Shubham SinhaShubham Sinha is a Big Data and Hadoop expert working as a...Shubham Sinha is a Big Data and Hadoop expert working as a Research Analyst at Edureka. He is keen to work with Big Data...
In today’s fast-paced IT world, where technologies are evolving rapidly, a voluminous amount of data is generated every day. Because of this increase in data, more and more organizations are adopting the Big Data technologies like Hadoop, Spark, Kafka, etc for storing and analyzing Big Data. Therefore, the job opportunities regarding these technologies are also increasing at a faster pace. This results in demand for professionals with Big Data Certification. Let’s take a look at some predictions:
Table of Content
Big Data & Hadoop Market is expected to reach $99.31B by 2022 growing at a CAGR of 42.1% from 2015 – Forbes
McKinsey predicts that by 2018 there will be a shortage of 1.5M data experts – McKinsey Report
The average salary for Big Data Hadoop Developer is $135k – Indeed.com Salary Data.
But, why do you need the Big Data Certification?
If you complete Edureka’s Hadoop Certification, you are recognized in the industry as a capable and a qualified Big Data expert. This Big data analytics certification helps your career in a rapid manner among the Top MultinationalCompanies. It would give you a preference and add value to your resume, which will help you in grabbing job opportunities in the field of Big Data & Hadoop. There are two major Big Data certifications in Hadoop, namely Cloudera and Hortonworks.
In this Big Data Hadoop blog, I will be discussing in detail about different Big Data certifications offered by Edureka, Cloudera and Hortonworks in the following sequence:
Big Data Certification | Cloudera Certification | Edureka
Edureka Big Data Certification Online Training
Edureka provides 3 Big Data Hadoop certification training related to Big Data & Hadoop.
Edureka Big Data Hadoop Certification Training
Hadoop Administration Certification Training
Apache Spark Certification Training
Edureka Big Data Hadoop Certification Training
The Hadoop training is designed to make you a certified Big Data practitioner by providing you rich hands-on training on Hadoop ecosystem and best practices about HDFS, MapReduce, HBase, Hive, Pig, Oozie, Sqoop. This Big Data certification course is stepping stone to your Big Data journey and you will get the opportunity to work on multiple Big data & Hadoop projects with different data sets like social media, customer complaints, airlines, movie, loan datasets etc.
You will also get Edureka Big data Hadoop certification after the project completion, which will add value to your resume. Based on the Edureka training and it’s aligned de facto curriculum, you can easily clear Cloudera or Hortonworks certification.
Big Data Hadoop Course Description
During this Big Data Certification course, our expert instructors will train you to:
Master the concepts of HDFS and MapReduce framework
Understand Hadoop 2.x Architecture
Setup Hadoop Cluster and write Complex MapReduce programs
Learn data loading techniques using Sqoop and Flume
Perform data analytics using Pig, Hive, and YARN
Implement HBase and MapReduce integration
Implement Advanced Usage and Indexing
Schedule jobs using Oozie
Implement best practices for Hadoop development
Understand Spark and its Ecosystem
Learn how to work in RDD in Spark
Work on a real-life Project on Big Data Analytics
Edureka also provides the Hadoop Training in Bangalore which covers a similar curriculum, updated as per industry de facto, and helps you in clearing the Cloudera & Hortonworks Hadoop certifications quite easily.
Big Data Hadoop Course Curriculum
This best Big Data certification course is divided into modules and in each module, you will be learning new Big Data tools & architectures. Let us know what topics are covered in which module:
Understanding Big Data and Hadoop – In this module, you will understand Big Data, the limitations of the existing solutions for Big Data problem, how Hadoop solves the Big Data problem, the common Hadoop ecosystem components, Hadoop Architecture, HDFS, Anatomy of File Write and Read, how MapReduce Framework works.
Hadoop Architecture and HDFS – In this module, you will learn the Hadoop Cluster Architecture, Important Configuration files in a Hadoop Cluster, Data Loading Techniques, how to setup single node and multi-node Hadoop cluster.
Hadoop MapReduce Framework – In this module, you will understand Hadoop MapReduce framework and the working of MapReduce on data stored in HDFS. You will understand concepts like Input Splits in MapReduce, Combiner & Partitioner and Demos on MapReduce using different datasets.
Advanced MapReduce – In this Big Data certifications module, you will learn Advanced MapReduce concepts such as Counters, Distributed Cache, MRunit, Reduce Join, Custom Input Format, Sequence Input Format and XML parsing.
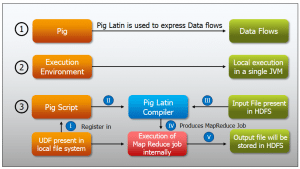
Pig– In this module, you will learn Pig, types of use case we can use Pig, tight coupling between Pig and MapReduce, and Pig Latin scripting, PIG running modes, PIG UDF, Pig Streaming, Testing PIG Scripts. Demo on healthcare dataset.
Hive– This Big Data Engineering course module will help you in understanding Hive concepts, Hive Data types, Loading and Querying Data in Hive, running hive scripts and Hive UDF.
Advanced Hive and HBase – In this module, you will understand Advanced Hive concepts such as UDF, Dynamic Partitioning, Hive indexes and views, optimizations in Hive. You will also acquire in-depth knowledge of HBase, HBase Architecture, running modes and its components.
Advanced HBase – This module will cover Advanced HBase concepts. We will see demos on Bulk Loading, Filters. You will also learn what Zookeeper is all about, how it helps in monitoring a cluster, why HBase uses Zookeeper.
Processing Distributed Data with Apache Spark – In this Best Big Data certification course module, you will learn Spark ecosystem and its components, how Scala is used in Spark, SparkContext. You will learn how to work in RDD in Spark. The demo will be there on running application on Spark Cluster, Comparing the performance of MapReduce and Spark.
Oozie and Hadoop Project – In this module, you will understand the working of multiple Hadoop ecosystem components together in a Hadoop implementation to solve Big Data problems. We will discuss multiple datasets and specifications of the project. This module will also cover Flume & Sqoop demo, Apache Oozie Workflow Scheduler for Hadoop Jobs, and Hadoop Talend integration.
As we looked at the Hadoop certification exams, so you need a good hands-on practice to clear the Hadoop certification exams. Thus, we provide various projects that you can work on and get a clear idea about the practical implementation. Towards the end of this Big Data certification Online course, you will work on a live project where you will be using PIG, HIVE, HBase, and MapReduce to perform Big Data analytics. Few Big Data Hadoop certification projects you will be going through are: The best way to become a Data Engineer si by getting the Azure Data Engineering Course in Chennai.
Project #1: Analyze social bookmarking sites to find insights
Data: It comprises of the information gathered from sites like reddit.com, stumbleupon.com which are bookmarking sites and allow you to bookmark, review, rate, search various links on any topic.reddit.com, stumbleupon.com, etc.
Problem Statement: Analyze the data in the Hadoop ecosystem to:
Fetch the data into HDFS and analyze it with the help of MapReduce, Pig, and Hive to find the top rated links based on the user comments, likes etc.
Using MapReduce, convert the semi-structured format (XML data) into a structured format and categorize the user rating as positive and negative for each of the thousand links.
Push the output into HDFS and then feed it into PIG, which splits the data into two parts: Category data and Rating data.
Write a fancy Hive Query to analyze the data further and push the output into a relational database (RDBMS) using Sqoop.
Project #2: Customer Complaints Analysis
Data: Publicly available dataset, containing a few lakh observations with attributes like; CustomerId, Payment Mode, Product Details, Complaint, Location, Status of the complaint, etc.
Problem Statement: Analyze the data in the Hadoop ecosystem to:
Get the number of complaints filed under each product
Get the total number of complaints filed from a particular location
Get the list of complaints grouped by location which has no timely response
Project #3: Tourism Data Analysis
Data: The dataset comprises attributes like City pair (combination of from and to), adults traveling, seniors traveling, children traveling, air booking price, car booking price, etc.
Problem Statement: Find the following insights from the data:
Top 20 destinations people frequently travel to, based on the given data we can find the most popular destinations where people travel frequently, based on the specific initial number of trips booked for a particular destination
Top 20 locations from where most of the trips start based on booked trip count
Top 20 high air-revenue destinations, i.e the 20 cities that generate high airline revenues for travel, so that the discount offers can be given to attract more bookings for these destinations.
Project #4: Airline Data Analysis
Data: Publicly available dataset which contains the flight details of various airlines such as Airport id, Name of the airport, Main city served by airport, Country or territory where the airport is located, Code of Airport, Decimal degrees, Hours offset from UTC, Timezone, etc.
Problem Statement: Analyze the airlines data to:
Find list of airports operating in the country
Find the list of airlines having zero stops
List of airlines operating with code share
Which country (or) territory has the highest number of airports
Find the list of active airlines in the United States
Project #5: Analyze Loan Dataset
Data: Publicly available dataset which contains complete details of all the loans issued, including the current loan status (Current, Late, Fully Paid, etc.) and latest payment information.
Problem Statement:
Find the number of cases per location and categorize the count with respect to the reason for taking a loan and display the average risk score.
Project #6: Analyze Movie Ratings
Data: Publicly available data from sites like rotten tomatoes, IMDB, etc.
Problem Statement: Analyze the movie ratings by different users to:
Get the user who has rated the most number of movies
Get the user who has rated the least number of movies
Get the count of total number of movies rated by user belonging to a specific occupation
Get the number of underage users
Project #7: Analyze YouTube data
Data: It is about the YouTube videos and contains attributes such as VideoID, Uploader, Age, Category, Length, views, ratings, comments, etc.
Problem Statement:
Identify the top 5 categories in which the most number of videos are uploaded, the top 10 rated videos, and the top 10 most viewed videos.
Edureka Hadoop Administration Certification Training
The Hadoop Administration Training from Edureka provides participants an expertise in all the steps necessary to operate and maintain a Hadoop cluster, i.e. from Planning, Installation and Configuration through load balancing, Security and Tuning. The Edureka’s training will provide hands-on preparation for the real-world challenges faced by Hadoop Administrators. Among Various Big data certification courses, this Hadoop Administration is most recommended for Beginners.
Hadoop Admin Course Description
The course curriculum follows Apache Hadoop distribution. During the Hadoop Administration Online training, you’ll master:
Hadoop Architecture, HDFS, Hadoop Cluster and Hadoop Administrator’s role
Plan and Deploy a Hadoop Cluster
Load Data and Run Applications
Configuration and Performance Tuning
How to Manage, Maintain, Monitor and Troubleshoot a Hadoop Cluster
Cluster Security, Backup and Recovery
Insights on Hadoop 2.0, Name Node High Availability, HDFS Federation, YARN, MapReduce v2
Oozie, Hcatalog/Hive, and HBase Administration and Hands-On Project
Hadoop Admin Training Projects
Towards the end of the Course, you will get an opportunity to work on a live project, that will use the different Hadoop ecosystem components to work together in a Hadoop implementation to solve big data problems.
Find out the location of the node to which it went.
Find in which data node the output files are written.
3. Create a large text file and copy to HDFS with a block size of 256 MB.
Keep all the other files in default block size and find how block size has an impact on the performance.
4. Set a spaceQuota of 200MB for projects and copy a file of 70MB with replication=2
Identify the reason the system is not letting you copy the file?
How will you solve this problem without increasing the spaceQuota?
5. Configure Rack Awareness and copy the file to HDFS
Find its rack distribution and identify the command used for it.
Find out how to change the replication factor of the existing file.
The last Big Data certification training provided by Edureka is solely based on Apache Spark. Lets us know the details.
Edureka Apache Spark Certification Training
This Apache Spark Certification Training will enable learners to understand how Spark executes in-memory data processing and runs much faster than Hadoop MapReduce. Learners will master Scala programming and will get trained on different APIs which Spark offers such as Spark Streaming, Spark SQL, Spark RDD, Spark MLlib and Spark GraphX. After completing this Big Data certification course, you will completely understand about the concepts of OOPS.
Apache Spark Course Description
This Edureka course is an integral part of Big Data developer’s learning path. After completing the Apache Spark training, you will be able to:
Understand Scala and its implementation
Master the concepts of Traits and OOPS in Scala programming
Install Spark and implement Spark operations on Spark Shell
Understand the role of Spark RDD
Implement Spark applications on YARN (Hadoop)
Learn Spark Streaming API
Implement machine learning algorithms in Spark MLlib API
Analyze Hive and Spark SQL architecture
Understand Spark GraphX API and implement graph algorithms
Implement Broadcast variable and Accumulators for performance tuning
Projects
Apache Spark Training Projects
In Spark Hadoop Big Data certification Training, Edureka has multiple projects, few of them are:
Project #1: Design a system to replay the real-time replay of transactions in HDFS using Spark.
Technologies Used:
Spark Streaming
Kafka (for messaging)
HDFS (for storage)
Core Spark API (for aggregation)
Project #2: Drop-page of signal during Roaming
Problem Statement: You will be given a CDR (Call Details Record) file, you need to find out top 10 customers facing frequent call drops in Roaming. This is a very important report which telecom companies use to prevent customer churn out, by calling them back and at the same time contacting their roaming partners to improve the connectivity issues in specific areas.
So while going through Edureka Big Data Certification course training, you will be working on multiple use-cases as well as real time scenarios, which will help you in clearing various Hadoop certifications offered by Cloudera and Hortonworks.
Cloudera Certifications
The CCA exams test your basic foundation skills and set forth the groundwork for a candidate to get certified in CCP program.Edureka’s Big Data certification course helps you to get deep learning about all the Big Data tools and application. Cloudera has 3 certification exam at CCA level (Cloudera Certified Associate).
The person clearing the CCA Spark and Hadoop Developer certification has proven his core skills to ingest, transform, and process data using Apache Spark and core Cloudera Enterprise tools. The basic details for appearing CCA 175 are:
Number of Questions: 8–12 performance-based (hands-on) tasks on Cloudera Enterprise cluster
Time Limit: 120 minutes
Passing Score: 70%
Price: USD $295
Each CCA question requires you to solve a particular scenario. In some cases, a tool such as Impala or Hive may be used and in other cases, coding is required. In order to speed up development time of Spark questions, a template is often provided that contains a skeleton of the solution, asking the candidate to fill in the missing lines of functional code. This template is written in either Scala or Python.
It is not mandatory to use the template. You may solve the scenario using a programming language. But however, you should be aware that coding every problem from scratch may take more time than is allocated for the exam.
Your exam is graded immediately upon submission and you are e-mailed a score report the same day of your exam. Your score report displays the problem number for each problem you attempted and a grade on that problem. If you pass the exam, you receive a second e-mail within a few days of your exam with your digital certificate as a PDF, your license number, a LinkedIn profile update, and a link to download your CCA logos for use in your social media profiles. It is easy to pass the CCA exam after you have completed this Edureka’s Big data certification training course developed by top experts in the Hadoop platform. Learn more about Big Data and its applications from the Data Engineering Training
Now, let us know the required skill set for clearing CCA 175 certification.
Required Skills:
Data Ingest
The skills to transfer data between external systems and your cluster. This includes the following:
Import data from a MySQL database into HDFS using Sqoop
Export data to a MySQL database from HDFS using Sqoop
Change the delimiter and file format of data during import using Sqoop
Ingest real-time and near-real-time streaming data into HDFS
Process streaming data as it is loaded onto the cluster
Load data into and out of HDFS using the Hadoop File System commands
Transform, Stage, and Store
The skill to convert a set of data values, which is stored in HDFS into new data values or a new data format and write them into HDFS.
Load RDD data from HDFS for use in Spark applications
Write the results from an RDD back into HDFS using Spark
Read and write files in a variety of file formats
Perform standard extract, transform, load (ETL) processes on data
Data Analysis
Use Spark SQL to interact with the metastore programmatically in your applications. Generate reports by using queries against loaded data.
Use metastore tables as an input source or an output sink for Spark applications
Understand the fundamentals of querying datasets in Spark
Filter data using Spark
Write queries that calculate aggregate statistics
Join disparate datasets using Spark
Produce ranked or sorted data
Let’s move ahead and look at the second Cloudera certification i.e., CCA Data Analyst.
CCA Data Analyst
Person clearing CCA Data Analyst certification has proven his core analyst skills to load, transform, and model Hadoop data in order to define relationships and extract meaningful results from the raw input. The basic details for appearing CCA Data Analyst are:
Number of Questions: 8–12 performance-based (hands-on) tasks on CDH 5 cluster
Time Limit: 120 minutes
Passing Score: 70%
Language: English
For each problem, you must implement a technical solution with a high degree of precision that meets all the requirements. You may use any tool or combination of tools on the cluster. You must possess enough knowledge to analyze the problem and arrive at an optimal approach given the time allowed.
Below are the required skill set for clearing CCA Data Analyst certification.
Required Skills:
Prepare the Data
Use Extract, Transfer, Load (ETL) processes to prepare data for queries.
Import data from a MySQL database into HDFS using Sqoop
Export data to a MySQL database from HDFS using Sqoop
Move data between tables in the metastore
Transform values, columns, or file formats of incoming data before analysis
Provide Structure to the Data
Use Data Definition Language (DDL) statements to create or alter structures in the metastore for use by Hive and Impala.
Create tables using a variety of data types, delimiters, and file formats
Create new tables using existing tables to define the schema
Improve query performance by creating partitioned tables in the metastore
Alter tables to modify existing schema
Create views in order to simplify queries
Data Analysis
Use Query Language (QL) statements in Hive and Impala to analyze data on the cluster.
Prepare reports using SELECT commands including unions and subqueries
Calculate aggregate statistics, such as sums and averages, during a query
Create queries against multiple data sources by using join commands
Transform the output format of queries by using built-in functions
Perform queries across a group of rows using windowing functions
Candidates for CCA Data Analyst can be SQL developers, data analysts, business intelligence specialists, developers, system architects, and database administrators. There are no prerequisites.
Now, let us discuss the third Cloudera Hadoop Big Data certifications i.e. CCA Administrator.
CCA Administrator Exam (CCA131)
Individuals who earn the CCA Administrator certification have demonstrated the core systems and cluster administrator skills sought by companies and organizations deploying Cloudera in the enterprise.
Number of Questions: 8–12 performance-based tasks on pre-configured Cloudera Enterprise cluster
Time Limit: 120 minutes
Passing Score: 70%
Language: English
Price: USD $295
Each CCA question requires you to solve a particular scenario. Some of the tasks require making configuration and service changes via Cloudera Manager, while others demand knowledge of command line Hadoop utilities and basic competence with the Linux environment. Evaluation & Score Reporting are similar as CCA 175 certification. After completing Edureka’s Big Data Certification course developed by top industryexperts, you will get a deep knowledge of Big Data tools and technologies. The required skill set is as follows:
Required Skills:
Install
Demonstrate an understanding of the installation process for Cloudera Manager, CDH, and the ecosystem projects.
