
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!In the previous blog posts we saw how to start with Pig Programming and Scripting. We have seen the steps to write a Pig Script in HDFS Mode and Pig Script Local Mode without UDF. In the third part of this series we will review the steps to write a Pig script with UDF in HDFS Mode.
We have explained how to implement Pig UDF by creating built-in functions to explain the functionality of Pig built-in function. For better explanation, we have taken two built-in functions. We have done this with the help of a pig script.
Here, we have taken one example and we have used both the UDF (user defined functions) i.e. making a string in upper case and taking a value & raising its power.
The dataset is depicted below which we are going to use in this example:
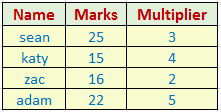
Our aim is to make 1st column letter in upper case and raising the power of the 2nd column with the value of 3rd column.
Let’s start with writing the java code for each UDF. Also we have to configure 4 JARs in our java project to avoid the compilation errors.
First, we will create java programs, both are given below:
import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.data.Tuple;
import org.apache.pig.impl.util.WrappedIOException;
@SuppressWarnings("deprecation")
public class Upper extends EvalFunc<String> {
public String exec(Tuple input) throws IOException {
if (input == null || input.size() == 0)
return null;
try {
String str = (String) input.get(0);
str=str.toUpperCase();
return str;
}
catch (Exception e) {
throw WrappedIOException.wrap("Caught exception processing input row ", e);
}
}
}import java.io.IOException;
import org.apache.pig.EvalFunc;
import org.apache.pig.PigWarning;
import org.apache.pig.data.Tuple;
public class Pow extends EvalFunc<Long> {
public Long exec(Tuple input) throws IOException {
try {
int base = (Integer)input.get(0);
int exponent = (Integer)input.get(1);
long result = 1;
/* Probably not the most efficient method...*/
for (int i = 0; i < exponent; i++) {
long preresult = result;
result *= base;
if (preresult > result) {
// We overflowed. Give a warning, but do not throw an
// exception.
warn("Overflow!", PigWarning.TOO_LARGE_FOR_INT);
// Returning null will indicate to Pig that we failed but
// we want to continue execution.
return null;
}
}
return result;
} catch (Exception e) {
// Throwing an exception will cause the task to fail.
throw new IOException("Something bad happened!", e);
}
}
}To remove compilation errors, we have to configure 4 JARs in our java project.
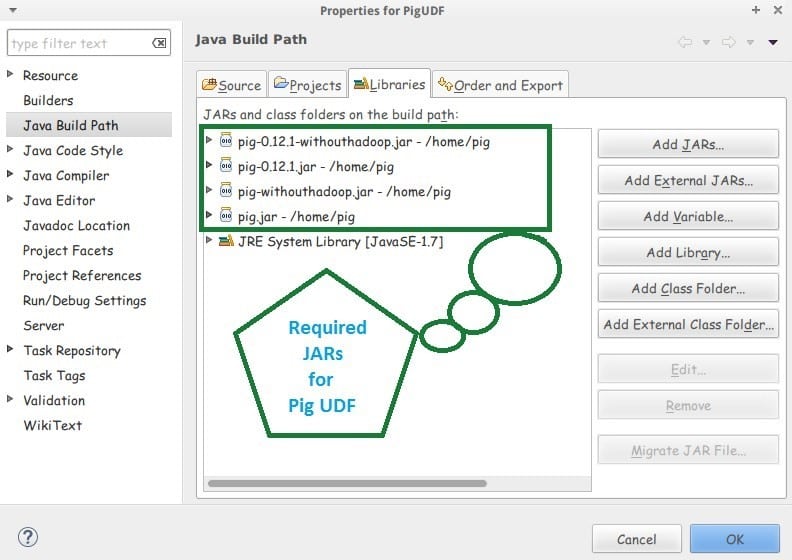
Click on the Download button to download the JARs
[buttonleads form_title=”Download Code” redirect_url=https://edureka.wistia.com/medias/wtboe1hmkr/download?media_file_id=76900193 course_id=166 button_text=”Download JARs”]
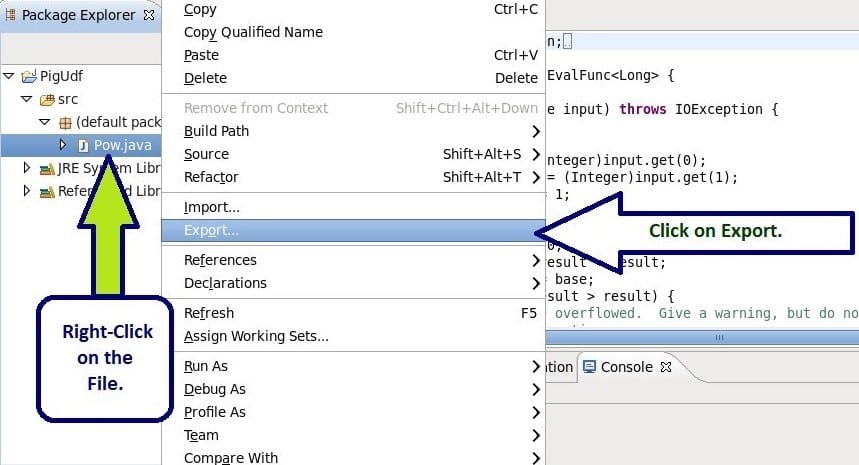
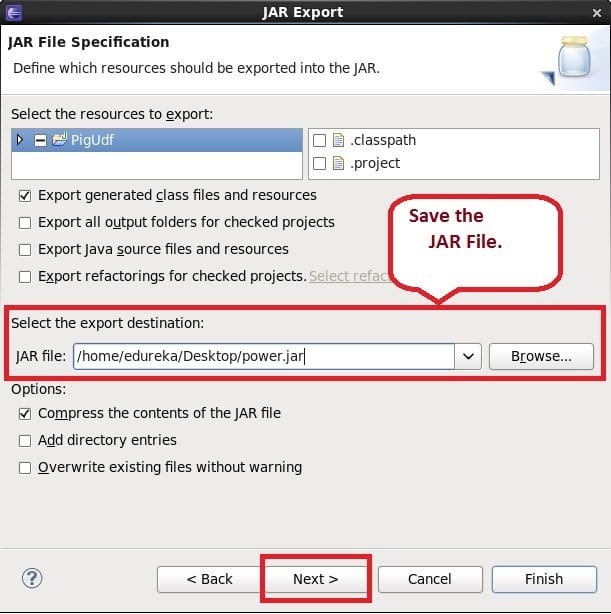
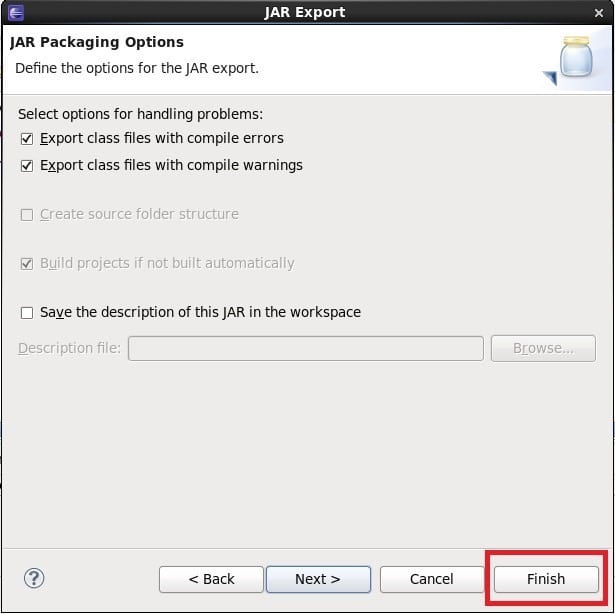
Now, we export JAR files for both the java codes. Please check the below steps for JAR creation.
Here, we have shown for one program, proceed in the same way in the next program as well.
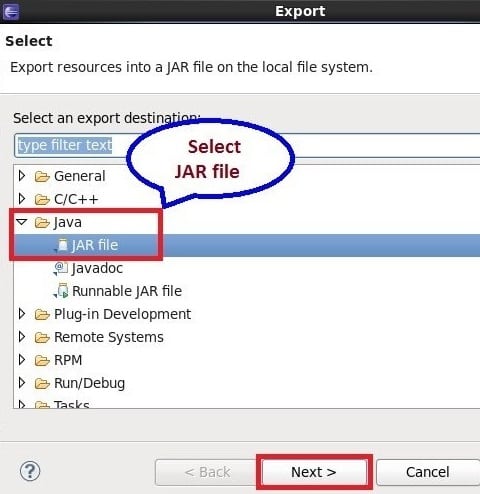
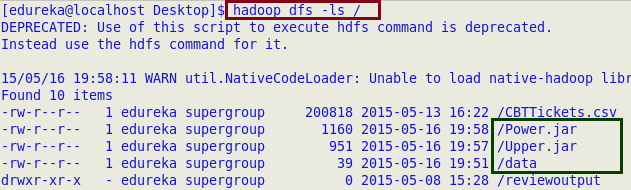
After creating the JARs and text files, we have moved all the data to HDFS cluster, which is depicted by the following images:
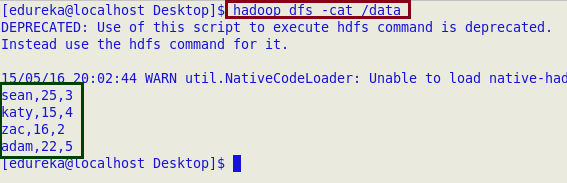
In our dataset, fields are comma (,) separated.
After moving the file, we have created script with .pig extension and put all the commands in that script file.
Now in terminal, type PIG followed by the name of the script file which is shown in the following image:
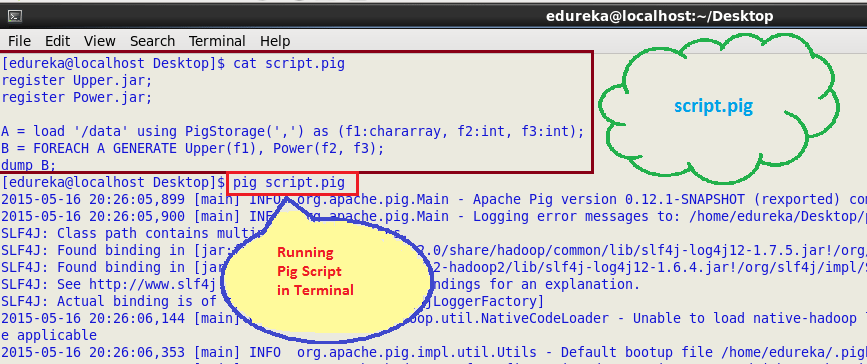
Here, this is the output for running the pig script.

Got a question for us? Please mention them in the comments section and we will get back to you.
Related Posts:







































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP








script.pig code please..
How to modify the RDBMs’ Nested SQL queries into Hadoop framework using Pig.
Hey Aamir, thanks for checking out our blog. You can write a query in SQL and then translate it into Pig Latin as
Syntax:
WHERE → FILTER
The syntax is different, but conceptually this is still putting your data into a funnel to create a smaller dataset.
HAVING → FILTER
Because a FILTER is done in a separate step from a GROUP or an aggregation, the distinction between HAVING and WHERE doesn’t exist in Pig.
ORDER BY → ORDER
This keyword behaves pretty much the same in Pig as in SQL.
Example:
AVERAGE SALARY BY LOCATION
SQL
SELECT loc, AVG(sal) FROM emp JOIN dept USING(deptno) WHERE sal >3000 GROUP BY loc;
PIG LATIN
filtered_emp = FILTER emp BY sal > 3000;
emp_join_dept = JOIN filtered_emp BY deptno, dept BY deptno;
grouped_by_loc = GROUP emp_join_dept BY loc;
avg_salary = FOREACH grouped_by_loc GENERATE group, AVG(emp_join_dept.sal);
Hope this helps. Cheers!
2015-06-13 08:15:01,140 [main] ERROR org.apache.pig.tools.grunt.Grunt – ERROR 1070: Could not resolve MyUpper using imports: [, java.lang., org.apache.pig.builtin., org.apache.pig.impl.builtin.]
Im getting error when i try to register my udf and execute the pig script
I created the UDF inside a package org.ms.pig.udf.xxx and this is the root cause…Looks like the simpe register function of JAR will not help in this case…Could you please help me with command to register the UDF if its in a package
Hi Ms, Let us assume I have placed Upper class is in a package pig.udf.examples, while registering the jar the command would be same. register name_of_jar;
But while using the UDF/class we need to give package name of that class as well.
E.g: B = foreach A generate pig.udf.examples.Upper(f1);
Generally classes are written inside specific packages only. We never write in default package.
That being the case, we must always refer the UDF by fully qualified name of class.
But the built-in functions are referable by unqualified class name only. This makes code more readable. I think, the default pig engine searches for function classes in some standard packages java.lang., org.apache.pig.builtin., etc. Is there a way to similarly refer UDF’s without package name? May be by declaring our own package in list of standard packages?
Your jar wont be successful because, .class files for Upper are missing.
jar creation will throw this error :
class file fpr Upper.java not found in lasspath
Am getting that error. How to resolve that issue. ??
Hi Dilip, try adding pig-0.8.0-cdh3u0-core.jar in the Java Project and try it out again.
Hi,
Am not able to find the link to download the file that you have mentioned. Can you please provide the link to download that file. Am trying out many options to run my udf. But got stuck here. Kindly provide me the soultion asap. Thanks in advance!!
Hi Dilip, we can add any Pig library jar file to our project to run UDF program. Use the following link to download the required jar file.
“https://edureka.wistia.com/medias/uovcf7gcyt/download?media_file_id=76020493”
Hi Utkarsh, you might have missed to add pig-0.8.0-cdh3u0-core.jar in the Java Project. Trying adding it again and creating.
This program also required additional jar files(hadoop_commons and commons_logging), also compilation error in java program. Please correct
Hi Wasim, as we have used just Pig API here, we don’t need to add the other jars for this UDF.
Adding the extra jars will depend on the API used in the UDF written.
You might be receiving the compilation error, if Pig-0.8.0-cdh3u0-core.jar is not added to that project properly. Check if you have selected this jar in the Order and Exports tab of Configuring Build Path and then try it once again.