
Advanced Certification in Agentic AI Engineer ...
- 66k Enrolled Learners
- Weekend
- Live Class
(45931)





 Copy Link!
Copy Link!In recent years, the rise of Artificial Intelligence has brought about significant advancements in natural language processing, making it possible for machines to understand and generate human-like text. Among the various AI models, LLM vs SLM have garnered attention for their ability to tackle language-related tasks. While both are built on similar principles, they differ greatly in terms of scale, application, and resource requirements.
In this blog, we will explore the key differences between LLM vs SLM, diving into their capabilities, strengths, and use cases, and help you understand which model is best suited for your specific needs.
Small Language Models (SLMs) are a specialized subset of artificial intelligence designed for Natural Language Processing (NLP) tasks. Their compact architecture allows them to operate efficiently while delivering precise, targeted insights.
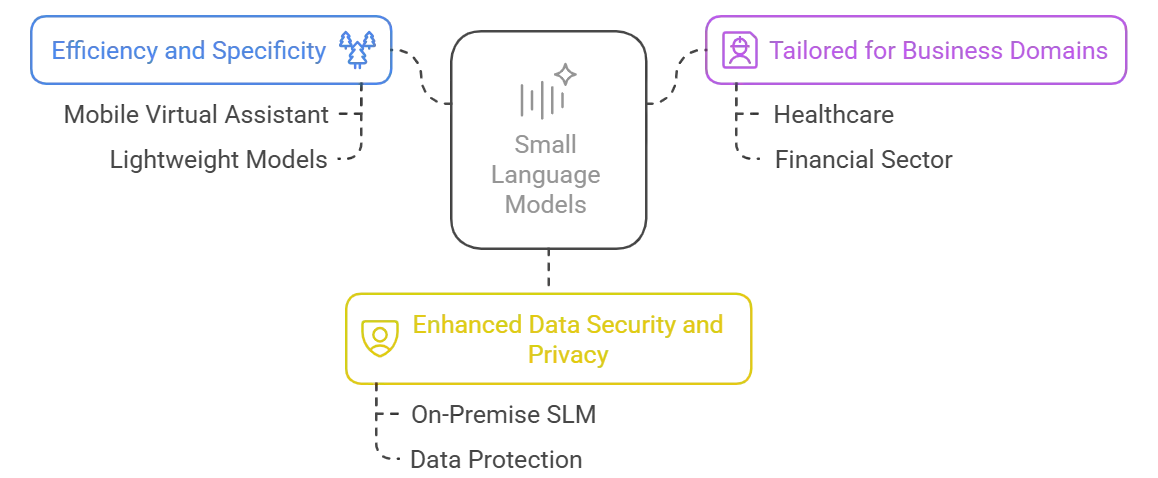 1. Efficiency and Specificity
1. Efficiency and Specificity
SLMs are designed to do certain language jobs very accurately while using a lot less computer power. Because they are simpler, they are cheaper and easier to set up, especially in places where resources are limited.
2. Tailored for Business Domains
SLMs can be changed to fit the needs of specific industries, like healthcare, customer service, and IT. By focusing on niche needs, they give useful information that directly addresses the problems and requirements of these businesses.
3. Enhanced Data Security and Privacy
SLMs are made to meet strict privacy and security standards so that private information is kept safe. Their small size gives you more control over how data is processed, which keeps your private data safe.
Real-World Applications
SLMs have a transformative impact across various domains, including:
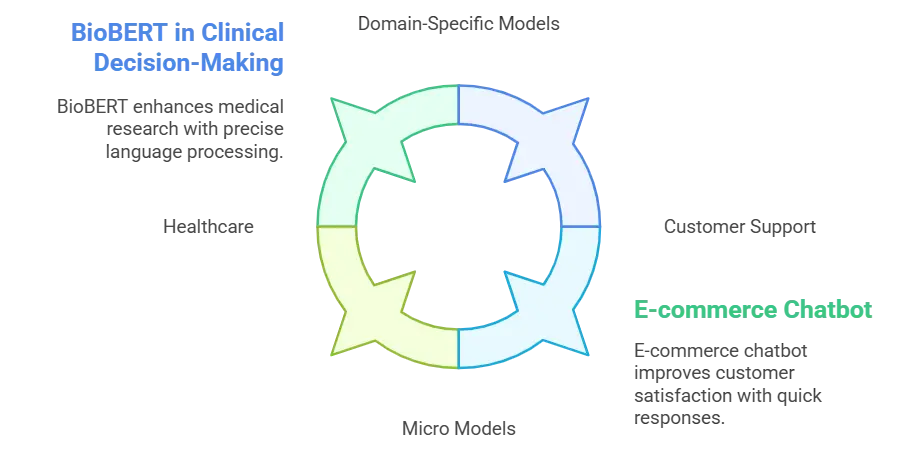 Domain-Specific Models in Healthcare: SLMs can be changed to handle complicated medical data, which helps with diagnosis and patient care by giving correct, domain-specific information.
Domain-Specific Models in Healthcare: SLMs can be changed to handle complicated medical data, which helps with diagnosis and patient care by giving correct, domain-specific information.While Small Language Models bring focused precision to specific tasks, let’s now shift our attention to models that leverage scale for broader, more diverse applications.
Large Language Models (LLMs) are advanced AI systems engineered to understand and generate human-like text. They rely on extensive training data and sophisticated neural architectures to tackle a broad spectrum of language-related tasks.
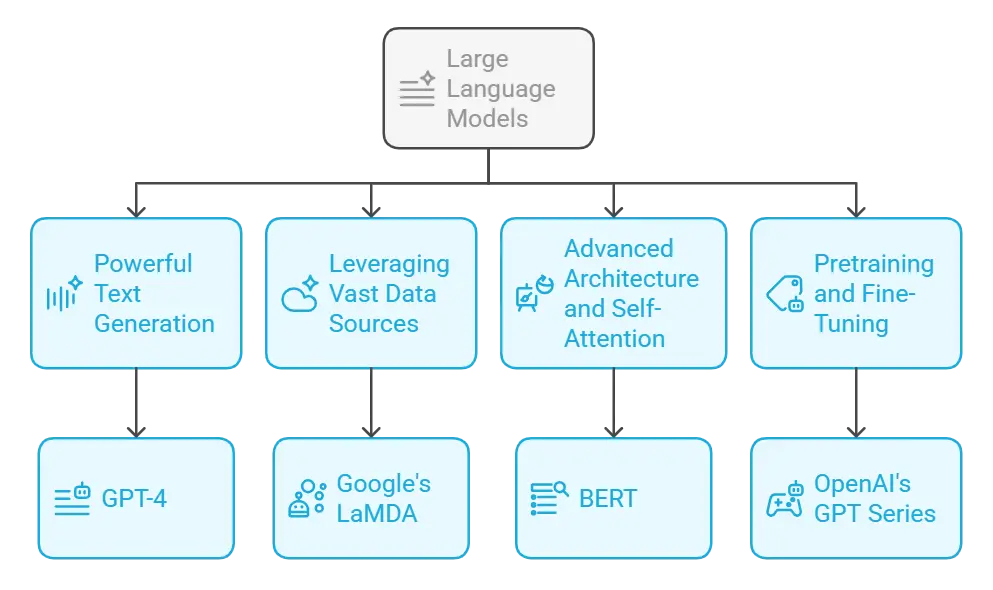 1. Powerful Text Generation
1. Powerful Text Generation
LLMs employ probabilistic machine learning to predict and generate coherent sequences of text. This capability enables them to create detailed, context-aware responses that mimic natural human conversation.
2. Leveraging Vast Data Sources
Trained on massive internet datasets, LLMs can distill information into concise and relevant answers. This approach transforms how users access and interpret information, reducing the need for manual searches.
3. Advanced Architecture and Self-Attention
At the heart of LLMs is the transformer architecture, which uses self-attention mechanisms to understand the relationships between words and phrases. This advanced processing allows for nuanced comprehension and the generation of contextually accurate responses.
4. Pretraining and Fine-Tuning
LLMs undergo extensive pretraining on diverse datasets, which is then refined through fine-tuning for specific tasks. This two-step process enhances performance and helps mitigate biases, ensuring the outputs are both reliable and relevant.
Wide-Ranging Applications
LLMs have a transformative impact across various domains, including:
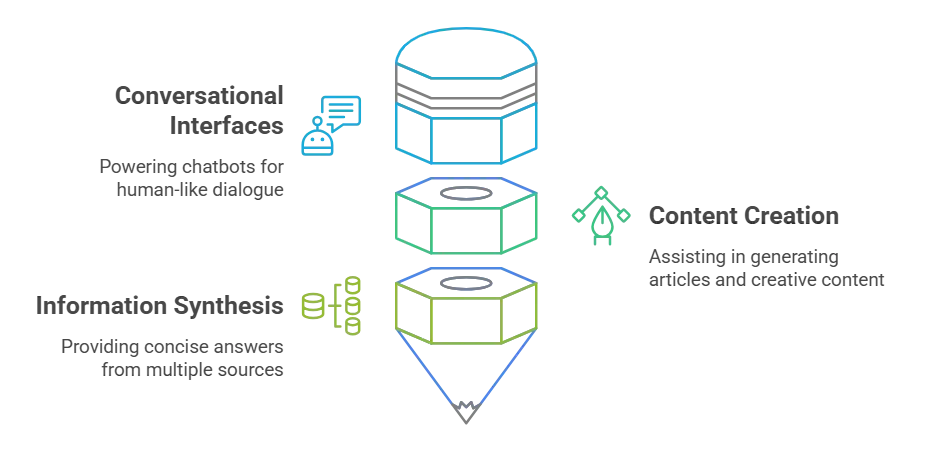 Conversational Interfaces: Powering chatbots and virtual assistants to engage in natural, meaningful dialogue.
Conversational Interfaces: Powering chatbots and virtual assistants to engage in natural, meaningful dialogue.Having explored the capabilities of Large Language Models, let’s now compare them with their smaller, specialized counterparts by examining the key differences in design, functionality, and application.
Both SLM and LLM are built on the same foundational principles of probabilistic machine learning, guiding their architectural design, training, data generation, and model evaluation.
However, there are key distinctions that set them apart in terms of scale, application, and resource requirements. Now, let’s explore what differentiates SLM and LLM technologies.
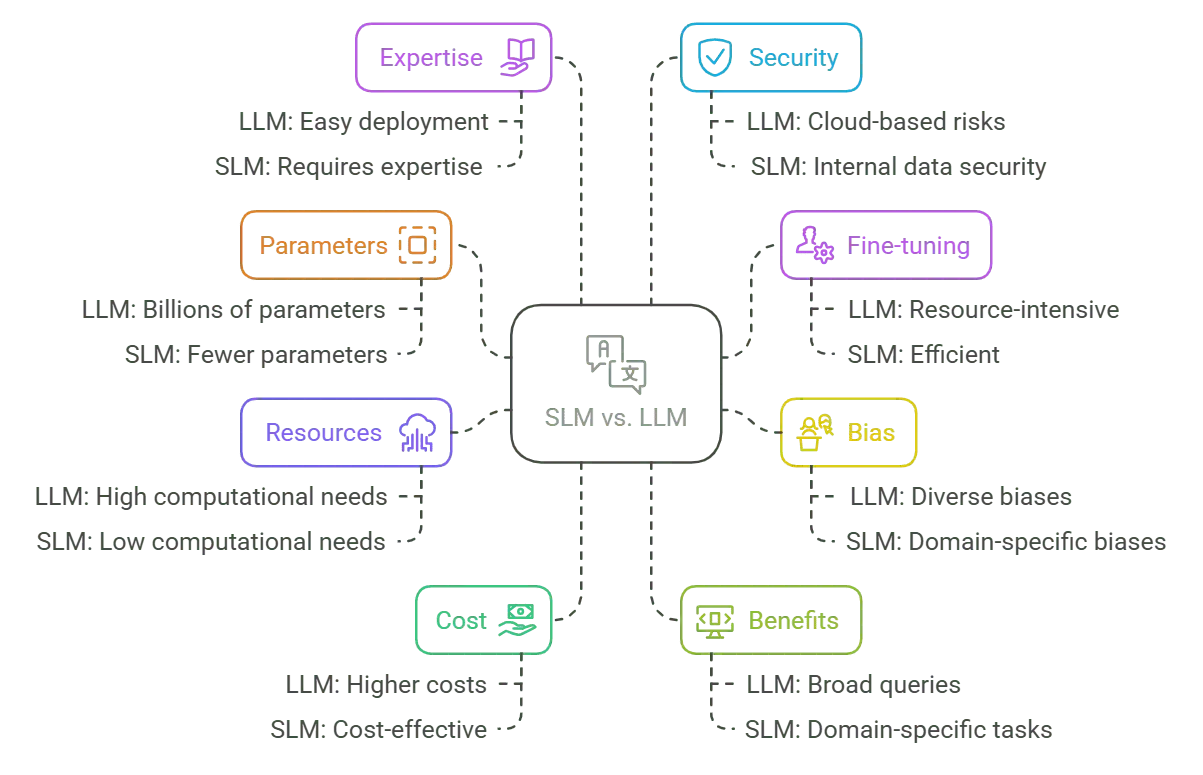 LLM vs SLM: Parameters
LLM vs SLM: ParametersThe internal factors that let a language model make predictions are called parameters. To pick up on a lot of different language trends, LLMs usually have a huge number of parameters, often in the billions or even trillions. SLMs, on the other hand, are made with fewer parameters and are better at specific jobs and niche areas than at understanding a lot of things in general.
Fine-tuning changes a model that has already been taught so that it works best for a certain task. Because they are bigger, LLMs need more time and resources to be fine-tuned, which makes the process more difficult and uses up a lot of resources. Because their design is simpler, SLMs can be fine-tuned more quickly, which makes them better for specific uses.
The data that language models are based on shows up as bias in them. Because LLMs are taught on very large and varied datasets, they can pick up a lot of biases without meaning to. SLMs, on the other hand, are trained on more focused, domain-specific datasets. This can help reduce unwanted biases by making the model more relevant to the application’s needs.
For LLMs to be trained and make conclusions, they need a lot of computing power, which usually comes from powerful GPUs and big cloud infrastructures. SLMs are made to run on hardware that doesn’t need as much power, sometimes even on mobile devices. This makes them a better choice for certain situations where resources are limited.
LLMs usually have more complex architectures, which means they cost more to train and run conclusions, especially when used on a large scale. Since SLMs use fewer resources than other options, they are a cost-effective choice for situations where saving money and time are important.
SLMs are better at doing precise work in their own fields, while LLMs are better at answering a wide range of general questions with a good understanding of the bigger picture. SLMs are designed to give useful information and good performance in situations where specific knowledge is important, which makes them ideal for niche uses.
The ease of using LLMs is often increased by the fact that models are already trained and ready to go. Customizing an SLM to a certain domain, on the other hand, usually takes more knowledge in both data science and the relevant field. This is to make sure that the model is perfectly tuned for its intended use.
Concerns about security are different for the two types. Since LLMs often use data from public sources and a lot of cloud-based APIs, sensitive data could be made public if they are not handled properly. Because they are trained on controlled datasets in a particular domain, SLMs provide a higher level of security and better meet data privacy requirements.
In this video, we’ll explore the key differences between Large Language Models (LLMs) and Small Language Models (SLMs) to help you understand which one suits your needs. We’ll start by defining what LLMs and SLMs are, followed by why this comparison matters in AI development. Then, we’ll break down their performance, speed, cost, and efficiency, along with real-world use cases to see where each model excels. Finally, we’ll discuss the future of AI models and help you decide which one to choose for your projects.
In conclusion, both Small Language Models (SLMs) and Large Language Models (LLMs) serve distinct purposes based on the scale and needs of the application. SLMs excel in providing targeted, efficient, and domain-specific solutions, making them ideal for businesses with specific requirements and limited resources. In contrast, LLMs leverage vast data sets and computational power to handle more generalized tasks, offering flexibility and broader knowledge but at higher costs and resource demands. The decision between SLMs and LLMs ultimately depends on the balance between precision, efficiency, and the scope of the intended application.
If you’re interested in mastering generative AI and prompt engineering, check out this comprehensive Generative AI Masters Training by Edureka to upskill yourself in this rapidly evolving field.













 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP


