
DevOps Certification Training
- 187k Enrolled Learners
- Weekend/Weekday
- Live Class
(79900)





 Copy Link!
Copy Link!
Interested in a career in DevOps? Well then, you have landed on the right article. In the DevOps Interview Questions article, I have listed dozens of possible questions that interviewers ask potential DevOps hires. This list has been crafted based on the know-how of Edureka instructors who are industry experts and the experiences of nearly 30,000 Edureka DevOps learners from 60 countries.
The key point to remember is that DevOps is more than just a set of technologies; it is a way of thinking, a culture. DevOps requires a cultural shift that merges operations with development and demands a linked toolchain of technologies to facilitate collaborative change. Since the DevOps philosophy is still at a very nascent stage, the application of DevOps as well as the bandwidth required to adapt and collaborate varies from organization to organization. However, you can develop DevOps skills that can present you as a perfect candidate for any type of organization.
We would be delighted to assist you in developing your DevOps skills in a thoughtful, structured manner and becoming certified as a DevOps Engineer. Once you finish the DevOps Certification, we promise that you will be able to handle a variety of DevOps roles in the industry.
What are the requirements to become a DevOps Engineer?
When looking to fill out DevOps roles, organizations look for a clear set of skills. The most important of these are:
If you have the above skills, then you are ready to start preparing for your DevOps interview! If not, don’t worry – our DevOps certification training will help you master DevOps.
In order to structure the questions below, I put myself in your shoes. Most of the answers in this blog are written from your perspective, i.e. someone who is a potential DevOps expert. I have also segregated the questions in the following manner:
If you have attended interviews or have any additional questions you would like answered, please do mention them in our Q&A Forum. We’ll get back to you at the earliest.
DevOps Interview Questions | DevOps Interview Questions & Answers – 2025 | DevOps Training | Edureka
These are the top Interview questions you might face in a DevOps job interview.
This category will include DevOps Interview questions and Answers that are not related to any particular DevOps stage. Questions here are meant to test your understanding about DevOps rather than focusing on a particular tool or a stage.
Q1.What is DevOps?
DevOps is a software development method that combines the techniques of software development (Dev) and IT operations (Ops) to encourage collaboration, automation, and ongoing growth. It aims to improve the quality, speed, and stability of software updates and make the software delivery process more efficient. DevOps puts a lot of emphasis on automation, continuous integration, continuous delivery, and a mindset of working together to make software development and release faster and more efficient.
The differences between DevOps vs Agile are listed down in the table below.
| Features | DevOps | Agile |
|---|---|---|
| Agility | Agility in both Development & Operations | Agility in only Development |
| Processes/ Practices | Involves processes such as CI, CD, CT, etc. | Involves practices such as Agile Scrum, Agile Kanban, etc. |
| Key Focus Area | Timeliness & quality have equal priority | Timeliness is the main priority |
| Release Cycles/ Development Sprints | Smaller release cycles with immediate feedback | Smaller release cycles |
| Source of Feedback | Feedback is from self (Monitoring tools) | Feedback is from customers |
| Scope of Work | Agility & need for Automation | Agility only |
A DevOps Engineer is a professional who combines expertise in software development, IT operations, and system administration to facilitate the adoption of DevOps practices within an organization. DevOps Engineers play a critical role in bridging the gap between development and operations teams to ensure the smooth and efficient delivery of software applications.
Responsibilities of a DevOps Engineer may include:
1. Collaboration: Facilitating communication and collaboration between development, operations, and other cross-functional teams to ensure alignment of goals and smooth workflows.
2. Automation: Developing and implementing automated processes for building, testing, and deploying software, as well as managing infrastructure and configuration.
3. Continuous Integration and Continuous Delivery (CI/CD): Designing and maintaining CI/CD pipelines to enable frequent and reliable software releases.
4. Infrastructure as Code (IaC): Implementing IaC principles to manage infrastructure and configuration through code, allowing for easy scaling and replication.
5. Monitoring and Performance: Setting up monitoring tools and performance metrics to ensure system stability, identify issues, and facilitate proactive problem-solving.
6. Security and Compliance: Integrating security measures into the development and deployment process, and ensuring compliance with industry standards and regulations.
7. Cloud Services: Utilizing cloud platforms and services to build scalable and resilient applications and infrastructure.
8. Troubleshooting and Support: Resolving issues related to software deployments, performance, and infrastructure, as well as providing technical support to development and operations teams.
9. Continuous Learning: Staying up-to-date with the latest DevOps tools, technologies, and best practices to continuously improve the organization’s software delivery processes.
A DevOps Engineer plays a pivotal role in driving a culture of continuous improvement, automation, and collaboration across the organization. By combining skills in software development and IT operations, they help streamline the development lifecycle, enhance application delivery, and promote efficiency and innovation in software development projects. If you are ready to launch your DevOps career consider taking DevOps Course Masters Program and master the skills needed to excel in this dynamic field. Gain hands-on experience with cutting-edge tools, learn industry best practices, and work on real-world DevOps projects. With personalized mentorship and an industry-recognized certification, you’ll be well-prepared for a successful DevOps career.
When setting up Django web applications in a DevOps environment, ensuring that automated tests run in the correct sequence is crucial for reliable CI/CD workflows. A common challenge developers face is sorting pre-conditions by execution order when running automated tests, especially in integration and end-to-end testing.
According to me, this answer should start by explaining the general market trend. Instead of releasing big sets of features, companies are trying to see if small features can be transported to their customers through a series of release trains. This has many advantages like quick feedback from customers, better quality of software etc. which in turn leads to high customer satisfaction. To achieve this, companies are required to:
DevOps fulfills all these requirements and helps in achieving seamless software delivery. You can give examples of companies like Etsy, Google and Amazon which have adopted DevOps to achieve levels of performance that were unthinkable even five years ago. They are doing tens, hundreds or even thousands of code deployments per day while delivering world-class stability, reliability and security.
If I have to test your knowledge on DevOps, you should know the difference between Agile and DevOps. The next question is directed towards that.
I would advise you to go with the below explanation:
Agile is a set of values and principles about how to produce i.e. develop software. Example: if you have some ideas and you want to turn those ideas into working software, you can use the Agile values and principles as a way to do that. But, that software might only be working on a developer’s laptop or in a test environment. You want a way to quickly, easily and repeatably move that software into production infrastructure, in a safe and simple way. To do that you need DevOps tools and techniques.
You can summarize by saying Agile software development methodology focuses on the development of software but DevOps on the other hand is responsible for development as well as deployment of the software in the safest and most reliable way possible. Here’s a blog that will give you more information on the evolution of DevOps.
Now remember, you have included DevOps tools in your previous answer so be prepared to answer some questions related to that.
The most popular DevOps tools are mentioned below:
You can also mention any other tool if you want, but make sure you include the above tools in your answer.
The second part of the answer has two possibilities:
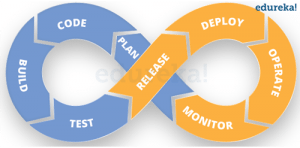
Given below is a generic logical flow where everything gets automated for seamless delivery. However, this flow may vary from organization to organization as per the requirement.

The DevOps pipeline, also known as the CI/CD pipeline (Continuous Integration/Continuous Delivery pipeline), is a series of automated steps and processes that facilitate the continuous integration, testing, and delivery of software applications from development to production. It serves as a fundamental framework in DevOps practices, enabling teams to streamline and automate the software development lifecycle, from code changes to the final deployment.
Key Stages in the DevOps Pipeline:
1. Code Commit and Version Control: Developers commit their code changes to a version control system (e.g., Git). This action triggers the pipeline to initiate the build and deployment process.
2. Continuous Integration (CI): Upon code commit, the CI stage automatically builds the application, compiles the code, and runs automated tests to ensure the new code integrates smoothly with the existing codebase.
3. Artifact Generation: Successful CI results in the generation of artifacts, such as binaries or packages, which are ready for deployment.
4. Continuous Delivery (CD): The CD stage involves deploying the generated artifacts to staging or pre-production environments for further testing and validation.
5. Automated Testing: In the CD stage, automated tests, including unit tests, integration tests, and acceptance tests, are executed to ensure the application’s correctness and quality.
6. Deployment: After passing all tests in the CD stage, the application is automatically deployed to production or customer-facing environments.
7. Monitoring and Feedback: Once the application is in production, the pipeline continues to monitor its performance and logs, providing valuable feedback to the development team.
The DevOps pipeline is a core component of modern software development practices, enabling teams to deliver high-quality software efficiently and consistently. It fosters collaboration, automation, and continuous integration, key principles in DevOps methodologies.
For this answer, you can use your past experience and explain how DevOps helped you in your previous job. If you don’t have any such experience, then you can mention the below advantages.
Technical benefits:
Business benefits:
According to me, the most important thing that DevOps helps us achieve is to get the changes into production as quickly as possible while minimizing risks in software quality assurance and compliance. This is the primary objective of DevOps. Learn more in this DevOps tutorial blog.
However, you can add many other positive effects of DevOps. For example, clearer communication and better working relationships between teams i.e. both the Ops team and Dev team collaborate together to deliver good quality software which in turn leads to higher customer satisfaction.
There are many industries that are using DevOps so you can mention any of those use cases, you can also refer the below example:
Etsy is a peer-to-peer e-commerce website focused on handmade or vintage items and supplies, as well as unique factory-manufactured items. Etsy struggled with slow, painful site updates that frequently caused the site to go down. It affected sales for millions of Etsy’s users who sold goods through online market place and risked driving them to the competitor.
With the help of a new technical management team, Etsy transitioned from its waterfall model, which produced four-hour full-site deployments twice weekly, to a more agile approach. Today, it has a fully automated deployment pipeline, and its continuous delivery practices have reportedly resulted in more than 50 deployments a day with fewer disruptions.
For this answer, share your past experience and try to explain how flexible you were in your previous job. You can refer the below example:
DevOps engineers almost always work in a 24/7 business-critical online environment. I was adaptable to on-call duties and was available to take up real-time, live-system responsibility. I successfully automated processes to support continuous software deployments. I have experience with public/private clouds, tools like Chef or Puppet, scripting and automation with tools like Python and PHP, and a background in Agile.
A pattern is common usage usually followed. If a pattern commonly adopted by others does not work for your organization and you continue to blindly follow it, you are essentially adopting an anti-pattern. There are myths about DevOps. Some of them include:
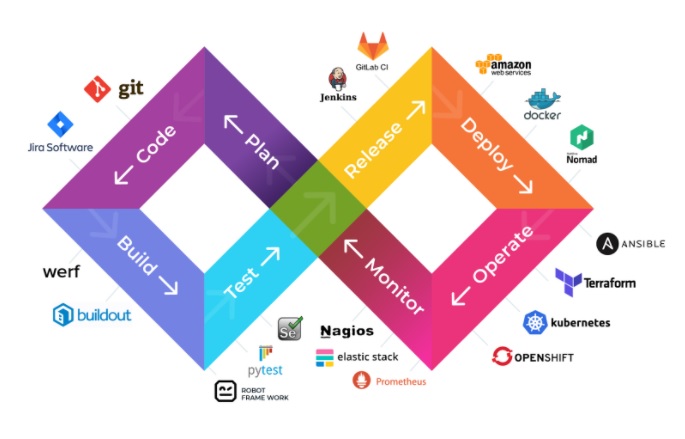
The various phases of the DevOps lifecycle are as follows:
KPI Means Key Performance Indicators are used to measure the performance of a DevOps team, identify mistakes and rectify them. This helps the DevOps team to increase productivity and which directly impacts revenue.
There are many KPIs which one can track in a DevOps team. Following are some of them:
As we know before DevOps there are two other software development models:
In the waterfall model, we have limitations of one-way working and lack of communication with customers. This was overcome in Agile by including the communication between the customer and the company by taking feedback. But in this model, another issue is faced regarding communication between the Development team and operations team due to which there is a delay in the speed of production. This is where DevOps is introduced. It bridges the gap between the development team and the operation team by including the automation feature. Due to this, the speed of production is increased. By including automation, testing is integrated into the development stage. Which resulted in finding the bugs at the very initial stage which increased the speed and efficiency.
