Ashutosh PandeyGenerative AI enthusiast with expertise in RAG (Retrieval-Augmented Generation) and LangChain, passionate...Generative AI enthusiast with expertise in RAG (Retrieval-Augmented Generation) and LangChain, passionate about building intelligent AI-driven solutions
An innovative artificial intelligence model, Stable Diffusion, can turn plain text into beautiful, high-quality pictures. This open-source application has revolutionized AI-driven creativity with its powerful deep-learning techniques. Stable Diffusion makes it easy and efficient—even on consumer-grade hardware—to generate original artwork, improve current photos, or investigate novel applications. This blog post will explain the inner workings of Stable Diffusion, how it works, and how to begin using it. How about we unleash the power of AI-powered creativity?
Table of Content
What is Stable Diffusion?
Stable Diffusion is a modern deep-learning model that creates high-quality images based on written cues. It uses diffusion models, a type of AI that produces clear and attractive pictures from random noise by going through several steps. Stable Diffusion, created by Stability AI with help from researchers at CompVis and Runway, is a popular tool for creative projects and AI studies.
Key Features of Stable Diffusion
Text-to-Image Generation: You can make detailed pictures just by using describing words.
Image-to-Image Translation: Change or improve current images while keeping their shape the same.
Open-Source: Stable Diffusion is free to use, so developers and experts can modify it and add their features.
High Efficiency: It can be used on regular consumer GPUs, making it available to many people.
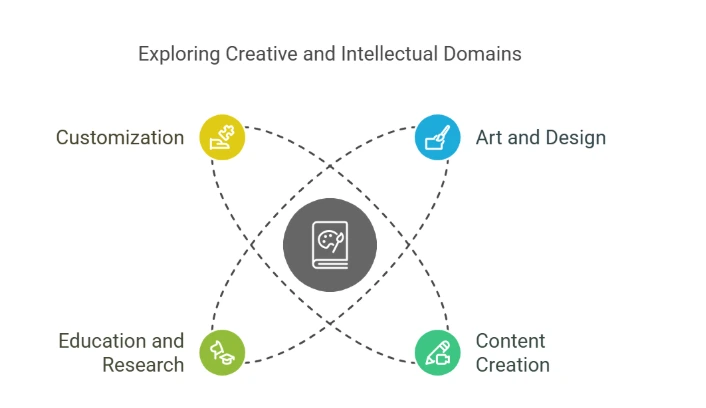
Applications
Art and Design: Create original artwork, drawings, and design ideas.
Content Creation: Make items for games, cartoons, and advertising.
Education and Research: Explore AI concepts and their applications in visual fields.
Customization: Adjust the model for particular art styles or business requirements.
Why is Stable Diffusion important?
Stable Diffusion is one of the most important developments in creative AI, particularly for making images. Here’s why it is important:
1. Democratization of Creativity
Stable Diffusion allows anyone to create high-quality images easily, no matter their skill level. Artists, designers, and makers can now make beautiful images from text descriptions. This allows anyone with an idea to turn it into a visual, even if they don’t have much experience in graphic design or 3D modeling.
2. Open-Source Innovation
Stable Diffusion is open-source, so anyone can use, change, and enhance it, unlike many private AI tools. This openness encourages creativity, letting developers and researchers try new things and adjust it for many uses, like fun and healthcare.
3. High-Quality Results
Stable Diffusion creates very detailed, realistic, and artistic pictures. It produces better images and a wider variety of styles than many other similar models, which makes it great for different artistic fields like film and video game design.
4. Versatility and Flexibility
Stable Diffusion is not just for generating images from text; it also supports a range of creative tasks such as:
Image Editing: Modify or enhance images using simple prompts.
Inpainting: Fill in missing areas of an image seamlessly.
Style Transfer: Apply different artistic styles to images.
This versatility makes it a powerful tool for artists and content creators across multiple domains.
5. Accessible to a Wide Audience
Stable Diffusion works on regular computers, so it’s easy for people and small businesses to use without needing costly equipment. This has made advanced AI tools available to more people.
6. Powerful for Customization
With Stable Diffusion, users can adjust the model to suit their needs, like making characters for a game, creating artwork, or designing buildings in detail. Custom models and fine-tuning create personalized results, making it more useful.
