
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
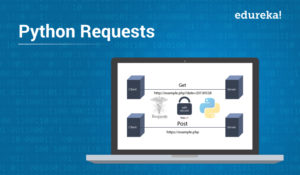
Copy Link!In this post on Python Requests Tutorial, I will explain to you all the basics of Requests Module and how you can send HTTP/1.1 requests using Python. By the end of this blog, you will be able to perform web scraping using Python. I will be covering the following topics in this post:
Let us begin this “Requests Tutorial” blog by first checking out what the Requests Module actually is.
To get in-depth knowledge on Python along with its various applications, you can enroll now for the Python Certification Course online training with 24/7 support and lifetime access.
Requests is a Python module that you can use to send all kinds of HTTP requests. It is an easy-to-use library with a lot of features ranging from passing parameters in URLs to sending custom headers and SSL Verification. In this tutorial, you will learn how to use this library to send simple HTTP requests in Python.
Requests allow you to send HTTP/1.1 requests. You can add headers, form data, multi-part files, and parameters with simple Python dictionaries, and access the response data in the same way.
To install requests, simply:
$ pip install requests
Or, if you absolutely must:
$ easy_install requests
It is fairly straightforward to send an HTTP request using Requests. You start by importing the module and then making the request. Check out the example:
import requests
req = requests.get('https://www.edureka.co/')
req.encoding # returns 'utf-8' req.status_code # returns 200
We can also access the cookies that the server sent back. This is done using req.cookies, as straightforward as that! Similarly, you can get the response headers as well. This is done by making use of req.headers.
Do note that the req.headers property will return a case-insensitive dictionary of the response headers. So, what does this imply?
This means that req.headers[‘Content-Length’], req.headers[‘content-length’] and req.headers[‘CONTENT-LENGTH’] will all return the value of the just the ‘Content-Length’ response header.
We can also check if the response obtained is a well-formed HTTP redirect (or not) that could have been processed automatically using the req.is_redirect property. This will return True or False based on the response obtained.
You can also get the time elapsed between sending the request and getting back a response using another property. Take a guess? Yes, it is the req.elapsed property.
Remember the URL that you initially passed to the get() function? Well, it can be different than the final URL of the response for many reason and this includes redirects as well.
And to see the actual response URL, you can use the req.url property.
import requests
req = requests.get('http://www.edureka.co/')
req.encoding # returns 'utf-8'
req.status_code # returns 200
req.elapsed # returns datetime.timedelta(0, 1, 666890)
req.url # returns 'https://edureka.co/'
req.history
req.headers['Content-Type']
# returns 'text/html; charset=utf-8'
Don’t you think that getting all this information about the webpage is nice? But, the thing is that you most probably want to access the actual content, correct?
If the content you are accessing is text, you can always use the req.text property to access it. Do note that the content is then parsed as unicode only. You can pass this encoding with which to decode this text using the req.encoding property like we discussed earlier.
In the case of non-text responses, you can access them very easily. In fact it’s done in binary format when you use req.content. This module will automatically decode gzip and deflate transfer-encodings for us. This can be very helpful when you are dealing directly with media files. Also, you can access the JSON-encoded content of the response as well, that is if it exists, using the req.json() function.
Pretty simple and a lot of flexibility, right?
Also, if needed, you can also get the raw response from the server just by using req.raw. Do keep in mind that you will have to pass stream=True in the request to get the raw response as per need.
But, some files that you download from the internet using the Requests module may have a huge size, correct? Well, in such cases, it will not be wise to load the whole response or file in the memory at once. But, it is recommended that you download a file in pieces or chunks using the iter_content(chunk_size = 1, decode_unicode = False) method.
So, this method iterates over the response data in chunk_size number of bytes at once. And when stream=True on the request, this method will avoid reading the whole file into memory at once for just the large responses.
Do note that the chunk_size parameter can be either an integer or None. But, when set to an integer value, chunk_size determines the number of bytes that should be read into the memory at once.
When chunk_size is set to None and stream is set to True, the data will be read as it arrives in whatever size of chunks are received as and when they are. But, when chunk_size is set to None and stream is set to False, all the data will be returned as a single chunk of data only.
Next up in this “Requests Tutorial” blog, lets see how we can download an image using Requests module.
So let’s download the following image of a forest on Pixabay using the Requests module we learned about. Here is the actual image:

This is the code that you will need to download the image:
import requests
req = requests.get('path/to/forest.jpg', stream=True)
req.raise_for_status()
with open('Forest.jpg', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
print('Received a Chunk')
fd.write(chunk)
Note that the ‘path/to/forest.jpg’ is the actual image URL. You can put the URL of any other image here to download something else as well. This is just an example and the given image file is about 185kb in size and you have set chunk_size to 50,000 bytes.
This means that the “Received a Chunk” message should print four times in the terminal. The size of the last chunk will just be 39350 bytes because the part of the file that remains to be received after the first three iterations is 39350 bytes.
Requests also allow you to pass parameters in a URL. This is particularly helpful when you are searching for a webpage for some results like a tutorial or a specific image. You can provide these query strings as a dictionary of strings using the params keyword in the GET request. Check out this easy example:
import requests
query = {'q': 'Forest', 'order': 'popular', 'min_width': '800', 'min_height': '600'}
req = requests.get('https://pixabay.com/en/photos/', params=query)
req.url
# returns 'https://pixabay.com/en/photos/?order=popular_height=600&q=Forest&min_width=800'
Next up in this “Requests Tutorial” blog, let us look at how we can make a POST request!
Making a POST request is just as easy as making GET requests. You just use the post() function instead of get().
This can be useful when you are automatically submitting forms. For example, the following code will download the whole Wikipedia page on Nanotechnology and save it on your PC.
import requests
req = requests.post('https://en.wikipedia.org/w/index.php', data = {'search':'Nanotechnology'})
req.raise_for_status()
with open('Nanotechnology.html', 'wb') as fd:
for chunk in req.iter_content(chunk_size=50000):
fd.write(chunk)
As previously mentioned, you can access the cookies and headers that the server sends back to you using req.cookies and req.headers. Requests also allow you to send your own custom cookies and headers with a request. This can be helpful when you want to, let’s say, set a custom user agent for your request.
To add HTTP headers to a request, you can simply pass them in a dict to the headers parameter. Similarly, you can also send your own cookies to a server using a dict passed to the cookies parameter.
import requests
url = 'http://some-domain.com/set/cookies/headers'
headers = {'user-agent': 'your-own-user-agent/0.0.1'}
cookies = {'visit-month': 'February'}
req = requests.get(url, headers=headers, cookies=cookies)
Cookie jar can also store cookies. They provide a more complete interface to allow you to use those cookies over multiple paths.
Check out this example below:
import requests
jar = requests.cookies.RequestsCookieJar()
jar.set('first_cookie', 'first', domain='httpbin.org', path='/cookies')
jar.set('second_cookie', 'second', domain='httpbin.org', path='/extra')
jar.set('third_cookie', 'third', domain='httpbin.org', path='/cookies')
url = 'http://httpbin.org/cookies'
req = requests.get(url, cookies=jar)
req.text
# returns '{ "cookies": { "first_cookie": "first", "third_cookie": "third" }}'
Next up on this “Requests Tutorial” blog, let us look at session objects!
Sometimes it is useful to preserve certain parameters across multiple requests. The Session object does exactly that. For example, it will persist cookie data across all requests made using the same session.
The Session object uses urllib3’s connection pooling. This means that the underlying TCP connection will be reused for all the requests made to the same host.
This can significantly boost the performance. You can also use methods of the Requests object with the Session object.
Sessions are also helpful when you want to send the same data across all requests. For example, if you decide to send a cookie or a user-agent header with all the requests to a given domain, you can use Session objects.
Here is an example:
import requests
ssn = requests.Session()
ssn.cookies.update({'visit-month': 'February'})
reqOne = ssn.get('http://httpbin.org/cookies')
print(reqOne.text)
# prints information about "visit-month" cookie
reqTwo = ssn.get('http://httpbin.org/cookies', cookies={'visit-year': '2017'})
print(reqTwo.text)
# prints information about "visit-month" and "visit-year" cookie
reqThree = ssn.get('http://httpbin.org/cookies')
print(reqThree.text)
# prints information about "visit-month" cookie
As you can see, the “visit-month” session cookie is sent with all three requests. However, the “visit-year” cookie is sent only during the second request. There is no mention of the “visit-year” cookie in the third request too. This confirms the fact that cookies or other data set on individual requests won’t be sent with other session requests.
The concepts discussed in this tutorial should help you make basic requests to a server by passing specific headers, cookies, or query strings.
This will be very handy when you are trying to scrape some webpages for information. Now, you should also be able to automatically download music files and wallpapers from different websites once you have figured out a pattern in the URLs.
After reading this blog on Requests tutorial using Python, I am pretty sure you want to know more about Python. To know more about Python you can refer the following blogs:
Python Tutorial For Beginners | Edureka




































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP