








Vision Language Models (VLMs) represent a substantial development in machine learning by merging computer vision with natural language processing (NLP) capabilities. By combining them, VLMs enable robots to do activities that require both visual and textual inputs. These models have been useful in a variety of applications, including picture captioning, visual question answering (VQA), and cross-modal search engines. The subject of Vision Language Models is quickly expanding and has sparked great research interest due to its ability to bridge gaps between multiple data modalities.
This page digs further into Vision Language Models, including their structure, technical components, common models, and applications. We will look at the obstacles these models confront, the benefits they provide, and how to utilize them successfully to solve real-world problems.
What are Open-Source Vision Language Models?

Open-source Vision Language Models are machine learning models that use visual and language input to predict or generate answers. Researchers and organizations make these models publicly available, allowing the larger machine-learning community to use, experiment with, and improve on them. Open-source models are often pre-trained on big datasets, allowing developers to fine-tune them for specific tasks or industries.
Key Features of Open-source VLMs:
- Public Accessibility: Models like CLIP and BLIP are available on platforms such as Hugging Face, allowing users to download and experiment with them for free.
- Pre-trained Models: These models are pre-trained on large-scale datasets, saving developers significant time and resources while also enabling the use of transfer learning.
- Flexibility and Adaptability: Open-source models are intended to be flexible to a wide variety of activities, including picture captioning and visual question answering.
Open-source VLMs democratize machine learning, allowing for research and development across a wide range of industries, including healthcare and autonomous driving.
Vision Language Models: Architectures and Popular Models
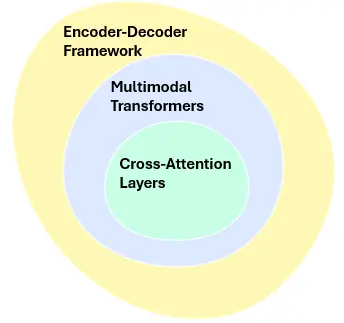

Vision Language Models are based on a variety of architectures, but the transformer model has emerged as the most used structure due to its ability to manage sequential data across several modalities. The key components of these models are:
- Encoder-Decoder Framework: A standard design that processes the visual and language components separately before combining them. The vision encoder (CNN or ViT) processes images, whereas the text encoder (BERT or GPT) handles text. These encoders extract features, which are subsequently combined using a decoder for further processing.
- Multimodal Transformers: The advent of transformers in multimodal learning enabled the simultaneous processing of visual and textual data. These transformers use cross-attention methods to harmonize the various data streams. For example, in Vision Transformers (ViT), images are separated into patches that are regarded as sequences, much like words in a phrase.
- Cross-Attention Layers: These layers help the model grasp the links between text and images. By addressing both modalities simultaneously, VLMs can align text and image representations into a single feature space for joint reasoning tasks.
Popular Vision Language Models:
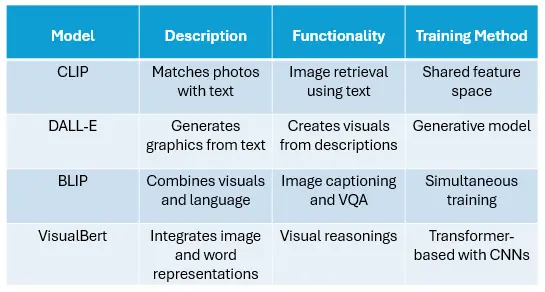
- CLIP (Contrastive Language-Image Pre-training): OpenAI created CLIP to match photos with descriptive text. It learns a shared feature space for text and images, allowing it to retrieve images using text descriptions or vice versa.
- DALL·E: A generative model that creates graphics from textual input. DALL·E shows how Vision Language Models may generate new visual material based on descriptions, in addition to interpreting images and text.
- BLIP (Bootstrapping Language-Image Pre-training): BLIP combines vision encoders and language decoders to enable applications such as image captioning and VQA. Its ability to train both simultaneously has contributed to its increasing popularity.
- VisualBERT: VisualBERT is a transformer-based model that combines picture and word representations for applications such as visual reasoning. It employs pre-trained language models such as BERT and incorporates visual data from CNNs.
Here is a brief comparison of all the visual models:

Finding the Right Vision Language Model
Choosing the appropriate Vision Language Model for your individual requirements is critical to reaching peak performance. Here are some things to consider:

- Task-Specific Needs: If your task is image captioning or visual question answering, certain models like BLIP or VisualBERT may be ideal. For cross-modal retrieval, models like CLIP are more suited.
- Model Performance: Assess models based on their capacity to generalize and perform effectively on the target goal. DALL·E excels at generation, while CLIP excels at retrieval and matching.
- Computational Resources: VLMs may be computationally expensive. Some models are more efficient than others, so select one that meets your resource limits.
- Available Data: Ensure that the model you select is consistent with the dataset you intend to utilize. Some VLMs require big datasets for effective fine-tuning, but others perform well with smaller datasets.
(Multimodal Model Universalization) MMMU


MMMU (Multimodal Model Universalization) is a methodology for developing models that can effectively handle many modalities at once. It helps to standardize tasks like image-text retrieval, VQA, and cross-modal reasoning across multiple applications. MMMU promotes multimodal learning, which supports the development of models that can work fluidly across domains and datasets, making them extremely versatile in real-world applications.
MMMU is an important notion for pushing the limits of what Vision Language Models can do, allowing researchers and developers to create more generalized systems.
MMBench


MMBench is a benchmarking tool that assesses the performance of Vision Language Models using a variety of measures. This application enables developers and researchers to evaluate the efficiency, scalability, and correctness of their models. The key evaluation metrics are:
- Task Accuracy: The model’s ability to complete certain tasks (for example, generating captions or answering questions).
- Computational Efficiency: The model’s resource-intensiveness during training and inference.
- Scalability: how well a model performs when applied to larger datasets or more complex tasks.
MMBench offers an objective way to compare models, making it easier to choose the best model for a given application.
Technical Details
Vision Language Models often rely on a number of technical components to process both visual and textual data:
- Preprocessing: The images and text are treated individually. Common picture approaches include scaling, normalization, and patching (for ViTs). Tokenization in text is the process of converting words into numerical tokens.
- Joint Embedding Space: After both modalities have been processed by their respective encoders, the features are mapped onto a common space. This enables the model to understand the links between text and images.
- Cross-Attention: Transformers allow the model to focus on specific sections of a picture or text dependent on the input. Cross-attention layers ensure that the model may focus on both modalities at the same time.
Using Vision Language Models with Transformers
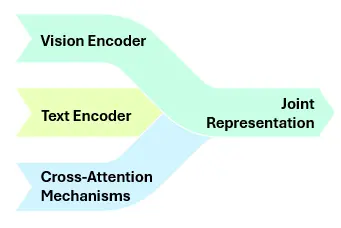

Transformers are the cornerstone of most Vision Language Models due to their ability to handle sequential data. Here’s how they operate:
- Vision Encoder: A CNN or ViT typically processes visual data, transforming it into meaningful features.
- Text Encoder: A pre-trained NLP model, such as BERT or GPT, transforms textual input into feature vectors.
- Cross-Attention Mechanisms: These mechanisms enable the model to align visual and textual representations, allowing the system to learn relationships between both modalities more efficiently.
- Joint Representation: The end output is a joint representation that embeds both picture and text features in a shared space, making tasks like image captioning, image-text matching, and VQA easier.
Evaluating Vision Language Models
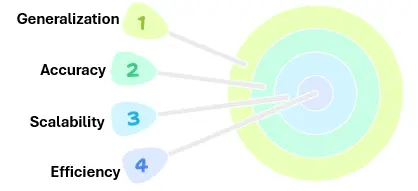

When analyzing Vision Language Models, consider the following critical metrics:
- Accuracy: How well the model performs on tasks like picture captioning, visual question responding, and cross-modal retrieval.
- Efficiency: Computational efficiency is critical, especially for real-time applications or when using constrained hardware.
- Scalability: Determine if the model can handle enormous datasets or difficult real-world challenges.
- Generalization: The model’s ability to adapt to new datasets or previously encountered jobs with minimal performance deterioration.
Datasets for Vision Language Models
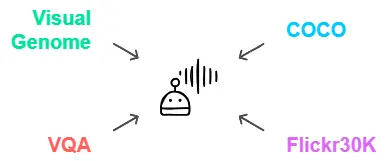

Vision Language Models require diverse and large datasets to learn accurate representations. Some key datasets include:
- COCO (Common Objects in Context): Contains photos and full captions; frequently used for image captioning model training.
- Flickr30K: A collection of 31,000 photos, each with five different captions, suitable for image captioning applications.
- VQA (Visual Question Answering): This dataset contains images as well as associated questions and answers, which are used to train models to respond to image-related inquiries.
- Visual Genome: A large dataset built for applications including item detection, relationship mapping, and scene comprehension.
Limitations of Vision Language Models
Despite their vast capacities, Vision Language Models have significant limitations:
- Biases in Data: Models trained on biased datasets may inherit those biases, resulting in distorted predictions and outcomes.
- Computer Demand: These models are resource-intensive, needing significant computer power for both training and inference, making them costly and difficult to deploy at scale.
- Limited Generalization: While these models excel at the tasks for which they were taught, they may struggle to generalize to new, previously untrained tasks or domains.
- Data Requirements: High-quality, diversified datasets are essential for training effective VLMs, but getting them can be expensive and time-consuming.
Applications of Vision Language Models
Vision Language Models have several practical applications across industries:
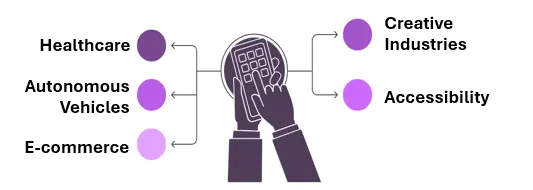

- Healthcare: analyzing medical images, creating detailed reports, and assisting with disease diagnosis.
- Autonomous Vehicles: By combining picture and textual data, autonomous systems can better perceive and interpret their surroundings.
- E-commerce: Allows for more efficient product search, recommendation algorithms, and graphic content development.
- Creative Industries: Using VLMs to generate creative outputs such as artwork, music, or video material in response to text cues.
- Accessibility: assisting visually impaired individuals by giving graphic explanations or interpreting their surroundings using voice commands.
Fine-tuning Vision Language Models with TRL
Fine-tuning enables you to customize a pre-trained Vision Language Model for a specific use case or dataset. TRL (Transformer Reinforcement Learning) is a fine-tuning technique that uses reinforcement learning to improve transformer models for vision-language problems. The process includes:
- Fine-tuning on Domain-Specific Data: Getting the model to perform well on a specific job, such as medical picture analysis or retail product recommendation.
- Performance Enhancement: TRL improves model performance by aligning it with task-specific needs, resulting in increased accuracy and efficiency.
Conclusion
Vision Language Models have transformed how robots interpret and generate visual and textual data. Models like CLIP, DALL·E, and BLIP have significantly improved image captioning, VQA, and image-text retrieval. VLMs, which combine transformers, cross-attention processes, and joint embedding spaces, are at the forefront of multimodal learning technology. While problems persist, including biases in data and computing costs, VLMs have broad potential applications across industries. By continuing to enhance these models and explore new ways to fine-tune them, we will be able to unlock even more powerful possibilities in the future. Those interested in diving deeper into the mechanics of generative AI and prompt design can explore this Generative AI and Prompt Engineering course, which covers the foundational and practical elements relevant to advancing VLM capabilities.