7. Driving the Future of AI Art
Stable Diffusion is changing what we can do with art made by AI. It allows for creative art-making in real-time, dynamic designs, and very detailed work, all just by using simple text. This has led to a new wave of creativity in digital art, design, and content creation.
8. Changing Industries
Stable Diffusion is changing industries like advertising, content creation, fashion, and interior design by automating creative tasks. It cuts down on the need to develop things by hand, makes processes faster, and creates new chances for telling stories visually.
How does Stable Diffusion work?
Stable Diffusion is an AI model that makes detailed images based on text descriptions using a method called diffusion. It transforms random noise into a clear picture gradually through several steps. Here’s an explanation of how it works:
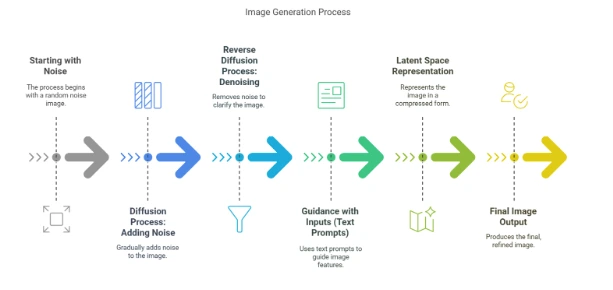
1. Starting with Noise
Initial State: The process starts with random noise, which is just a picture made up of complete randomness. This is where the model begins before adding any organization or features.
Noise Addition: During training, the model learns how a forward diffusion process works. The model starts with a clear picture and gradually adds noise to it in several steps until the image turns into complete noise, which looks like random pixels without any clear pattern.
Purpose: The forward process helps the model understand how pictures get worse when noise is added, which lets it learn about different types of images.
Denoising with a Neural Network: After the model is taught, it creates images by reversing the diffusion process. This is where the exciting things take place. The model starts with a noisy image and gradually removes the noise to show a clear picture.
Learning the Noise to Remove: The model learns to guess and eliminate the extra noise at every step. It uses a neural network to understand how to reverse the noise addition, producing a more structured image with each step.
4. Guidance with Inputs (Text Prompts)
Text-to-Image Generation: Stable Diffusion uses a text prompt, or other instructions, to generate pictures that fit the given description. The model uses CLIP, a neural network that learns how images and words are related, to help create an image based on the given prompt.
Conditional Generation: The process depends on the prompt. This means the model slowly improves the picture so that it fits the meaning, style, and features of the description.
5. Latent Space Representation
Efficient Image Generation:Stable Diffusion doesn’t work directly with the picture itself. Instead, it works in a simpler space that represents the image in fewer dimensions. This makes the process faster and uses less computing power, while still giving good results.
Latent Diffusion: The model works in a smaller, simplified version of the data instead of the actual picture. This makes it quicker and more efficient, while still keeping important details of the image.
6. Final Image Output
High-Quality Image: After repeating the noise removal process several times, the model creates a final, high-quality picture that fits the input request. The picture can look very realistic or very artistic based on the instructions given during its creation.
What architecture does Stable Diffusion use?
Stable Diffusion uses a latent diffusion model (LDM). This is a type of generative model that helps create images more efficiently and on a larger scale. Here’s a simple overview of the main parts and structure used in Stable Diffusion:
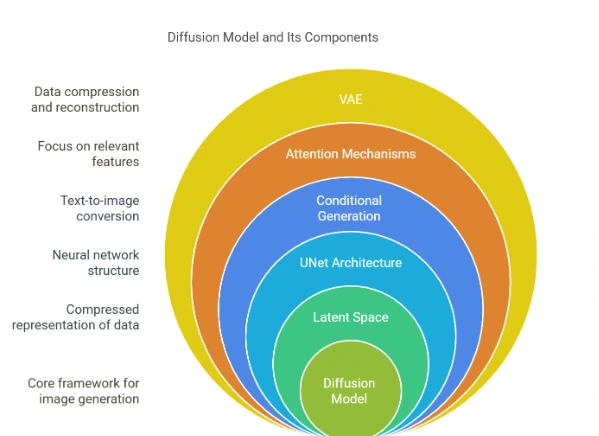
1. Diffusion Model
Stable Diffusion’s main structure is built on a denoising diffusion probabilistic model (DDPM), and it works in these steps:
Forward Diffusion: Images are slowly changed by adding random noise in several steps until they turn into complete noise.
Reverse Diffusion: The model learns to turn noise into a clear picture by predicting and taking away the noise bit by bit.
2. Latent Space (Latent Diffusion)
Stable Diffusion works in a simpler area called latent space instead of directly using pixels. This saves more computer resources.
Encoder-Decoder Architecture: The input picture is first encoded into a lower-dimensional latent representation using a Variational Autoencoder (VAE). This simplified version is then used in the spread process.
Latent Diffusion: The noise removal and spreading steps happen on this simpler version, which is easier to compute. After the diffusion process, the latent picture is decoded back into a high-quality image using the decoder part of the VAE.
3. UNet Architecture
The denoising in Stable Diffusion is done using a UNet-style structure. UNet is a type of convolutional neural network (CNN) often used for image segmentation and denoising jobs. It is made up of:
Encoder: The encoder captures the essential features of the noisy image and compresses them into a latent space representation.
Decoder: The decoder reconstructs the image from the latent representation, progressively removing the noise in the reverse diffusion process.
The UNet architecture is crucial because it allows the model to efficiently learn the complex process of denoising and generating high-quality images.
4. Conditional Generation (Text-to-Image)
For text-to-image generation, Stable Diffusion uses a conditioning mechanism:
CLIP (Contrastive Language-Image Pretraining): A model trained to map images and text into a shared feature space. Stable Diffusion uses CLIP to understand the relationship between text prompts and images, guiding the denoising process to produce images that match the input description.
Cross-Attention Layers: These layers integrate the text prompt into the diffusion process. The model uses the text input to guide the transformation of the noisy latent representation into an image that aligns with the prompt’s content.
5. Attention Mechanisms
Stable Diffusion uses attention processes, especially cross-attention layers, to make the model work better during the denoising process. These systems help the model concentrate on the important parts of the input, such as background noise or text prompts, which leads to producing clearer and more accurate pictures.
6. VAE (Variational Autoencoder)
The VAE is responsible for encoding images into a latent space and decoding them back to high-quality images:
Encoder: Transforms images into a compressed representation (latent vector).
Decoder: Reconstructs images from the latent vector after the diffusion process.
This VAE-based approach allows Stable Diffusion to operate efficiently, as working in latent space greatly lowers the computational cost compared to generating images directly in pixel space.
7. CLIP Guidance
Stable Diffusion uses CLIP to connect text and images when creating pictures from words. CLIP knows how images relate to their descriptions. This helps the diffusion model create images that fit the given text.
How to use Stable Diffusion Online?
Using Stable Diffusion online is simple because many websites and services allow you to access it easily. Here are some suggestions to help you begin:
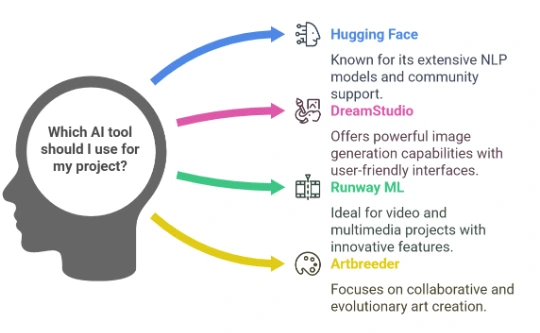
Hugging Face:
Platform: Hugging Face offers a user-friendly interface to interact with Stable Diffusion through their Inference API or Spaces.
How to Use: You can directly run Stable Diffusion models through their online interface by entering your text prompt or uploading an image for inpainting or editing. No installation required—just sign up and start generating images.
Platform: DreamStudio is the official web interface for Stable Diffusion by Stability AI.
How to Use: You can sign up for an account and use their web tool to generate images, adjust parameters like image resolution or style, and pay for credits based on usage.
Platform: Runway ML provides a web-based interface that integrates Stable Diffusion and other AI models.
How to Use: After signing up, you can easily create images from text prompts, modify images, or perform other creative tasks with Stable Diffusion’s capabilities.
Artbreeder (based on Stable Diffusion):
Platform: Artbreeder has integrated Stable Diffusion for generating and modifying creative works.
How to Use: Create an account, and then you can start experimenting with creating new artworks and exploring other images or styles.
Colab Notebooks (Google Colab):
Platform: You can also run Stable Diffusion on Google Colab using open-source notebooks.
How to Use: Several public Colab notebooks allow you to run Stable Diffusion models in the cloud. These notebooks typically include code and provide instructions to easily run the model for free or at a small cost (depending on your usage).
What can Stable Diffusion do?
Stable Diffusion is a strong and flexible tool that can be used for many artistic projects.
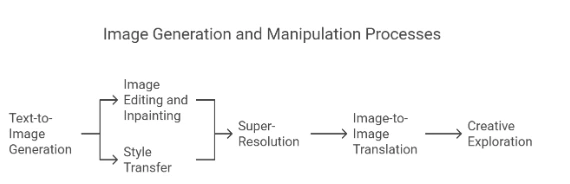
Text-to-Image Generation:
Create detailed images based on written descriptions. For example, if you describe “a futuristic city at sunset,” Stable Diffusion will make an image from that statement.
Image Editing and Inpainting:
Change parts of a current picture by giving specific directions. You can remove or add elements to an image, or “fill in” missing areas (inpainting).
Style Transfer:
Apply different artistic styles to an image. For example, you can transform a photo into the style of a famous artist or art movement.
Super-Resolution:
Improve the clarity and quality of an image, making blurry pictures sharp and detailed.
Image-to-Image Translation:
Create images that change one picture into another with interesting or artistic variations. For example, you can change a sketch into a full picture.
Creative Exploration:
Artists can use Stable Diffusion to try out new creative ideas, make concept art, or play with various visual styles.
How can AWS help with Stable Diffusion?
AWS (Amazon Web Services) can offer the computing power needed to run Stable Diffusion effectively, especially for big or demanding image generation projects. Here’s how AWS can assist you:
Scalable Compute Power:
Amazon EC2 Instances: Use EC2 machines that have GPU support (like NVIDIA A100 or V100) to run Stable Diffusion models on a large scale. These servers are made to manage the heavy processing needed for deep learning models.
Elastic Scaling: AWS lets you adjust your resources based on how much you use, so you only pay for what you need.
AWS Sagemaker:
Managed Machine Learning: You can use AWS Sagemaker to set up and run Stable Diffusion models in real-world situations. It offers easy-to-use tools for training, hosting, and growing machine learning models.
Pre-built Images: You can use ready-made packages for deep learning tools like PyTorch to easily set up Stable Diffusion.
AWS Lambda for Serverless Execution:
On-demand AI Models: For small applications that don’t require servers, AWS Lambda lets you run Stable Diffusion whenever you need it, without having to handle any servers. This is great for projects that need to be used from time to time instead of all the time.
Amazon S3 (Storage):
Image Storage: Use S3 to keep your generated images, datasets, and model checkpoints, making it easy to view and share your work.
Easy Integration: Save your input data and output pictures in S3, and connect it with AWS machine learning services to organize your tasks.
AWS Batch for Large-Scale Image Generation:
Efficient Batch Processing: If you want to create a lot of pictures at the same time, AWS Batch can help quickly run Stable Diffusion across multiple computers.
AWS Deep Learning AMIs:
Preconfigured Environments: AWS provides Deep Learning AMIs (Amazon Machine Images) that are ready to use with popular deep learning tools like PyTorch and TensorFlow. This makes it simpler to use Stable Diffusion without having to set up everything by hand.
Conclusion
Stable Diffusion is a powerful generative AI that turns text prompts into high-quality images, offering endless creative possibilities. Its smart design, which includes techniques like latent diffusion and models such as UNet, VAE, and CLIP, allows for fast and high-quality picture creation. Stable Diffusion is available for use on online platforms like Hugging Face and DreamStudio, as well as cloud services like AWS. This makes it easy for anyone to create high-quality images. It creates new opportunities for art, design, and experimentation, and it is set to be an important tool for making digital material.
Generative AI creates text, images, and more by learning from data patterns. A Gen AI certification helps professionals develop skills in training AI models for automation, creativity, and real-world applications in various industries.
FAQ
1. How do I access Stable Diffusion AI?
You can use Stable Diffusion in different ways based on what you need and how skilled you are with technology:
Online platforms such as DreamStudio by Stability AI let you use Stable Diffusion without needing to install anything. Prebuilt Applications: Tools such as AUTOMATIC1111’s WebUI offer an easy-to-use interface. APIs: Stability AI provides APIs that allow developers to add Stable Diffusion into their own products. Command Line Interfaces (CLI): For advanced users, you can run Stable Diffusion locally using the CLI.
2. How to install Stable Diffusion?
To install Stable Diffusion locally:
Requirements A good GPU, ideally an NVIDIA one that supports CUDA. Make sure you have Python 3.10 or a newer version loaded on your computer. You need at least 10 GB of free room on your hard drive.
Steps to Install
Clone the Repository:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui
Download Model Weights: Obtain the Stable Diffusion model weights (e.g., v1.5 or v2.1) from Hugging Face or other trusted sources. Place them in the models/Stable-diffusion folder.
Install Dependencies:
pip install -r requirements.txt
Run the WebUI:
python launch.py
This starts a local server accessible at http://127.0.0.1:7860.
3. Is Stable Diffusion available on Android?
Yes, you can use Stable Diffusion on Android devices.
Mobile Apps: Apps like Draw Things and Diffusion Bee (for iOS) make Stable Diffusion work on mobile devices. Access online sites like DreamStudio or Hugging Face Spaces using your mobile browser. Local Installation: You can use tools like Termux and Ubuntu on Android to run Stable Diffusion, but it’s not a good idea because the hardware is restricted.
4. Which Stable Diffusion should I use?
The version or tool you choose relies on what you need.
Stable Diffusion 1.5: Good for everyday use and making different styles. Stable Diffusion 2.x is an improved version that has new features such as depth maps and enhanced picture generation. AUTOMATIC1111 WebUI: Very adjustable with many add-ons and control options. Great for fans. DreamStudio: Great for fast and simple online creation without any setup needed. Custom Models: Look into customized models on Civitai for particular art types or uses. Let me know if you’d like full guidance on any specific method!






 Copy Link!
Copy Link!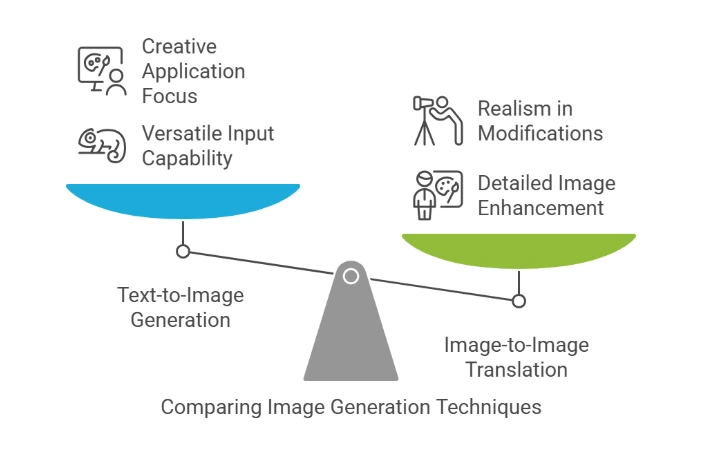
 Text-to-Image Generation:
Text-to-Image Generation: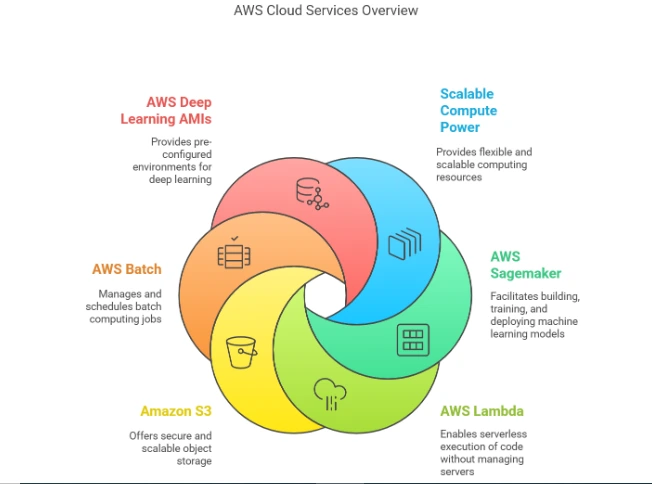


















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







