

PySpark Certification Training Course
- 12k Enrolled Learners
- Weekend/Weekday
- Live Class
(4000)





 Copy Link!
Copy Link!Spark, The word itself is enough to generate a spark in every Hadoop engineer’s mind. An in-memory processing tool which is lightning-fast in cluster computing. Compared to MapReduce, the in-memory data sharing makes RDDs 10-100x faster than network and disk sharing and all this is possible because of RDDs (Resilient Distributed Data sets). The key points we focus today in this RDD using Spark article are:
![]()
The world is evolving with Artificial Intelligence and Data Science because of the advancement in Machine Learning. Algorithms based on Regression, Clustering, and Classification which runs on Distributed Iterative Computation fashion that includes Reusing and Sharing of data among multiple computing units.
The traditional MapReduce techniques needed a Stable Intermediate and Distributed storage like HDFS comprising repetitive computations with data replications and data serialization, which made the process a lot slower. Finding a solution was never easy.

This is where RDDs (Resilient Distributed Datasets) comes to the big picture.
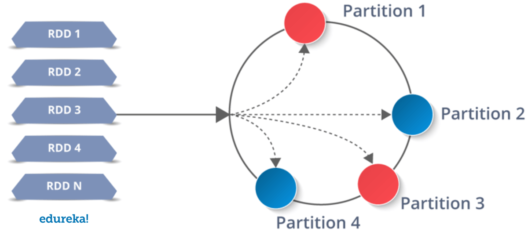
RDDs are easy to use and effortless to create as data is imported from data sources and dropped into RDDs. Further, the operations are applied to process them. They are a distributed collection of memory with permissions as Read-only and most importantly, they are Fault-tolerant.

If any data partition of an RDD is lost, it can be regenerated by applying the same transformation operation on that lost partition in lineage, rather than processing all the data from scratch. This kind of approach in real time scenarios can make miracles happen in situations of data loss or when a system is down.
RDD or (Resilient Distributed Data set) is a fundamental data structure in Spark. The term Resilient defines the ability that generates the data automatically or data rolling back to the original state when an unexpected calamity occurs with a probability of data loss.

The data written into RDDs is partitioned and stored into multiple executable nodes. If an executing node fails in the run time, then it instantly gets the back up from the next executable node. This is why RDDs are considered as an advanced type of data structures when compared to other traditional data structures. RDDs can store structured, unstructured and semi-structured data.
Let’s move ahead with our RDD using Spark blog and learn about the unique features of RDDs which gives it an edge over other types of data structures.

RDDs can be created in three ways:

val PCRDD = spark.sparkContext.parallelize(Array("Mon","Tue","Wed","Thu","Fri","Sat"),2)
val resultRDD = PCRDD.collect()
resultRDD.collect().foreach(println)
val words = spark.sparkContext.parallelize(Seq("Spark","is","a","very","powerful","language"))
val wordpair = words.map(w =(w.charAt(0),w))
wordpair.collect().foreach(println)
val Sparkfile = spark.read.textFile("/user/edureka_566977/spark/spark.txt.")
Sparkfile.collect()
There are mainly two types of operations which are performed on RDDs, namely:

Transformations: The operations we apply on RDDs to filter, access and modify the data in parent RDD to generate a successive RDD is called transformation. The new RDD returns a pointer to the previous RDD ensuring the dependency between them.
Transformations are Lazy Evaluations, in other words, the operations applied on the RDD that you are working will be logged but not executed. The system throws a result or exception after triggering the Action.
We can divide transformations into two types as below:
Narrow Transformations We apply narrow transformations on to a single partition of the parent RDD to generate a new RDD as data required to process the RDD is available on a single partition of the parent RDD. The examples for narrow transformations are:
Wide Transformations: We apply the wide transformation on multiple partitions to generate a new RDD. The data required to process the RDD is available on the multiple partitions of the parent RDD. The examples for wide transformations are :
Actions: Actions instruct Apache Spark to apply computation and pass the result or an exception back to the driver RDD. Few of the actions include:
Let us practically apply the operations on RDDs:

IPL(Indian Premier League) is a cricket tournament with it’s hipe at a peak level. So, lets today get our hands on to the IPL data set and execute our RDD using Spark.

In the next step, we fire up the spark and load the matches.csv file from its location, in my case my csv file location is “/user/edureka_566977/test/matches.csv”

Now let us Start with the Transformation part first:

We use Map Transformation to apply a specific transformation operation on every element of an RDD. Here we create an RDD by name CKfile where store our csv file. We shall create another RDD called States to store the city details.
spark2-shell
val CKfile = sc.textFile("/user/edureka_566977/test/matches.csv")
CKfile.collect.foreach(println)
val states = CKfile.map(_.split(",")(2))
states.collect().foreach(println)

Filter transformation, the name itself describes its use. We use this transformation operation to filter out the selective data out of a collection of data given. We apply filter operation here to get the records of the IPL matches of the year 2017 and store it in fil RDD.
val fil = CKfile.filter(line => line.contains("2017"))
fil.collect().foreach(println)

We apply flatMap is a transformation operation to each of the elements of an RDD to create a newRDD. It is similar to Map transformation. here we apply Flatmap to spit out the matches of Hyderabad city and store the data into filRDD RDD.
val filRDD = fil.flatMap(line => line.split("Hyderabad")).collect()

Every data we write into an RDD is split into a certain number of partitions. We use this transformation to find the number of partitions the data is actually split into.
val fil = CKfile.filter(line => line.contains("2017"))
fil.partitions.size

We consider MapPatitions as an alternative of Map() and foreach() together. We use mapPartitions here to find the number of rows we have in our fil RDD.
val fil = CKfile.filter(line => line.contains("2016"))
fil.mapPartitions(idx => Array(idx.size).iterator).collect

We use ReduceBy() on Key-Value pairs. We used this transformation on our csv file to find the player with the highest Man of the matches.
val ManOfTheMatch = CKfile.map(_.split(",")(13))
val MOTMcount = ManOfTheMatch.map(WINcount => (WINcount,1))
val ManOTH = MOTMcount.reduceByKey((x,y) => x+y).map(tup => (tup._2,tup._1))sortByKey(false)
ManOTH.take(10).foreach(println)

The name explains it all, We use union transformation is to club two RDDs together. Here we are creating two RDDs namely fil and fil2. fil RDD contains the records of 2017 IPL matches and fil2 RDD contains 2016 IPL match record.
val fil = CKfile.filter(line => line.contains("2017"))
val fil2 = CKfile.filter(line => line.contains("2016"))
val uninRDD = fil.union(fil2)

Let us start with the Action part where we show actual output:

Collect is the action which we use to display the contents in an RDD.
val CKfile = sc.textFile("/user/edureka_566977/test/matches.csv")
CKfile.collect.foreach(println)

Count is an action that we use to count the number of records present in an RDD.Here we are using this operation to count the total number of records in our matches.csv file.
val CKfile = sc.textFile("/user/edureka_566977/test/matches.csv")
CKfile.count()

Take is an Action operation similar to collect but the only difference is it can print any selective number of rows as per user request. Here we apply the following code to print the top ten leading reports.
val statecountm = Scount.reduceByKey((x,y) => x+y).map(tup => (tup._2,tup._1))sortByKey(false) statecountm.collect().foreach(println) statecountm.take(10).foreach(println)

First() is an action operation similar to collect() and take() it used to print the topmost report s the output Here we use the first() operation to find the maximum number of matches played in a particular city and we get Mumbai as the output.
val CKfile = sc.textFile("/user/edureka_566977/test/matches.csv")
val states = CKfile.map(_.split(",")(2))
val Scount = states.map(Scount => (Scount,1))
scala> val statecount = Scount.reduceByKey((x,y)=> x+y).collect.foreach(println)
Scount.reduceByKey((x,y)=> x+y).collect.foreach(println)
val statecountm = Scount.reduceByKey((x,y)=> x+y).map(tup => (tup._2,tup._1))sortByKey(false)
statecountm.first()
Redefine your data analytics workflow and unleash the true potential of big data with Pyspark Certification.
To make our process our learning RDD using Spark, even more, interesting, I have come up with an interesting use case.

val PokemonDataRDD1 = sc.textFile("/user/edureka_566977/PokemonFile/PokemonData.csv")
PokemonDataRDD1.collect().foreach(println)

Pokemons are actually available in a large variety, Let us find a few varieties.
We might not need the Schema of Pokemon.csv file. Hence, we remove it.
val Head = PokemonDataRDD1.first() val NoHeader = PokemonDataRDD1.filter(line => !line.equals(Head))

println("No.ofpartitions="+NoHeader.partitions.size)

Finding the number of Water pokemon
val WaterRDD = PokemonDataRDD1.filter(line => line.contains("Water"))
WaterRDD.collect().foreach(println)

Finding the number of Fire pokemon
val FireRDD = PokemonDataRDD1.filter(line => line.contains("Fire"))
FireRDD.collect().foreach(println)

WaterRDD.count() FireRDD.count()

val defenceList = NoHeader.map{x => x.split(',')}.map{x => (x(6).toDouble)}
println("Highest_Defence : "+defenceList.max())

val defWithPokemonName = NoHeader.map{x => x.split(',')}.map{x => (x(6).toDouble,x(1))}
val MaxDefencePokemon = defWithPokemonName.groupByKey.takeOrdered(1)(Ordering[Double].reverse.on(_._1))
MaxDefencePokemon.foreach(println)

val minDefencePokemon = defenceList.distinct.sortBy(x => x.toDouble,true,1) minDefencePokemon.take(5).foreach(println)

val PokemonDataRDD2 = sc.textFile("/user/edureka_566977/PokemonFile/PokemonData.csv")
val Head2 = PokemonDataRDD2.first()
val NoHeader2 = PokemonDataRDD2.filter(line => !line.equals(Head))
val defWithPokemonName2 = NoHeader2.map{x => x.split(',')}.map{x => (x(6).toDouble,x(1))}
val MinDefencePokemon2 = defWithPokemonName2.groupByKey.takeOrdered(1)(Ordering[Double].on(_._1))
MinDefencePokemon2.foreach(println)

So, with this, we come to an end of this RDD using Spark article. I hope we sparked a little light upon your knowledge about RDDs, their features and the various types of operations that can be performed on them.
This article based on Apache Spark and Scala Certification Training is designed to prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175). You will get an in-depth knowledge on Apache Spark and the Spark Ecosystem, which includes Spark RDD, Spark SQL, Spark MLlib and Spark Streaming. You will get comprehensive knowledge on Scala Programming language, HDFS, Sqoop, Flume, Spark GraphX and Messaging System such as Kafka.Upskill your data engineering skills with our Microsoft fabric certification Training course






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP






