








Imagine you’re using Google Photos, and you search for “beach.” Instantly, it shows images of oceans, sand, sunsets—even if the word “beach” doesn’t appear in the photo name or description. How does it know?
Behind the scenes, Google Photos uses vector embeddings. It turns each photo into a numerical vector that captures its visual features. When you type “beach,” the system converts the query into a similar vector and compares it to image vectors, finding the closest ones. This magic is thanks to vector embeddings.
What is a vector?
A vector is a mathematical object that has magnitude and direction. In machine learning and data science, a vector is typically an ordered list of numbers that represent data points in a high-dimensional space.
vector = [0.5, 0.8, -0.3, 1.2]
This 4-dimensional vector can represent anything—text meaning, image features, audio signals, etc.
Now that we know what vectors are, let’s understand how we derive them from raw data—that’s where vector embeddings come in.
What are Vector embeddings?
A vector embedding is a numerical representation of data in a continuous vector space, designed to capture semantic or structural similarity between data points.


In NLP, embeddings capture word meaning.
In computer vision, embeddings capture visual features.
In recommender systems, embeddings capture user preferences.
They make it possible for ML models to work with text, images, audio, etc., by transforming them into a mathematical format.
With the concept in place, let’s explore the different types of vector embeddings.
Types of vector embeddings


Word Embeddings: (e.g., Word2Vec, GloVe)
Sentence Embeddings: (e.g., Sentence-BERT, Universal Sentence Encoder)
Image Embeddings: (e.g., ResNet, EfficientNet features)
Audio Embeddings: (e.g., VGGish)
Graph Embeddings: (e.g., Node2Vec, GraphSAGE)
Each type is tailored to its data domain but follows the same principle: represent meaningful information in vector space.
So how exactly are these embeddings generated? Let’s unpack the process.
How does vector embedding work?
The process usually involves a deep learning model trained to learn and project features into vector space.
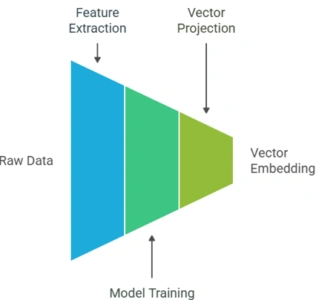

Text: A word is passed through a neural network (e.g., Word2Vec) which learns to predict surrounding words.
Images: A CNN processes the image and its internal activations become the embedding.
Audio: Waveforms are fed into models that capture frequency & time patterns.
You might wonder, are vectors and embeddings the same? Let’s clarify that.
Are embeddings and vectors the same thing?
Not exactly.
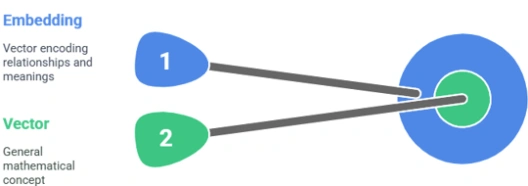

A vector is a general mathematical concept.
An embedding is a specific kind of vector that encodes relationships and meanings in a learned space.
All embeddings are vectors, but not all vectors are embeddings.
Now let’s see how we can create these embeddings in practice.
Creating Vector Embeddings
For Text:
import spacy
nlp = spacy.load("en_core_web_md")
doc = nlp("I love machine learning.")
print(doc.vector) # 300-d vector
For Images:
from torchvision import models, transforms
from PIL import Image
import torch
model = models.resnet18(pretrained=True)
model = torch.nn.Sequential(*list(model.children())[:-1])
model.eval()
img = Image.open("cat.jpg")
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
img_tensor = transform(img).unsqueeze(0)
embedding = model(img_tensor).squeeze().detach().numpy()
print(embedding.shape) # e.g., (512,)
Now that we know how to create embeddings, let’s dive into an end-to-end image example.
Example: Image Embedding with a Convolutional Neural Network
Let’s say you want to build an image similarity search engine.

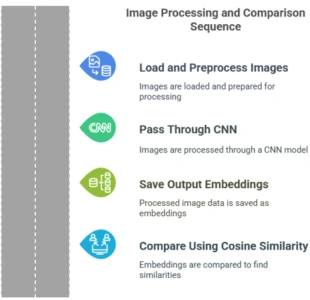
Steps:
Load and preprocess your images.
Pass them through a CNN like ResNet.
Save the output embeddings.
Compare them using cosine similarity.
Here is the code snippet you can refer to:
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity([embedding1], [embedding2])
print(f"Similarity: {similarity[0][0]:.2f}")
Using Vector Embeddings
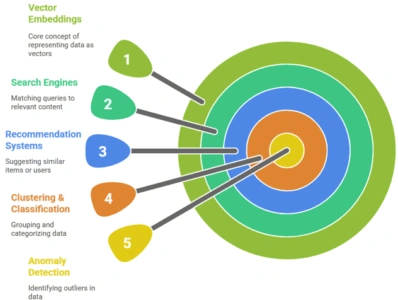

Search Engines: Match queries to documents/images.
Recommendation Systems: Find similar users or items.
Clustering & Classification: Apply k-means or SVM on embeddings.
Anomaly Detection: Spot outliers in vector space.
But how exactly are these embeddings created by models?
How are vector embeddings created?
Through training, usually using:
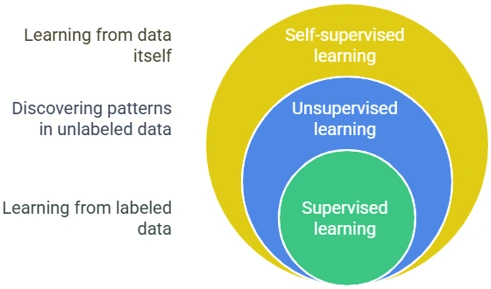

Supervised learning: Trained on labeled data.
Unsupervised learning: Autoencoders, Word2Vec.
Self-supervised learning: Contrastive learning (e.g., SimCLR, BYOL).
Curious what embeddings “look like”? Let’s visualize.
What does vector embedding look like?
You can visualize high-dimensional vectors using t-SNE or UMAP:
</p>
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(n_components=2)
reduced = tsne.fit_transform(vectors)
plt.scatter(reduced[:,0], reduced[:,1])
plt.title("t-SNE Visualization of Embeddings")
plt.show()
Applications of vector embeddings
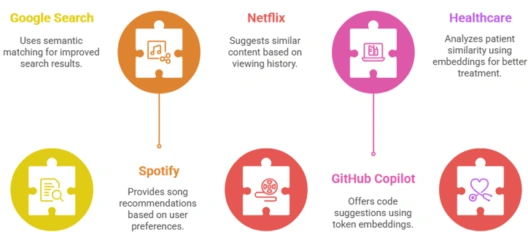

Google Search: Semantic matching
Spotify: Song recommendations
Netflix: Similar content recommendations
GitHub Copilot: Code suggestion using token embeddings
Healthcare: Patient similarity analysis using embeddings
Let’s explore vector embeddings for specific domains like images and NLP.
Vector embedding for images
CNNs (ResNet, EfficientNet) extract feature maps.
Can be used for:
Similar image retrieval
Clustering similar images
Transfer learning
What about text and language?
Vector embedding for NLP
Popular models:
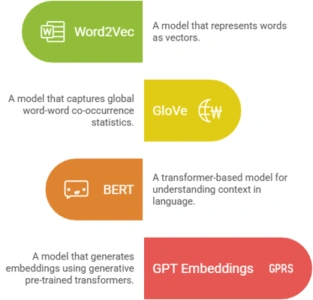

Word2Vec
GloVe
BERT
GPT Embeddings
Use cases:
Sentiment analysis
Semantic search
Chatbots
Here is the code snippet you can refer to:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
embedding = model.encode("Machine learning is fun.")
Once you have embeddings, where do you store and search them? Enter vector databases.
Vector databases
Vector databases are designed to store, index, and search high-dimensional embeddings efficiently.
Popular ones:
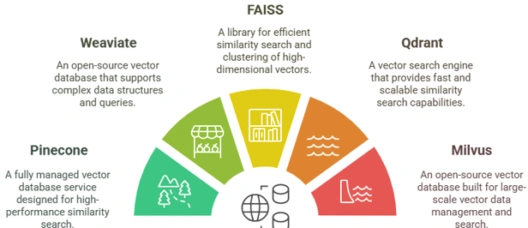

Pinecone
Weaviate
FAISS
Qdrant
Milvus
They use Approximate Nearest Neighbor (ANN) algorithms for fast search.
Let’s wrap up everything we’ve covered.
Conclusion
Vector embeddings are the lingua franca of machine learning. They convert raw data—text, images, audio—into a universal format that models can understand and reason over. They power everything from search to recommendation to generative AI. Understanding and leveraging embeddings is a superpower for any developer, ML engineer, or researcher.
If you want certifications in Generative AI and large language models, Edureka offers the best certifications and training in this field.
- Generative AI introduction
- Generative AI Course
- Generative AI in Software Development
- Mastering Generative AI tools
- Prompt Engineering Course
For a wide range of courses, training, and certification programs across various domains, check out Edureka’s website to explore more and enhance your skills!
FAQs
1. Are embeddings always fixed-size?
Yes, for a given model. BERT gives 768-d vectors, ResNet might give 512-d, etc.
2. Can I fine-tune embeddings?
Yes. You can fine-tune embedding models for your domain.
3. Are vector embeddings used in LLMs?
Yes, they are the backbone of attention and token representations.
4. Can embeddings be visualized?
Yes, using t-SNE or UMAP.
5. Do vector embeddings store data?
No. They store a representation of the data in a compact form.