relationship between samples.
This likeness is measured with a function called sim(x, x’), where x and x’ are two samples.
After training, this similarity function can be used to make predictions for unseen questions. We can find similarity scores by comparing the question with each sample in the support set. Next, we look for the most similar sample and use that as the expected label.
Here’s how the process works:
Let’s look at a real-life example of a traffic tracking system. The system gets a picture of a vehicle from a traffic camera and needs to find out what kind of vehicle it is. The system uses a collection of sample pictures showing various types of vehicles.
Image from the traffic camera:
 Sample Images:
Sample Images:
 The system checks the query picture against each sample image and measures how similar they are. For example:
The system checks the query picture against each sample image and measures how similar they are. For example:
The system finds that the car in the query picture is most likely a sedan because it has a similarity score of 0.85 with the Sedan sample.
One-shot learning works by comparing a new example (query) to each example in a set of known samples (support set). The model finds the most similar example and uses it to make a prediction.
In summary, Few-Shot Learning is changing how models work with small amounts of data, allowing them to get great results even when there are only a few examples. FSL helps solve real-world problems where data is limited or hard to find by emphasizing the ability to generalize and learn to learn.” This field is changing and will likely be used more in healthcare, identifying rare species, and other areas. It will provide new answers to problems that traditional machine learning can’t easily solve.
Want to explore more? Start learning with our Generative AI Course or dive into a specialized Prompt Engineering Course.
Related Post: Few-shot learning in Prompt Engineering
Few-shot learning techniques help a model learn to recognize patterns using only a small number of examples. This is useful when there isn’t much labeled data available.
In computer vision (CV), few-shot learning helps models recognize and classify things using just a few images, instead of needing many labeled examples.
Shot learning means how many examples a model gets to learn from. It is usually called one-shot, few-shot, or many-shot depending on how many cases there are.
One-shot learning means learning from just one example, and few-shot learning means learning from a small number of examples, usually between 2 and 10.

















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP



