
Agentic AI Certification Training Course
- 136k Enrolled Learners
- Weekend/Weekday
- Live Class
(63442)





 Copy Link!
Copy Link!Imputation in statistics means replacing missing data with different numbers. “Unit imputation” means replacing a whole data point, while “item imputation” means replacing part of a data point.
Missing information can cause bias, make data analysis harder, and lower efficiency. These are the three main problems it creates. Imputation is a way to handle missing data instead of simply removing cases with missing values, as missing information can make data analysis more difficult.
In this article, we will be diving into the world of Data Imputation, discussing its importance and techniques, and also learning about Multiple Imputations.
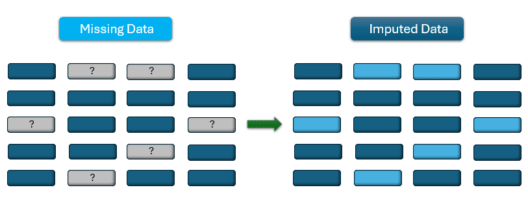
Data imputation is the method of filling in missing or unavailable information in a dataset with other numbers. This process is important for keeping data analysis accurate. If the data is incomplete, it can cause biased results and lower the quality of the information.
Imputation methods allow you to fill in missing information with possible values based on patterns found in the existing data. This helps to create a clearer and more complete analysis, making sure the data truly reflects the group or situation being examined.
Let us now learn the importance of Data imputation.
Now that we know what data imputation is, let’s look at why it matters.
We use imputation because lost data can cause these problems:
Distorts Dataset
When there is a lot of missing data, it can cause unusual patterns in how the data is distributed, which may affect the value of different categories in the dataset.
Limitations of Python Tools for Machine Learning
When utilizing ML libraries (SkLearn is the most popular), mistakes may occur because there is no automatic handling of these missing data.
Impacts on the Final Model
Missing data may lead to bias in the dataset, which could affect the final model’s analysis.
Desire to Restore the Entire Dataset
This usually happens when we want to keep all the data in our file because it is all important. Also, even though the dataset is not very big, removing some of it could greatly impact the end model.
Now that we understand why it’s important, let’s look at the different techniques and methods for Data Imputation.
Now that we understand what data imputation is and why it’s important, let’s explore some different methods for data imputation. Here are some data-filling methods that we will talk about in detail:
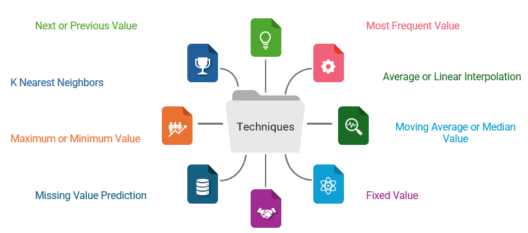
There are special methods for filling in missing values in time series or sorted data. These methods consider that in the sorted data, numbers that are close to each other are often more similar than those that are far apart.
A popular way to fill in missing values in a time series is to use the next or previous value. This approach works well for both names and numbers.
The goal is to find the k closest cases in the data where the feature value is available, and then replace the missing value with the most common value from that group.
If you know that your data must stay within a certain range (the minimum and maximum values), you can use either the minimum or maximum value to replace any missing data. This is useful if you understand that the measuring tool stops working or gives a fixed value when it goes beyond these limits.
For example, if a price limit has been reached in a financial market and trading has stopped, the missing price can be replaced with the lowest value allowed in that market.
Using a machine learning model to determine the final imputation value for characteristic x based on other features is another popular method for single imputation. The model is trained using the values in the remaining columns, and the rows in feature x without missing values are utilized as the training set.
Depending on the type of feature, we can employ any regression or classification model in this situation. In resistance training, the algorithm is used to forecast the most likely value of each missing value in all samples.
When there are missing values in multiple areas, we can use a simple method like filling in the average value to briefly replace those missing values. Then, the numbers in one column are set back to missing. After training, the model fills in the missing information. A model is trained for each trait with missing values until it can fill in all the gaps. What is GitHub Copilot? It is an AI-powered code completion tool built by GitHub and OpenAI that leverages large language models to assist developers by providing real-time code suggestions. In contexts like data imputation, GitHub Copilot can streamline model development by suggesting code snippets or algorithms, potentially optimizing the process of handling missing data in datasets.
The most common value in the column is used to replace the missing values in another popular method that is effective for both nominal and numerical features.
Average or linear interpolation finds missing values by calculating between the closest values before and after the missing data. It works like previous/next value estimation but is only used for numbers.
It’s important to sort the data correctly before doing any actions on it, especially for time series data, which should be sorted by timestamp.
Median, Mean, or rounded mean are further common imputation techniques for numerical features. In this case, the method fills in missing values with the average, rounded average, or middle value found for that feature in the entire dataset.
It’s better to use the median instead of the average when your data has a lot of outliers.
Fixed value imputation is a method that replaces missing data with a specific number. It can be used for any type of data. You can impute the null values in a survey using “not answered” as an example of using fixed imputation on nominal features.
We have learned about single imputation, why it matters, and how it works. Now, let’s move on to Multiple imputation.
Multiple imputation methods make several filled-in versions of missing data and examine them together. These methods take into account the uncertainty of filling in missing data and give more accurate results than just filling in once.
These methods usually use a lot of computing power and need more data to make good predictions.
Some of the common techniques used are:
Multivariate Imputation by Chained Equations (MICE)
MICE uses regression models to repeatedly guess and fill in missing values for each variable. It creates several filled-in datasets to provide strong results by considering the uncertainty in the filling-in process.
Bootstrap Imputation
This method makes several complete datasets from the original data by filling in any missing numbers in different ways. It accurately reflects both sampling and imputation uncertainties, making it a good choice when the dataset might not completely represent the whole community.
Markov Chain Monte Carlo (MCMC)
MCMC uses simulations to create sequences of new numbers for data that is missing. These sequences use the connections in the available data to create strong estimates for the missing values and handle uncertainty in that missing data.
Predictive Mean Matching (PMM)
PMM identifies observed data points with similar predicted values to the missing ones, based on regression modeling. It randomly selects one of these “donors” to impute the missing value, preserving the original dataset’s distribution and realism.
The following steps take place in multiple imputations:
Step 1: For each missing value in a data set, we make a set of n values that will be used to fill in the gap.
Step 2: Utilizing one of the n replacement ideas made in the previous item, a statistical analysis is carried out on each data set;
Step 3: The results are made by combining the data from different analyses.
We will now try to understand this in a better way by looking at an example.
A perfect example of Multiple Data Imputation is explained below.
Think about a study looking at how cholesterol levels are related to the chance of getting heart disease. Some participants in this study have missing cholesterol values. Several factors can affect the chances of having lost data.
For example, women might not have their cholesterol levels checked as often during routine visits. Older people usually have more medical tests recorded. People with unhealthy diets might skip testing altogether.
If we assume the missing data is random and we have cholesterol levels from a good mix of people based on gender, age, and eating habits, we can use a method called multiple imputation to fill in the missing information.
This means making several realistic datasets by predicting missing cholesterol values using patterns in the data and how they relate to other factors like age, gender, and food.
By looking at different sets of data, researchers can better understand the link between cholesterol levels and the chance of heart disease, while considering the gaps caused by missing information.
However, the process requires careful modeling and validation to ensure correct results. It’s a good idea to talk to a statistics expert before using multiple imputations regularly in medical studies.
Now that we’ve looked at an example of data replacement, let’s talk about why it’s important.
Why is Data Imputation Necessary?
Data imputation is essential in data analysis and machine learning for several reasons:
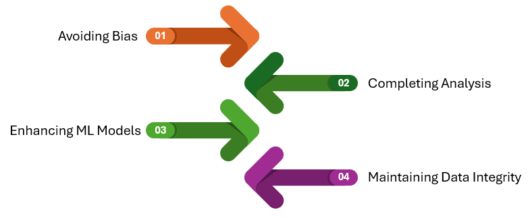
Avoiding Bias: Missing data can introduce major bias, leading to inaccurate conclusions. Imputation helps mitigate this by giving a more complete dataset.
Completing Analysis: Missing data can weaken the accuracy and trustworthiness of statistical studies. Imputation keeps the original number of samples, which helps ensure correct analysis and useful results.
Enhancing ML Models: Many machine learning methods need full samples to learn patterns well. Imputation makes sure that every variable has a value, which allows these methods to be used effectively.
Maintaining Data Integrity: Getting rid of data with missing values can make the dataset much smaller, which can lead to bias and make analysis harder. Imputation keeps most of the dataset’s information by replacing missing data with estimated numbers.
Now that we know why data imputation is important, let’s talk about the Challenges of Data Imputation.
While data imputation is a valuable technique for handling missing data, it is not without its challenges, including:
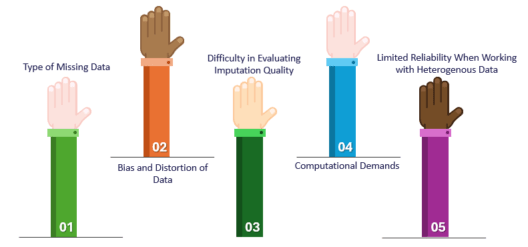
Type of Missing Data
The method of handling missing data depends on whether it’s MCAR, MAR, or MNAR. However, identifying the exact type can be tricky, as it often requires assumptions that may not always hold true.
Bias and Distortion of Data
Improper imputation can lead to bias, where the filled-in values don’t accurately represent the missing data. This could distort the results and lead to incorrect conclusions, so it’s crucial to choose the right imputation method.
Difficulty in Evaluating Imputation Quality
There is no sure way to verify if imputed values are correct. Since imputation assumes certain relationships between variables, if these assumptions are wrong, the imputed data could be inaccurate.
Computational Demands
Some advanced imputation methods can be resource-heavy, especially with large datasets. Balancing accuracy and computational efficiency requires expertise in both data science and the specific problem you’re solving.
Limited Reliability When Working with Heterogeneous Data
Dealing with different types of data (numerical, categorical, etc.) complicates the imputation process. It’s hard to find a one-size-fits-all approach that works well for all data types.
Data imputation methods can be used in many fields to fix problems caused by lost data. Here are some real-life examples of how these methods are used:
Healthcare Data Analysis
In healthcare, it’s common for patient records or test data to be lost. Imputation is a method used to fill in missing information, making sure that data analysis, like predicting patient results or spotting health trends, uses full sets of data.
This can make evaluations and treatment plans more accurate.
Customer Behavior Analysis
Businesses often have incomplete customer data, such as missing buy histories or demographic information. By filling in missing information, companies can better understand their customers, forecast future buying habits, and improve their marketing plans.
Financial Modeling
In finance, missing transaction data or incomplete market records can interfere with research. Imputation helps financial analysts fill in missing information, so they can correctly predict stock prices, assess risks, and calculate financial models even when not all data is available.
Survey Data Analysis
In polls, people might skip some questions, which results in incomplete data. Imputation helps fill in missing data, allowing researchers to analyze poll results more accurately and with less bias. This makes their conclusions about groups or behaviors more reliable. Generative AI Interview Questions often explore techniques like imputation, particularly in the context of how generative models can be used to predict and fill missing data in various domains.
In conclusion, filling in missing data is important for keeping statistics accurate and trustworthy. Imputation helps fill in missing information, which prevents errors and makes sure that the analysis leads to useful insights. It helps organizations make confident choices based on data. If you want to learn more about data science and AI, getting good at these methods can improve your abilities. Edureka’s Gen AI Master Program provides a complete learning journey to help you excel in data analysis and AI. You’ll gain the skills needed to turn raw data into effective strategies.
Related Posts:
1. What is the best way to impute data?
The best way to impute data depends on the data type, with mean/median for numerical data and mode for categorical data. Advanced methods like regression can offer more accuracy.
2. What are the two types of imputation?
The two types of imputation are single imputation, where missing values are replaced with one estimate, and multiple imputation, which creates several estimates to account for uncertainty.
3. What is the purpose of imputation?
The purpose of imputation is to fill in missing data, ensuring a complete dataset for accurate analysis and preventing biased results.
4. What is an example of imputation?
An example of imputation is replacing missing test scores with the average score of other students in the dataset.
5. What is the best method to collect data?










 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