Set up a local CDH repository
Perform OS-level configuration for Hadoop installation
Install Cloudera Manager server and agents
Install CDH using Cloudera Manager
Add a new node to an existing cluster
Add a service using Cloudera Manager
Configure
Perform basic and advanced configuration needed to effectively administer a Hadoop cluster
Configure a service using Cloudera Manager
Create an HDFS user’s home directory
Configure NameNode HA
Configure ResourceManager HA
Configure proxy for Hiveserver2/Impala
Manage
Maintain and modify the cluster to support day-to-day operations in the enterprise
Rebalance the cluster
Set up alerting for excessive disk fill
Define and install a rack topology script
Install new type of I/O compression library in cluster
Revise YARN resource assignment based on user feedback
Commission/decommission a node
Secure
Enable relevant services and configure the cluster to meet goals defined by security policy; demonstrate knowledge of basic security practices
Configure HDFS ACLs
Install and configure Sentry
Configure Hue user authorization and authentication
Enable/configure log and query reduction
Create encrypted zones in HDFS
Test
Benchmark the cluster operational metrics, test system configuration for operation and efficiency
Execute file system commands via HTTP-FS
Efficiently copy data within a cluster/between clusters
Create/restore a snapshot of an HDFS directory
Get/set ACLs for a file or directory structure
Benchmark the cluster (I/O, CPU, network)
Troubleshoot
Demonstrate ability to find the root cause of a problem, optimize inefficient execution, and resolve resource contention scenarios
Resolve errors/warnings in Cloudera Manager
Resolve performance problems/errors in cluster operation
Determine reason for application failure
Configure the Fair Scheduler to resolve application delays
These were the three Hadoop Big Data Certifications of Cloudera related to Hadoop. Further moving on, let us discuss the Hortonworks certifications.
Hortonworks Certifications
There are five Big Data certifications provided by Hortonworksrelated to Hadoop:
HDP CERTIFIED JAVA DEVELOPER (HDPCD-Java): for developers who design, develop and architect Hadoop-based solutions written in the Java programming language.
HORTONWORKS CERTIFIED ASSOCIATE (HCA): for an entry point and fundamental skills required to progress to the higher levels of the Hortonworks certification program.
The cost of the exam is $250 USD per attempt and the duration is 2 hours. Hortonworks has a dynamic marking scheme based on the question you are attempting and the approach taken by you. So, now we will focus on the required skill for clearing different Hortonworks certifications.Edureka’s Big Data certifications is the first step to clear all this Hortonworks certification with more knowledge about the topics
Required Skills:
HDPCD Exam
Data Ingestion
SQOOP-IMPORT: Import data from a table in a relational database into HDFS
FREE-FORM QUERY IMPORTS: Import the results of a query from a relational database into HDFS
IMPORTING DATA INTO HIVE: Import a table from a relational database into a new or existing Hive table
SQOOP-EXPORT: Insert or update data from HDFS into a table in a relational database
FLUME AGENT: Given a Flume configuration file, start a Flume agent
MEMORY CHANNEL: Given a configured sink and source, configure a Flume memory channel with a specified capacity
Data Transformation
Write and execute a Pig script
Load data into a Pig relation without a schema
Load data into a Pig relation with a schema
Load data from a Hive table into a Pig relation
Use Pig to transform data into a specified format
Transform data to match a given Hive schema
Group the data of one or more Pig relations
Use Pig to remove records with null values from a relation
Store the data from a Pig relation into a folder in HDFS
Store the data from a Pig relation into a Hive table
Sort the output of a Pig relation
Remove the duplicate tuples of a Pig relation
Specify the number of reduce tasks for a Pig MapReduce job
Join two datasets using Pig
Perform a replicated join using Pig
Run a Pig job using Tez
Within a Pig script, register a JAR file of User Defined Functions
Within a Pig script, define an alias for a User Defined Function
Within a Pig script, invoke a User Defined Function
Data Analysis
Write and execute a Hive query
Define a Hive-managed table
Define a Hive external table
Define a partitioned Hive table
Define a bucketed Hive table
Define a Hive table from a select query
Define a Hive table that uses the ORCFile format
Create a new ORCFile table from the data in an existing non-ORCFile Hive table
Specify the storage format of a Hive table
Specify the delimiter of a Hive table
Load data into a Hive table from a local directory
Load data into a Hive table from an HDFS directory
Load data into a Hive table as the result of a query
Load a compressed data file into a Hive table
Update a row in a Hive table
Delete a row from a Hive table
Insert a new row into a Hive table
Join two Hive tables
Run a Hive query using Tez
Run a Hive query using vectorization
Output the execution plan for a Hive query
Use a subquery within a Hive query
Output data from a Hive query that is totally ordered across multiple reducers
Set a Hadoop or Hive configuration property from within a Hive query
HDPCA EXAM
Installation
Configure a local HDP repository
Install Ambari-server and Ambari-agent
Install HDP using the Ambari install wizard
Add a new node to an existing cluster
Decommission a node
Add an HDP service to a cluster using Ambari
Configuration
Define and deploy a rack topology script
Change the configuration of a service using Ambari
Configure the Capacity Scheduler
Create a home directory for a user and configure permissions
Configure the include and exclude DataNode files
Troubleshooting
Restart an HDP service
View an application’s log file
Configure and manage alerts
Troubleshoot a failed job
High Availability
Configure NameNode HA
Configure ResourceManager HA
Copy data between two clusters using distcp
Create a snapshot of an HDFS directory
Recover a snapshot
Configure HiveServer2 HA
Security
Install and configure Knox
Install and configure Ranger
Configure HDFS ACLs
HDPCD: JAVA EXAM
Write a Hadoop MapReduce application in Java
Run a Java MapReduce application on a Hadoop cluster
Write and configure a Combiner for a MapReduce job
Write and configure a custom Partitioner for a MapReduce job
Sort the output of a MapReduce job
Write and configure a custom key class for a MapReduce job
Configure the input and output formats of a MapReduce job
Perform a join of two or more datasets
Perform a map-side join of two datasets
HDPCD: SPARK EXAM
Core Spark
Write a Spark Core application in Python or Scala
Initialize a Spark application
Run a Spark job on YARN
Create an RDD
Create an RDD from a file or directory in HDFS
Persist an RDD in memory or on disk
Perform Spark transformations on an RDD
Perform Spark actions on an RDD
Create and use broadcast variables and accumulators
Configure Spark properties
Spark SQL
Create Spark DataFrames from an existing RDD
Perform operations on a DataFrame
Write a Spark SQL application
Use Hive with ORC from Spark SQL
Write a Spark SQL application that reads and writes data from Hive tables
Now, as we know the required skill sets and exam pattern to clear various Hadoop certifications. Thus, you can choose among three Edureka’s Hadoop Certification Training programs based on the Hadoop certification you want to pursue. Edureka Big Data training curriculum is aligned with Cloudera & Hortonworks Hadoop certifications.
I hope this Big Data Certification blog was informative and helped in gaining an idea about various Hadoop certification and their training. Now go ahead, choose a Big Data Certification and get certified in Big Data Hadoop which will boost your professional career. All The Best!
Edureka is a live and interactive e-learning platform that is revolutionizing professional online education. It offers instructor-led courses supported by online resources, along with 24×7 on-demand support. Edureka Data Engineer Certification courses are specially curated by experts who monitor the IT industry with a hawk’s eye, and respond to the expectations, changes, and requirements from the industry and incorporate them into the courses.
Now that you know various Big Data Hadoop Certifications, check out the Hadoop Training in Chennai by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
I have done data analytic course. This course is completely hands-on. Data analytics certification course is a very good course for the future. Data and big data analytics are the lifeblood of any successful business. The Big Data technologies and initiatives are rising to analyze this data for gaining insights that can help in making strategic decisions. Big Data analytics involves the use of analytics techniques like machine learning, data mining, natural language processing, and statistics. I have done this course from Virginia Institute of Finance. It is a very good Institute for a beginner.






 Copy Link!
Copy Link!




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








I have done data analytic course. This course is completely hands-on. Data analytics certification course is a very good course for the future. Data and big data analytics are the lifeblood of any successful business. The Big Data technologies and initiatives are rising to analyze this data for gaining insights that can help in making strategic decisions. Big Data analytics involves the use of analytics techniques like machine learning, data mining, natural language processing, and statistics. I have done this course from Virginia Institute of Finance. It is a very good Institute for a beginner.
Thank You guys for providing such great stuff. I watched Big Data Videos on YouTube, They are amazing.
Hey Bhagyesh, we are glad you feel this way. Do subscribe and stay connected with us. Cheers!