
Advanced Certification in Agentic AI Engineer ...
- 66k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!Large language models (LLMs) work better when they can reach a specific knowledge base instead of just their general training data. This is called retrieval-augmented generation (RAG). Because they are trained on huge datasets and have billions of factors. LLMs are great at answering questions, translating, and filling in blanks in text. RAG improves this feature even more by letting LLMs get information from a reliable outside source, like an organization’s own data before they write replies. It is an efficient and cost-effective method for customizing LLM responses for specialized domains, as it allows for accurate, context-specific, and current responses without the need for model retraining.
Here is the image below showing the workflow of RAG:
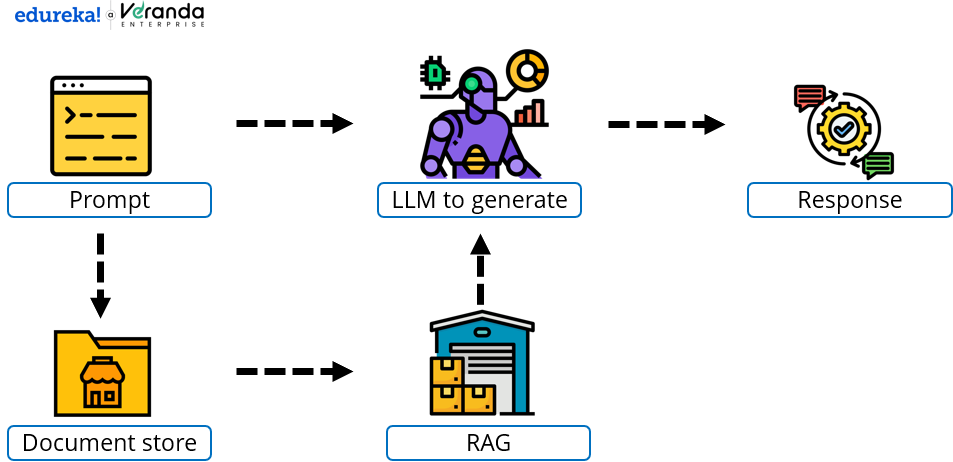
Now that we know the basic workflow let us look at what is RAG.
An overview on “What is RAG” by edureka
Retrieval
This is the act of getting data from somewhere outside the computer, usually a database, knowledge base, or document store. In RAG, retrieval is the process of looking for useful data (like text or documents) based on what the user or system asks for or types in.
Augmented
Augmented means that something has been made better or more complete. In the case of RAG, it means improving the process of making a model by adding more useful information that was retrieved during the retrieval step. The model is “augmented” with outside data, which makes it more accurate and aware of its surroundings, rather than depending only on its own knowledge, which may be limited.
Generation
Generation is the process of making something, like writing, based on a command or input. This term is used in RAG to describe how the large language model (LLM) writes text or answers. The LLM usually uses both the information it has received and what it already knows to make an output after getting relevant data.
RAG allows you to optimize the output of an LLM with targeted information without changing the underlying model; this targeted information can be more up-to-date than the LLM and tailored to a given company and sector. For that reason, the creative AI system can give better answers that are more relevant to the situation and are based on very recent data.
“Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” a 2020 paper by Patrick Lewis and a team at Facebook AI Research, was the first thing that generative AI writers heard about RAG. Many researchers in both academia and business like the RAG idea because they think it can make generative AI systems much more useful.
Now that we know what is RAG lets look at its benefits.
It is possible to make generative AI systems respond to prompts better than an LLM alone by using RAG methods. Among the benefits are the following:
It is possible to find out where the data in the RAG’s vector database came from. And since the sources of the data are known, wrong information in the RAG can be fixed or taken out.
Since we know so must about RAG, lets at look at the history of RAG.
The history of Retrieval-Augmented Generation (RAG) shows how retrieval-based methods and generative AI have been used together to improve knowledge-based results. One problem with standalone generative models like GPT is that they might come up with wrong or crazy answers because they don’t have any real-world data to base their replies on.

Let us understand the above points in detail:
RAG can actively use huge amounts of external data sources because it can both retrieve and generate data. This makes it a powerful tool for AI systems that need to be factual and aware of their surroundings.
Now that we know about RAG’s History let is look at how RAG works.
Retrieval-augmented generation (RAG) is a mixed method that uses retrieval-based methods and generative AI to create correct, knowledge-based results that are informed by context.
Here are the steps below showing how RAG works:

Knowledge-based robots, question-answering systems, and content creation tools are just a few of the many uses for RAG. It connects rigid knowledge bases to generative AI’s ability to change based on new information.
Now that we know how RAG works let us look at how people are using it.

People are using Retrieval-Augmented Generation (RAG) in many different areas because it can combine strong generative abilities with dynamic knowledge retrieval. Take a look at these main use cases:
By dynamically grounding generative AI in up-to-date and relevant information, RAG is empowering solutions in diverse fields, enhancing user experience, and driving efficiency.
Now that we have a proper idea about RAG let us look at the challenges RAG faces.
There are a lot of good things about Retrieval-Augmented Generation (RAG), but there are also some problems, lets understand those problems through a table:
| Challenge | Description | Example |
|---|---|---|
| Retrieval Quality | The quality of outputs depends on the retriever’s ability to fetch the most relevant and accurate information. | Incorrect or misleading results if the retriever fetches outdated or non-specific documents. |
| Knowledge Base Maintenance | Keeping the knowledge base updated is critical to prevent performance degradation. | Outdated policy information in a customer support chatbot due to an outdated knowledge base. |
| Computational Overhead | Involves both retrieval and generation steps, increasing latency and computational costs. | Real-time applications like conversational agents may face delays due to the retrieval process. |
| Contextual Integration | Combining retrieved information meaningfully with the generative model’s input can be complex. | Struggling to generate coherent responses if retrieved documents contain conflicting information. |
| Bias and Hallucination | The generative model may hallucinate or generate biased outputs if the retrieved context is ambiguous. | Fabricating details when the retrieved documents don’t fully address the query. |
| Scalability | Scaling RAG systems for large-scale deployments can be resource-intensive. | Multilingual support for a global enterprise requires scalable infrastructure to handle diverse queries. |
| Domain-Specific Adaptation | Adapting RAG systems to specialized domains requires domain-specific data curation and fine-tuning. | Healthcare RAG system needs extensive medical datasets and context-aware retrieval for accuracy. |
| Evaluation Complexity | Measuring the effectiveness of RAG outputs is challenging and requires comprehensive evaluation. | Traditional metrics like BLEU or ROUGE may not fully capture the performance of RAG systems. |
| Security and Privacy | Using external knowledge bases or APIs can pose security and privacy risks, especially with sensitive data. | Processing confidential legal documents must ensure data security during retrieval and generation. |
| Integration Challenges | Integrating retrieval modules with generative models can be technically demanding. | API mismatches or latency between retrieval and generation components can impact performance. |
Improving retrieval techniques, integration methods, and review frameworks is needed to deal with these problems and make sure that RAG systems are reliable, efficient, and scalable.
Here are some notable examples of applications leveraging Retrieval-Augmented Generation (RAG):

The future of Retrieval-Augmented Generation (RAG) is promising, with possible advancements shaping its evolution across various domains, let us break it down through a table:
| Trend | Description | Impact |
|---|---|---|
| Improved Retrieval Mechanisms | Enhanced algorithms leveraging real-time data and multimodal content (text, images, video). | More accurate and context-aware responses for handling complex queries with precision. |
| Domain-Specific Adaptation | Tailored RAG systems for fields like healthcare, legal, and education. | Increased adoption in niche industries with highly relevant and trustworthy outputs. |
| Integration with Large Language Models (LLMs) | Seamless integration with advanced LLMs like GPT-4 and beyond. | Smarter and more coherent generative outputs for ambiguous or broad questions. |
| Scalable Cloud Solutions | Cloud providers offering ready-to-use RAG frameworks with scalable infrastructure. | Easier deployment for businesses, reducing technical barriers and encouraging widespread use. |
| Multimodal Retrieval and Generation | Expanding RAG to handle text, images, audio, and video. | Enhanced user experience and broader application scope, e.g., video summarization and cross-modal content creation. |
| Efficient and Low-Resource Deployments | Optimizing RAG systems with techniques like quantization and distillation. | Cost-effective deployment on edge devices and in resource-constrained environments. |
| Real-Time Applications | Near-instantaneous retrieval and generation for live interactions. | Transforming domains like customer support, gaming, and live education. |
| Ethical and Bias Mitigation | Frameworks ensuring ethical use and reducing biases in RAG systems. | Greater trust and adoption in sensitive applications like governance and public services. |
| Autonomous Knowledge Update Systems | Self-updating knowledge bases by retrieving and indexing new information. | Reduced manual intervention and always up-to-date systems. |
| Enhanced Evaluation Metrics | Sophisticated metrics to evaluate retrieval relevance and generative quality. | Better benchmarking and iterative improvement of RAG systems. |
| Integration with AR and VR | RAG integrated into AR/VR environments for immersive experiences. | New opportunities in gaming, virtual assistance, and training simulations. |
| Personalized User Experiences | Fine-tuning RAG models based on individual user profiles and preferences. | Hyper-personalized content generation for marketing, education, and entertainment. |
| Collaborative AI Systems | RAG working alongside other AI systems for multi-agent tasks. | Complex workflows like autonomous research or creative collaboration become feasible. |
| Wider Democratization | Open-source RAG frameworks and accessible pre-trained models. | Democratization of AI technology for startups, educators, and developers globally. |
With these advancements, RAG is poised to become a cornerstone of AI applications, bridging the gap between knowledge retrieval and creative, context-aware output generation.
Generative AI uses machine learning to create new content, enhancing automation and innovation. A gen AI certification teaches essential skills to develop AI-powered solutions for industries like marketing, design, and software development.
RAG, or Retrieval-Augmented Generation, is a huge step forward in the field of artificial intelligence. It combines the ability to find information and make new things. By integrating the precision of retrieval systems with the creativity of generative models, RAG improves the contextuality, accuracy, and relevance of AI outputs. Its many uses in fields as different as healthcare and education, customer service, and content creation show how flexible and useful it is.

1. What is the difference between retrieval augmented generation and semantic search?
Retrieval-Augmented Generation (RAG) combines information retrieval and generative AI to answer questions or generate content by finding relevant documents and using them as a starting point. In contrast, semantic search identifies and ranks the most contextually relevant documents or information based on a query’s meaning without creating new content. The main difference is that RAG uses retrieved information as input for creative tasks, while the semantic search can only retrieve and rank material that already exists.
2. What is the difference between fine-tuning and retrieval augmented generation?
Training an existing model on a specific dataset to perform a particular task or operate within a specific domain is known as fine-tuning. This process entails modifying the model’s weights to increase its specialization. RAG, on the other hand, doesn’t change the model’s weights; instead, it uses external knowledge bases or papers to improve its outputs on the fly while inference is happening. When you fine-tune a model, you make changes that last, but when you use RAG, you use outside resources without changing the model itself.
3. Who invented the retrieval augmented generation?
In 2020, Facebook AI Research (FAIR) came up with the Retrieval-Augmented Generation (RAG). It was in their important work called “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” that they explained the idea of combining document retrieval with generative models to make knowledge-based tasks easier to do.
4. What is retrieval in artificial intelligence?
In AI, retrieval is the process of finding and getting relevant data or information from a big collection, like databases or documents, based on a specific question. Retrieval methods frequently employ semantic matching, keyword search, or embedding-based techniques to identify the most contextually relevant results.
5. What is Retrieval-Augmented Generation for Translation?
Retrieval-augmented generation for Translation is a method for improving machine translation systems by adding important context information from outside databases or translation memories. Instead of just using the model’s built-in tools, RAG gets domain-specific or contextually similar translations to help guide the generative translation process. This makes it more accurate and consistent in cases that aren’t clear.













 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


