
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Speech is the most common means of communication around the world. Most of the population in the world relies on speech to communicate with each other. Suppose we are building a model and instead of a written approach we want our system to respond to speech, it becomes fairly difficult and requires a lot of data to be processed. A speech recognition system overcomes this barrier by translating speech to text. In this blog, we will go through the speech recognition module in python. Here is the list of the same:
Speech recognition system basically translates the spoken utterances to text. There are various real life examples of speech recognition system. For example- siri, which takes the speech as input and translates it into text.
The advantage of using a speech recognition system is that it overcomes the barrier of literacy. A speech recognition model can serve both literate and illiterate audience as well, since it focuses on spoken utterances.
We can also make an inventory of all the endangered languages around the world using a speech recognition system. While it looks pretty intriguing and not complex at all, a speech recognition system faces a lot of challenges in the making.
Challenges Faced By A Speech Recognition System
A speech recognition system becomes difficult to make because we have so many sources of variability when it comes to speech.
Every individual person has a varied style of speaking, including accents as well. As we all know, we have different accents for speaking English too. There is american English, British English and so many other accents when it comes to speaking the most common language in the world. Pronunciation also makes it difficult for a speech recognition system to translate the speech altogether.
Environment adds a lot of background noise to the system as well. An isolated room compared to an auditorium will have a lot a variability in background noises. Even echo can add a lot of noise in the system as well.
An old person’s voice may not the be the same as that of an infant. The characteristics of a person’s speech depends on many factors including the harshness and clarity as well.
Some spoken utterances may not have a viable meaning when it comes to translation.
After overcoming these challenges, it is fairly achievable for any speech recognition system to translate speech to text. Now that we know how speech recognition works, lets take a look at different packages that are available for speech recognition in python.
Packages available for speech recognition in python
apiai
SpeechRecognition
Google_speech_cloud
assemblyai
Pocketsphinx
Watson_developer_cloud
wit
We will go through the details of SpeechRecognition package in this blog, lets also take a look down the memory lane to understand how speech recognition systems have evolved over the years.
The very first prototype of the speech recognition was in fact a toy, named radio rex which came around 1920’s. It had a dog sitting in a dog house which would pop out as soon as someone uttered the word rex.
The only problem with the model was that the spring was attached to an electromagnet which was sensitive to energy ranging around 500hz. Being purely a frequency detector, it could be remotely termed as a speech recognition model.
In 1962, IBM came up with a shoebox model which was able to recognize isolated words and also perform a few arithmetic operations as well.
Then came HARPY from CMU, which was able to recognize connected speech from a 1000 word vocabulary. Around the 1980s people started using statistical models and one of the most used machine learning paradigms was the hidden markov model.
After the introduction of deep neural networks, most of the speech recognition models work on the neural networks. The possibilities are unimaginable with the neural networks, the vocabulary can go upto 10k words and more.
To install SpeechRecognition package is python, run the following command in the terminal and it will be installed on your system.
![]()
Another approach to this, can be adding the package from the project interpreter if you are using pycharm.
The package has a Recognizer class which is basically where the magic happens. It is basically a class which is used to recognize the speech. Following are seven methods which can read various audio sources using different APIs.
Now, recognize_sphinx can be used to run the speech recognition system offline as well. It requires the installation of Pocketsphinx.
import speechrecognition as sr #instance of recognizer class r = sr.Recognizer()
To use the microphones, we will have to install pyaudio module as well. We use the microphone class to get the input speech from the microphone instead of any other input method like an audio file.
For most of the projects, we can use the default microphones. But if you do not wish to use the default microphone, you can get the list of microphone names using the list_microphone_names method.
To capture the input from the microphone we use the listen method.
import speechrecognition as sr
r = sr.Recognizer()
with sr.Microphone() as source:
audio = sr.listen(source)
To install Pyaudio in python, run the following command in the terminal or if you are using pycharm add the package from the project interpreter in the settings.

We will make a program using the speechrecognition module in python to recognize speech and execute the following:
Following is the program for the above problem statement:
import speech_recognition as sr
import webbrowser as wb
r1 = sr.Recognizer()
r2 = sr.Recognizer()
r3 = sr.Recognizer()
with sr.Microphone() as source:
print('[search edureka: search youtube]')
print('speak now')
audio = r3.listen(source)
if 'edureka' in r2.recognize_google(audio):
r2 = sr.Recognizer()
url = 'https://www.edureka.co/'
with sr.Microphone() as source:
print('search your query')
audio = r2.listen(source)
try:
get = r2.recognize_google(audio)
print(get)
wb.get().open_new(url+get)
except sr.UnknownValueError:
print('error')
except sr.RequestError as e:
print('failed'.format(e))
if 'video' in r1.recognize_google(audio):
r1 = sr.Recognizer()
url = 'https://www.youtube.com/results?search_query='
with sr.Microphone() as source:
print('search for a video')
audio = r2.listen(source)
try:
get = r1.recognize_google(audio)
print(get)
wb.get().open_new(url+get)
except sr.UnknownValueError:
print('could not understand')
except sr.RequestError as e:
print(failed to get results'.format(e))
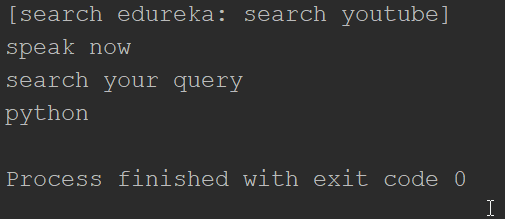
You will get the output like it is shown in the image. If you say edureka, it will prompt you to say the query that you want to search in the edureka url that we have written in the url variable. If you say python you will get the following web page opened in the browser.
In this blog, we have discussed how we can use speech recognition in python to translate speech to text using the speechrecognition package.Artificial intelligence has become the need of the hour for concepts like speech recognition or object dejection, with the deep neural networks that provide unimaginable possibilities to speech recognition systems where we can train and test enormous speech data to build a system.You can enroll in the Python online course certification for deep neural networks to master your skills and kickstart your learning.
have any queries? mention them in the comments, we will get back to you.






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







