



Full Stack Development Internship Program
- 29k Enrolled Learners
- Weekend/Weekday
- Live Class
(11300)





 Copy Link!
Copy Link!Latent variable models are an extremely useful topic in machine learning and statistics. They contribute to the understanding of data’s hidden structures by incorporating variables that are not directly observed but inferred from observable data. These models are commonly used for dimensionality reduction, topic modeling, and generative models, among other things.
In this blog, we are going to see what latent variable models are, why they are important, the different types of latent variables, and how they are applied in various machine learning techniques.

Let’s dive in and explore the world of latent variables!
Latent variable models (LVMs) are statistical models that postulate that hidden (latent) variables influence observed data. These variables represent fundamental patterns that simplify the link between input and output. Examples include principal component analysis (PCA), variational autoencoders (VAEs), and generative adversarial networks.
You got the idea of what LVMs are—let’s move on to why they are important.
Here are a few keypoints:
Now that we understand their importance, let’s take a look at the different types of latent variables.
The two type of latent variable are:
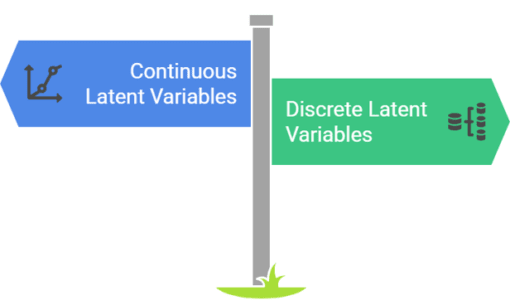
We’ve seen the types of latent variables—let’s see how they are used in machine learning.
Machine learning uses latent variables to capture abstract representations of data. This allows models to generalize more effectively and derive useful insights from the data.
You got the concept of latent variables in ML—now let’s explore them in PCA.
PCA minimizes data dimensionality by identifying new axes (principal components) that optimize variance.
import numpy as np
from sklearn.decomposition import PCA
# Sample data
X = np.array([[2.5, 2.4], [0.5, 0.7], [2.2, 2.9], [1.9, 2.2], [3.1, 3.0]])
# Applying PCA
pca = PCA(n_components=1)
X_reduced = pca.fit_transform(X)
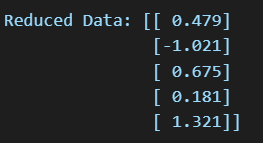
print("Reduced Data:", X_reduced)
The output which we are getting is:
Now that we’ve seen PCA in action, let’s move on to Latent Semantic Analysis.
LSA identifies hidden topics in text data by reducing the term-document matrix to a lower-dimensional space.
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample documents
documents = ["The cat sat on the mat", "The dog barked at the cat", "The cat chased the mouse"]
# TF-IDF Vectorization
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# Applying LSA
lsa = TruncatedSVD(n_components=2)
X_topics = lsa.fit_transform(X)
print("Topic Representation:", X_topics)
We’ve covered LSA—now let’s discuss latent variables in deep learning.
Deep learning models use latent spaces to describe abstract data. These spaces aid in model generalization and understanding of the data’s underlying structure.
With that understanding, let’s see how latent variables work in Variational Autoencoders.
VAEs learn to encode and decode data, guaranteeing that the latent space has a specified distribution.
</p>
from sklearn.decomposition import TruncatedSVD
from sklearn.feature_extraction.text import TfidfVectorizer
# Sample documents
documents = ["The cat sat on the mat", "The dog barked at the cat", "The cat chased the mouse"]
# TF-IDF Vectorization
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(documents)
# Applying LSA
lsa = TruncatedSVD(n_components=2)
X_topics = lsa.fit_transform(X)
print("Topic Representation:", X_topics)
Finally, let’s explore the role of latent variables in Generative Adversarial Networks.
GANs employ latent variables (random noise) to generate realistic data via an adversarial training procedure.
</p>
import numpy as np
# Random noise vector (latent variable)
latent_variable = np.random.normal(0, 1, size=(1, 100))
print("Latent Variable:", latent_variable)
Latent variables are critical for detecting hidden structures in data, lowering dimensionality, and producing new information. Latent variable models improve our ability to read, analyze, and create data, making them an essential component of modern machine learning and AI.
In GAN (Generative Adversarial Network), a latent variable is a hidden, random input — typically a noise vector — that the generator transforms into realistic-looking data (such as photos or text). It captures the underlying patterns without requiring direct observation.
Here is the code example you can refer to:
import numpy as np # Latent variable: Random noise vector latent_variable = np.random.normal(0, 1, size=(1, 100)) # 100-dimensional noise print(latent_variable)
It is a statistical method in which seen data is supposed to be dependent on hidden (latent) variables. These hidden variables simplify complex data relationships, allowing models such as GANs and VAEs to generate new data from previously learnt distributions.
Latent space is a compressed, abstract representation of data, with each point encoding important information. In GANs or VAEs, sampling from this space produces a variety of outputs while retaining the original data’s features. Think of it as the model’s imagination.
In an image-generating GAN, a latent variable could represent abstract qualities such as “smile intensity” or “hair color” – things that influence the output but are not directly provided in the input.
It’s a model whose output is determined by an unobserved latent process. For example, in time series or image production, the underlying characteristics evolve through hidden states that influence the observed behavior.




