AWS [Amazon Web Services ] is one of the famous cloud providers. In AWS DevOps is provided with some benefits:
Configuration management is the process of keeping track of and directing how software, hardware, and IT system parts are set up. It includes keeping track of versions, managing changes, automating deployment, and keeping settings the same. This makes sure that the system is reliable, consistent, and follows standards. In current IT operations, software release and system management cannot be done without configuration management.
Need to level up your cloud skills? Enroll in our AWS DevOps Course and watch your career skyrocket!
The importance of configuration management in DevOps lies in its ability to bring consistency, stability, and efficiency to the software development and deployment process. Here are some key reasons why configuration management is crucial in DevOps:
1. Consistency and Reproducibility: Configuration management ensures that all software components, environments, and infrastructure are consistently set up and maintained across development, testing, and production stages. This consistency allows teams to reliably reproduce environments, reducing errors and ensuring predictable behavior during deployments.
2. Automated and Reliable Deployments: With configuration management tools, DevOps teams can automate the deployment process, reducing manual interventions and human errors. Automated deployments increase the reliability and speed of software releases, leading to quicker time-to-market.
3. Version Control and Change Management: Configuration management facilitates version control and change management for all configurations, including code, settings, and infrastructure. This enables tracking changes, easy rollbacks, and thorough auditing, fostering a more controlled and secure software development process.
4. Scalability and Flexibility: Infrastructure as Code (IaC) practices in configuration management allow teams to define and manage infrastructure using code. This provides scalability and flexibility to adjust infrastructure resources based on varying workloads and requirements.
5. Collaboration and Communication: Configuration management encourages better collaboration and communication between development and operations teams. By having a single source of truth for configurations, both teams can work together seamlessly and ensure that software deployments are aligned with operational needs.
6. Security and Compliance: Consistent configurations and automated security measures enforced through configuration management help maintain security standards and compliance with regulations. Regular audits and version control aid in identifying and addressing security vulnerabilities promptly.
7. Reduced Downtime and Faster Recovery: In case of failures, configuration management enables quick recovery by rolling back to a known, stable configuration. This minimizes downtime and ensures a faster resolution of issues.
8. Efficient Change Deployment: Configuration management streamlines the deployment of changes, allowing teams to focus on delivering new features and updates. It reduces the risk of configuration drift and enhances the overall efficiency of the development and deployment process.
In conclusion, configuration management is a critical aspect of DevOps as it brings order, automation, and consistency to the software development and deployment lifecycle. It empowers teams to deliver software faster, with fewer errors, and in a more controlled and reliable manner, contributing to the success of DevOps practices and principles.
DevOps work culture brings many technical and business benefits, including:
Technical Benefits:
Business Benefits:
The core operations of DevOps in terms of development and infrastructure are:
DevOps is not considered an Agile methodology, but it can be used in conjunction with Agile practices to improve the software development process. Agile methodology focuses on delivering small increments of working software frequently, while DevOps focuses on improving collaboration and communication between development and operations teams to increase efficiency and reduce the time it takes to release software to production. DevOps can be seen as a complementary approach to Agile, as it can help Agile teams to better achieve their goals of delivering software quickly and reliably.
DevOps Interview Questions for Version Control System (VCS)
Now let’s look at some interview questions and answers on VCS.
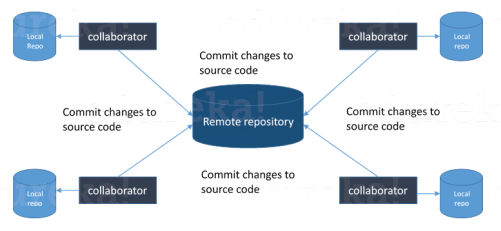
This is probably the easiest question you will face in the interview. My suggestion is to first give a definition of Version control. It is a system that records changes to a file or set of files over time so that you can recall specific versions later. Version control systems consist of a central shared repository where teammates can commit changes to a file or set of file. Then you can mention the uses of version control.
Version control allows you to:
I will suggest you to include the following advantages of version control:
This question is asked to test your branching experience so tell them about how you have used branching in your previous job and what purpose does it serves, you can refer the below points:
In the end tell them that branching strategies varies from one organization to another, so I know basic branching operations like delete, merge, checking out a branch etc.
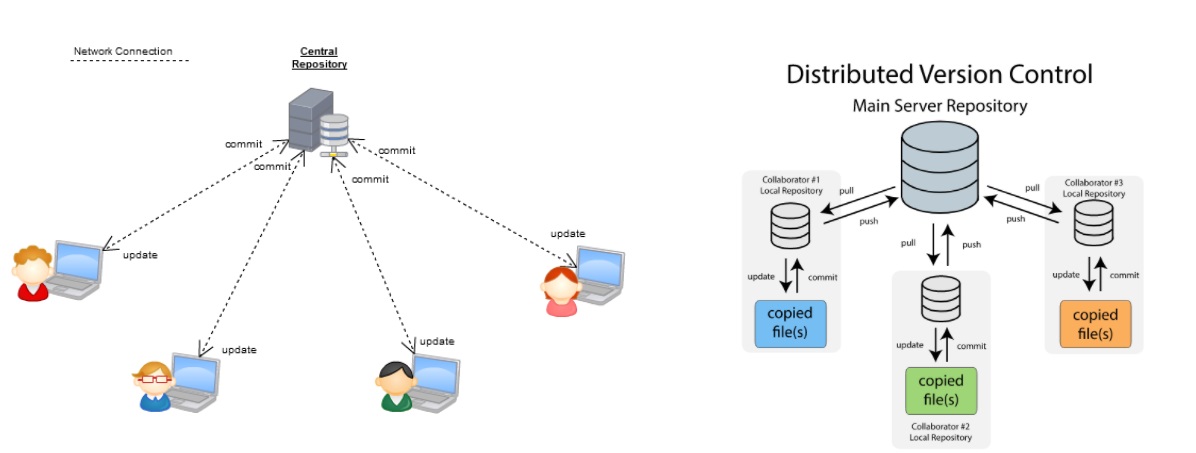
You can just mention the VCS tool that you have worked on like this: “I have worked on Git and one major advantage it has over other VCS tools like SVN is that it is a distributed version control system.”
Distributed VCS tools do not necessarily rely on a central server to store all the versions of a project’s files. Instead, every developer “clones” a copy of a repository and has the full history of the project on their own hard drive.
I will suggest that you attempt this question by first explaining about the architecture of git as shown in the below diagram. You can refer to the explanation given below:
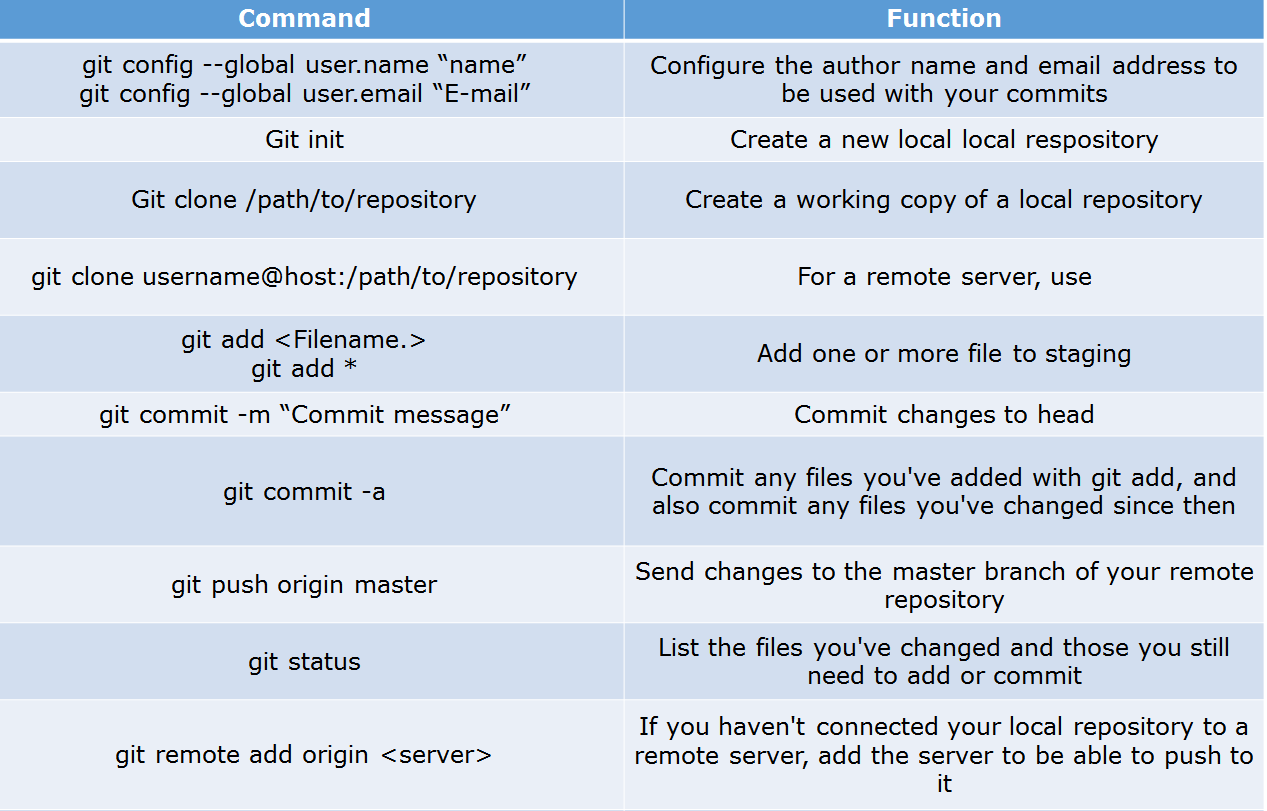
Below are some basic Git commands:
There can be two answers to this question so make sure that you include both because any of the below options can be used depending on the situation:
There are two options to squash last N commits into a single commit. Include both of the below mentioned options in your answer:
I will suggest you to first give a small definition of Git bisect, Git bisect is used to find the commit that introduced a bug by using binary search. Command for Git bisect is
git bisect <subcommand> <options>
Now since you have mentioned the command above, explain what this command will do, This command uses a binary search algorithm to find which commit in your project’s history introduced a bug. You use it by first telling it a “bad” commit that is known to contain the bug, and a “good” commit that is known to be before the bug was introduced. Then Git bisect picks a commit between those two endpoints and asks you whether the selected commit is “good” or “bad”. It continues narrowing down the range until it finds the exact commit that introduced the change.
According to me, you should start by saying git rebase is a command which will merge another branch into the branch where you are currently working, and move all of the local commits that are ahead of the rebased branch to the top of the history on that branch.
Now once you have defined Git rebase time for an example to show how it can be used to resolve conflicts in a feature branch before merge, if a feature branch was created from master, and since then the master branch has received new commits, Git rebase can be used to move the feature branch to the tip of master.
The command effectively will replay the changes made in the feature branch at the tip of master, allowing conflicts to be resolved in the process. When done with care, this will allow the feature branch to be merged into master with relative ease and sometimes as a simple fast-forward operation.
I will suggest you to first give a small introduction to sanity checking, A sanity or smoke test determines whether it is possible and reasonable to continue testing.
Now explain how to achieve this, this can be done with a simple script related to the pre-commit hook of the repository. The pre-commit hook is triggered right before a commit is made, even before you are required to enter a commit message. In this script one can run other tools, such as linters and perform sanity checks on the changes being committed into the repository.
Finally give an example, you can refer the below script:
#!/bin/sh files=$(git diff --cached --name-only --diff-filter=ACM | grep '.go$') if [ -z files ]; then exit 0 fi unfmtd=$(gofmt -l $files) if [ -z unfmtd ]; then exit 0 fi echo &amp;amp;ldquo;Some .go files are not fmt&amp;amp;rsquo;d&amp;amp;rdquo; exit 1&amp;lt;/wp-p&amp;gt; &amp;lt;wp-p style="text-align: justify;"&amp;gt;&amp;lt;span&amp;gt;
This script checks to see if any .go file that is about to be committed needs to be passed through the standard Go source code formatting tool gofmt. By exiting with a non-zero status, the script effectively prevents the commit from being applied to the repository.
For this answer instead of just telling the command, explain what exactly this command will do so you can say that, To get a list files that has changed in a particular commit use command
git diff-tree -r {hash}
Given the commit hash, this will list all the files that were changed or added in that commit. The -r flag makes the command list individual files, rather than collapsing them into root directory names only.
You can also include the below mention point although it is totally optional but will help in impressing the interviewer.
The output will also include some extra information, which can be easily suppressed by including two flags:
git diff-tree –no-commit-id –name-only -r {hash}
Here –no-commit-id will suppress the commit hashes from appearing in the output, and –name-only will only print the file names, instead of their paths.
There are three ways to configure a script to run every time a repository receives new commits through push, one needs to define either a pre-receive, update, or a post-receive hook depending on when exactly the script needs to be triggered.
Hooks are local to every Git repository and are not versioned. Scripts can either be created within the hooks directory inside the “.git” directory, or they can be created elsewhere and links to those scripts can be placed within the directory.
I will suggest you to include both the below mentioned commands:
git branch –merged lists the branches that have been merged into the current branch.
git branch –no-merged lists the branches that have not been merged.
| Centralized Version Control | Distributed Version control |
| In this, we will not be having a copy of the main repository on the local repository. | In this, all the developers will be having a copy of the main repository on their local repository |
| There is a need for the internet for accessing the main repository data because we will not be having another copy of the server on the local repository | There is no need for the internet for accessing the main repository data because we will be having another copy of the server on the local repository. |
| If the main server crashes then there will be a problem in accessing the server for the developers. | If there is a crash on the main server there will be no problem faced regarding the availability of the server. |
Here, both are merging mechanisms but the difference between the Git Merge and Git Rebase is, in Git Merge logs will be showing the complete history of commits.
However, when one does Git Rebase, the logs are rearranged. The rearrangement is done to make the logs look linear and simple to understand. This is also a drawback since other team members will not understand how the different commits were merged into one another.
| Git Pull | Git Fetch |
| DevOps is used to update the working directory with the latest changes from the remote server. | Git fetch gets new data from a remote repository to the local repository |
| Git pull is used to get the data to the local repository and the data is merged in the working repository | Git fetch is only used to get the data to the local repository but the data is not merged in the working repository |
| Command – git pull origin | Command – git fetch origin |
Shift left is a concept used in DevOps for a better level of security, performance, etc. Let us get in detail with an example, if we see all the phases in DevOps we can say that security is tested before the step of deployment. By using the left shift method we can include the security in the development phase which is on the left.[will be shown in the diagram] not only in development we can integrate with all phases like before development and in the testing phase too. This probably increases the level of security by finding the errors in the very initial stages.
Yes, here are some examples of version control systems that are in use today:
To create a branch in an existing project using Git, follow these steps:
git checkout -b <branch_name> to create a new branch with the name <branch_name>.git checkout <branch_name>.git merge <branch_name>.Note: Before creating a branch, it is recommended to sync your local repository with the remote repository to ensure you are working on the latest version of the project.
Tags are labels or keywords that describe the content of a web page or a blog post. They are used in HTML or XML code to categorize the content and make it easier for search engines and users to find relevant information.
For example, a blog post about cooking may have tags such as “recipe,” “food,” “cooking,” and “dinner.” This allows users to search for and find similar posts based on those tags.
In addition, tags can also be used to format and style text, such as headings, links, and images. The use of tags helps to organize and structure the content, making it easier for both users and search engines to understand.
Now, let’s look at Continuous Integration interview questions and answer:
I will advise you to begin this answer by giving a small definition of Continuous Integration (CI). It is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
I suggest that you explain how you have implemented it in your previous job. You can refer the below given example:
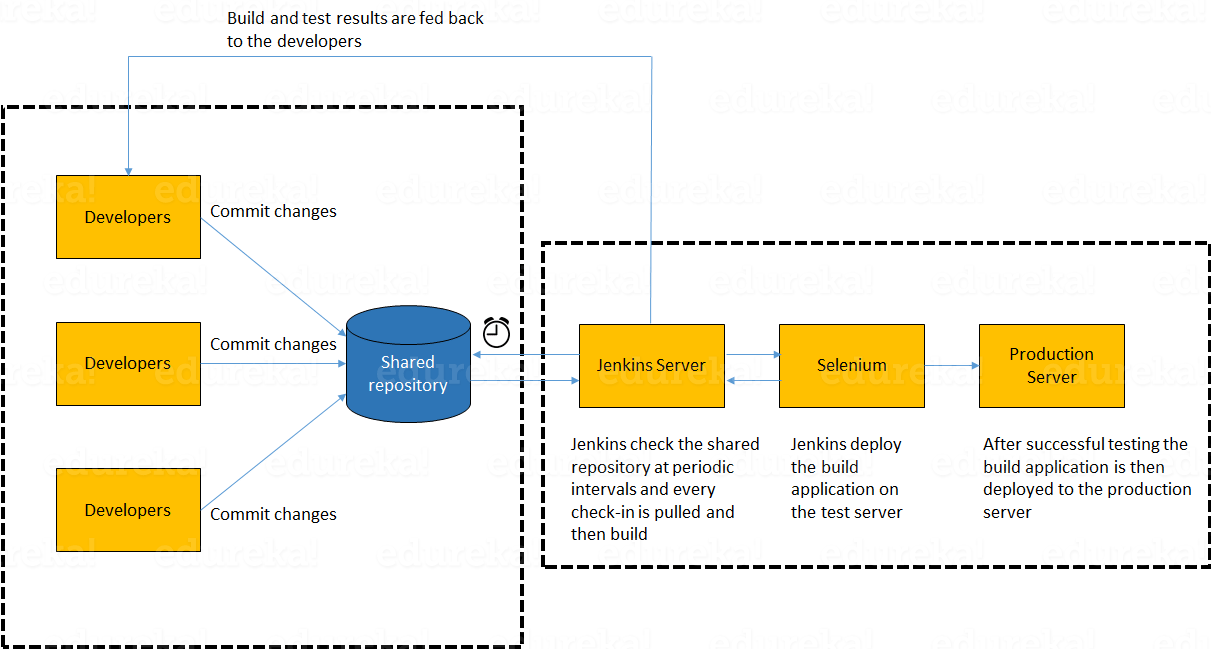
In the diagram shown above:
For this answer, you should focus on the need of Continuous Integration. My suggestion would be to mention the below explanation in your answer:
Continuous Integration of Dev and Testing improves the quality of software, and reduces the time taken to deliver it, by replacing the traditional practice of testing after completing all development. It allows Dev team to easily detect and locate problems early because developers need to integrate code into a shared repository several times a day (more frequently). Each check-in is then automatically tested.
Here you have to mention the requirements for Continuous Integration. You could include the following points in your answer:
I will approach this task by copying the jobs directory from the old server to the new one. There are multiple ways to do that; I have mentioned them below:
You can:
Answer to this question is really direct. To create a backup, all you need to do is to periodically back up your JENKINS_HOME directory. This contains all of your build jobs configurations, your slave node configurations, and your build history. To create a back-up of your Jenkins setup, just copy this directory. You can also copy a job directory to clone or replicate a job or rename the directory.
My approach to this answer will be to first mention how to create Jenkins job. Go to Jenkins top page, select “New Job”, then choose “Build a free-style software project”.
Then you can tell the elements of this freestyle job:
Below, I have mentioned some important Plugins:
These Plugins, I feel are the most useful plugins. If you want to include any other Plugin that is not mentioned above, you can add them as well. But, make sure you first mention the above stated plugins and then add your own.
The way I secure Jenkins is mentioned below. If you have any other way of doing it, please mention it in the comments section below:
Jenkins is one of the many popular tools that are used extensively in DevOps. Edureka’s DevOps Certification course will provide you hands-on training with Jenkins and high quality guidance from industry experts. Give it a look:
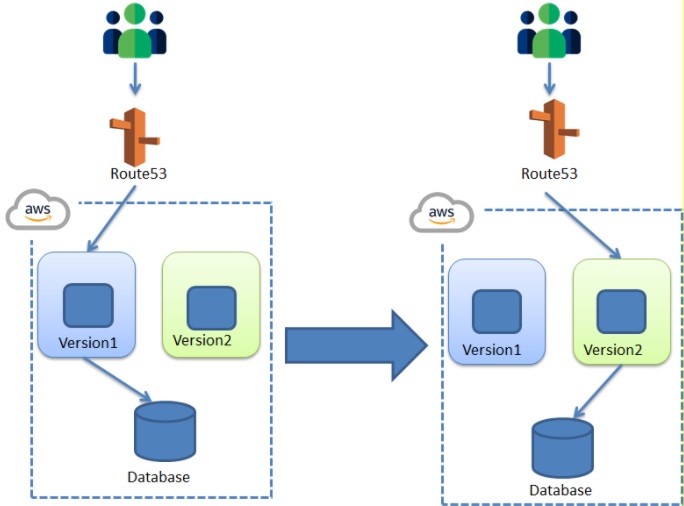
This is a continuous deployment strategy that is generally used to decrease downtime. This is used for transferring the traffic from one instance to another.
For Example, let us take a situation where we want to include a new version of code. Now we have to replace the old version with a new version of code. The old version is considered to be in a blue environment and the new version is considered as a green environment. we had made some changes to the existing old version which transformed into a new version with minimum changes.
Now to run the new version of the instance we need to transfer the traffic from the old instance to the new instance. That means we need to transfer the traffic from the blue environment to the green environment. The new version will be running on the green instance. Gradually the traffic is transferred to the green instance. The blue instance will be kept on idle and used for the rollback.
In Blue-Green deployment, the application is not deployed in the same environment. Instead, a new server or environment is created where the new version of the application is deployed.
Once the new version of the application is deployed in a separate environment, the traffic to the old version of the application is redirected to the new version of the application.
We follow the Blue-Green Deployment model, so that any problem which is encountered in the production environment for the new application if detected. The traffic can be immediately redirected to the previous Blue environment, with minimum or no impact on the business. Following diagram shows, Blue-Green Deployment.
Antipatterns in DevOps refer to common practices or behaviors that may seem like effective solutions but, in reality, hinder the success and effectiveness of DevOps initiatives. These antipatterns can lead to inefficiencies, communication breakdowns, and reduced collaboration between development and operations teams. Here are some notable DevOps antipatterns to be aware of:
1. Silos and Lack of Collaboration: Failing to break down organizational silos and promoting a lack of collaboration between development, operations, and other teams can lead to miscommunication, slower feedback loops, and decreased efficiency.
2. Tool Sprawl: Adopting too many tools and technologies without a clear strategy can lead to complexity and confusion, making it difficult to manage and integrate various components effectively.
3. Ignoring Security Aspects: Neglecting security practices and considering it as an afterthought can result in vulnerabilities and potential risks, compromising the entire DevOps pipeline.
4. Neglecting Cultural Change: Implementing DevOps is not just about adopting tools and processes; it requires a cultural shift. Neglecting the cultural aspect of DevOps can limit its effectiveness in breaking down barriers between teams.
5. Lack of Automation: Failing to automate manual processes and repetitive tasks can slow down the deployment process, reduce reliability, and increase the likelihood of human errors.
6. Inadequate Monitoring and Feedback Loops: Neglecting monitoring and failing to set up proper feedback loops can lead to a lack of insights into system performance, making it difficult to identify and resolve issues quickly.
7. Overemphasis on Speed Over Quality: Prioritizing speed at the expense of software quality can lead to frequent bugs, reduced customer satisfaction, and higher maintenance costs.
8. Inconsistent Environments: Inconsistent development, testing, and production environments can lead to issues in deployment and hinder collaboration between teams.
9. Lack of Continuous Integration (CI): Neglecting CI practices can result in integration issues, code conflicts, and longer development cycles.
10. Blaming Culture: A culture of blame and finger-pointing can undermine trust and hinder the ability to learn from mistakes, inhibiting the continuous improvement aspect of DevOps.
To avoid falling into these antipatterns, organizations should focus on building a strong DevOps culture, emphasizing collaboration, communication, and continuous improvement. Implementing automation, establishing clear processes, and fostering a blame-free environment can also help address DevOps antipatterns and drive successful DevOps transformations.
A pattern can be defined as an ideology on how to solve a problem. Now anti-pattern can be defined as a method that would help us to solve the problem now but it may result in damaging our system [i.e, it shows how not to approach a problem ].
Some of the anti-patterns we see in DevOps are:
First, if we want to approach a project that needs DevOps, we need to know a few concepts like :
Here’s what Shyam Verma, one of our DevOps learners had to say about our DevOps Training course:
CI/CD (Continuous Integration and Continuous Deployment) and DevOps are related concepts, but they are not the same thing.
CI/CD refers to the process of automating the building, testing, and deployment of software. The goal of CI/CD is to make it easier to release new software changes and bug fixes to users quickly and reliably.
DevOps, on the other hand, is a cultural and technical movement focused on improving collaboration and communication between development and operations teams. DevOps emphasizes the automation of processes and the use of technology to enable organizations to deliver software faster and more reliably.
In summary, CI/CD is a set of practices for software development, while DevOps is a cultural movement and set of practices aimed at improving collaboration and communication between development and operations teams to deliver software faster and more reliably.
Trunk-based development is a software development methodology that focuses on frequent, small code changes being integrated into the main development branch (trunk) as soon as they are ready, rather than longer development cycles with multiple branches. This approach aims to minimize branching and merging, promoting continuous integration and testing, and allowing for faster delivery of new features and bug fixes to users. The main principle behind trunk-based development is to keep the trunk in a stable and releasable state at all times, allowing developers to work efficiently and reducing the risk of conflicts and integration issues.
Continuous Integration (CI) and Continuous Deployment/Delivery (CD) are software development practices that aim to automate and improve the software development process. Some common CI/CD practices include:
By implementing these practices, organizations can speed up the development process, improve the quality of their software, and quickly respond to changes in the market or customer needs.
Q16. What is CBD in DevOps?
In the context of DevOps, CBD stands for “Continuous Business Delivery.” While not as commonly used as other terms in the DevOps domain, CBD refers to the integration of business processes and decision-making into the DevOps workflow.
The traditional DevOps approach primarily focuses on integrating development and operations teams to streamline software delivery and deployment processes. However, in modern DevOps practices, the scope is expanding to include other stakeholders, including business owners, product managers, and executives.
Continuous Business Delivery aims to ensure that the software development and deployment process aligns with the business objectives and requirements. It involves incorporating business-related considerations and feedback into the DevOps pipeline to deliver products and features that meet customer needs and drive business value.
Key aspects of CBD in DevOps include:
By embracing Continuous Business Delivery in DevOps, organizations can enhance their ability to deliver software products that are not only technically sound but also directly contribute to the success and growth of the business. It brings a holistic view of the software development process, considering both technical and business aspects, and fosters a culture of collaboration and shared ownership among all stakeholders involved in the software development lifecycle.
Now let’s move on to the Continuous Testing DevOps engineer interview questions answers.
I will advise you to follow the below mentioned explanation:
Continuous Testing is the process of executing automated tests as part of the software delivery pipeline to obtain immediate feedback on the business risks associated with in the latest build. In this way, each build is tested continuously, allowing Development teams to get fast feedback so that they can prevent those problems from progressing to the next stage of Software delivery life-cycle. This dramatically speeds up a developer’s workflow as there’s no need to manually rebuild the project and re-run all tests after making changes.
Automation testing or Test Automation is a process of automating the manual process to test the application/system under test. Automation testing involves use of separate testing tools which lets you create test scripts which can be executed repeatedly and doesn’t require any manual intervention.
I have listed down some advantages of automation testing. Include these in your answer and you can add your own experience of how Continuous Testing helped your previous company:
I have mentioned a generic flow below which you can refer to:
In DevOps, developers are required to commit all the changes made in the source code to a shared repository. Continuous Integration tools like Jenkins will pull the code from this shared repository every time a change is made in the code and deploy it for Continuous Testing that is done by tools like Selenium as shown in the below diagram.
In this way, any change in the code is continuously tested unlike the traditional approach.
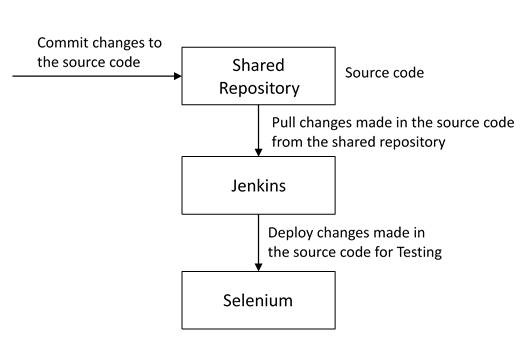
You can answer this question by saying, “Continuous Testing allows any change made in the code to be tested immediately. This avoids the problems created by having “big-bang” testing left to the end of the cycle such as release delays and quality issues. In this way, Continuous Testing facilitates more frequent and good quality releases.”
Key elements of Continuous Testing are:
Here mention the testing tool that you have worked with and accordingly frame your answer. I have mentioned an example below:
I have worked on Selenium to ensure high quality and more frequent releases.
Some advantages of Selenium are:
Selenium supports two types of testing:
Regression Testing: It is the act of retesting a product around an area where a bug was fixed.
Functional Testing: It refers to the testing of software features (functional points) individually.
Resilience testing is a subset of software testing that examines a system’s capacity to keep running and recover after being subjected to adversity. To test the system’s resilience, it must be put through a variety of stressors and failure conditions, such as heavy traffic, malfunctions, depleted resources, and a downed network. By validating that the system continues to function normally in the face of adversity, resilience testing helps guarantee a consistent and reliable service for users.
My suggestion is to start this answer by defining Selenium IDE. It is an integrated development environment for Selenium scripts. It is implemented as a Firefox extension, and allows you to record, edit, and debug tests. Selenium IDE includes the entire Selenium Core, allowing you to easily and quickly record and play back tests in the actual environment that they will run in.
Now include some advantages in your answer. With autocomplete support and the ability to move commands around quickly, Selenium IDE is the ideal environment for creating Selenium tests no matter what style of tests you prefer.
I have mentioned differences between Assert and Verify commands below:
The following syntax can be used to launch Browser:
WebDriver driver = new FirefoxDriver();
WebDriver driver = new ChromeDriver();
WebDriver driver = new InternetExplorerDriver();
For this answer, my suggestion would be to give a small definition of Selenium Grid. It can be used to execute same or different test scripts on multiple platforms and browsers concurrently to achieve distributed test execution. This allows testing under different environments and saving execution time remarkably.
Learn Automation testing and other DevOps concepts in live instructor-led online classes in our DevOps Certification course.
| Continuous Testing | Automation Testing |
| Continuous Testing is a process that involves executing all the automated test cases as a part of the software delivery pipeline | Automation testing is a process tool that involves testing the code repetitively without manual intervention. |
| This process mainly focuses on business risks. | This process mainly focuses on a bug-free environment. |
| It’s comparatively slow than automation testing | It’s comparatively faster than continuous testing. |
Now let’s check how much you know about DevOps Interview Question and answers onConfiguration Management.
The purpose of Configuration Management (CM) is to ensure the integrity of a product or system throughout its life-cycle by making the development or deployment process controllable and repeatable, therefore creating a higher quality product or system. The CM process allows orderly management of system information and system changes for purposes such as to:
Given below are few differences between Asset Management and Configuration Management:
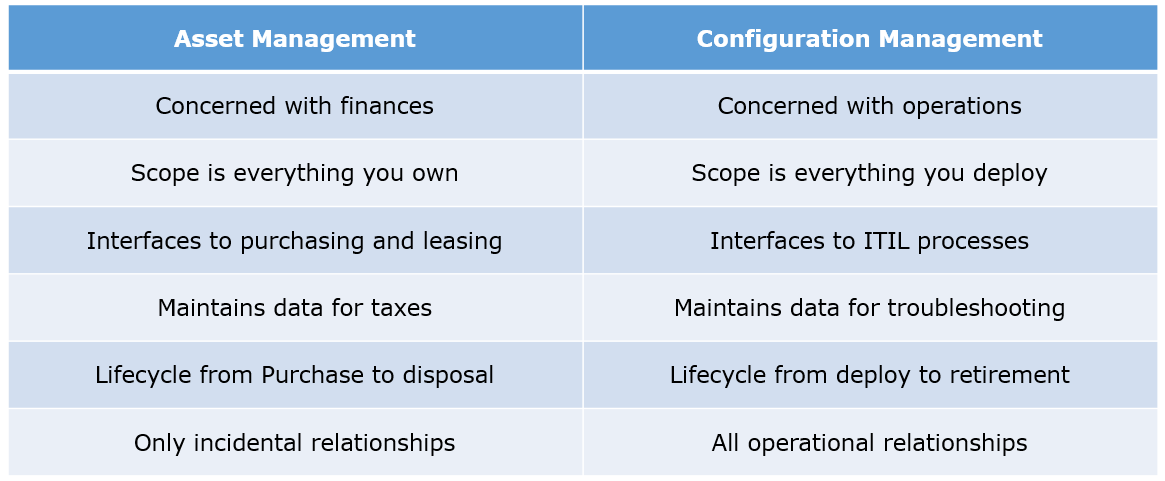
According to me, you should first explain Asset. It has a financial value along with a depreciation rate attached to it. IT assets are just a sub-set of it. Anything and everything that has a cost and the organization uses it for its asset value calculation and related benefits in tax calculation falls under Asset Management, and such item is called an asset.
Configuration Item on the other hand may or may not have financial values assigned to it. It will not have any depreciation linked to it. Thus, its life would not be dependent on its financial value but will depend on the time till that item becomes obsolete for the organization.
Now you can give an example that can showcase the similarity and differences between both:
1) Similarity:
Server – It is both an asset as well as a CI.
2) Difference:
Building – It is an asset but not a CI.
Document – It is a CI but not an asset
Infrastructure as Code (IAC) is a type of IT infrastructure that operations teams can use to automatically manage and provision through code, rather than using a manual process.
Companies for faster deployments treat infrastructure like software: as code that can be managed with the DevOps tools and processes. These tools let you make infrastructure changes more easily, rapidly, safely and reliably.
This depends on the organization’s need so mention few points on all those tools:
Puppet is the oldest and most mature CM tool. Puppet is a Ruby-based Configuration Management tool, but while it has some free features, much of what makes Puppet great is only available in the paid version. Organizations that don’t need a lot of extras will find Puppet useful, but those needing more customization will probably need to upgrade to the paid version.
Chef is written in Ruby, so it can be customized by those who know the language. It also includes free features, plus it can be upgraded from open source to enterprise-level if necessary. On top of that, it’s a very flexible product.
Ansible is a very secure option since it uses Secure Shell. It’s a simple tool to use, but it does offer a number of other services in addition to configuration management. It’s very easy to learn, so it’s perfect for those who don’t have a dedicated IT staff but still need a configuration management tool.
SaltStack is python based open source CM tool made for larger businesses, but its learning curve is fairly low.
I will advise you to first give a small definition of Puppet. It is a Configuration Management tool which is used to automate administration tasks.
Now you should describe its architecture and how Puppet manages its Agents. Puppet has a Master-Slave architecture in which the Slave has to first send a Certificate signing request to Master and Master has to sign that Certificate in order to establish a secure connection between Puppet Master and Puppet Slave as shown on the diagram below. Puppet Slave sends request to Puppet Master and Puppet Master then pushes configuration on Slave.
Refer the diagram below that explains the above description.

The easiest way is to enable auto-signing in puppet.conf.
Do mention that this is a security risk. If you still want to do this:
For this answer, I will suggest you to explain you past experience with Puppet. you can refer the below example:
I automated the configuration and deployment of Linux and Windows machines using Puppet. In addition to shortening the processing time from one week to 10 minutes, I used the roles and profiles pattern and documented the purpose of each module in README to ensure that others could update the module using Git. The modules I wrote are still being used, but they’ve been improved by my teammates and members of the community
Over here, you need to mention the tools and how you have used those tools to make Puppet more powerful. Below is one example for your reference:
Changes and requests are ticketed through Jira and we manage requests through an internal process. Then, we use Git and Puppet’s Code Manager app to manage Puppet code in accordance with best practices. Additionally, we run all of our Puppet changes through our continuous integration pipeline in Jenkins using the beaker testing framework.
It is a very important question so make sure you go in the correct flow. According to me, you should first define Manifests. Every node (or Puppet Agent) has got its configuration details in Puppet Master, written in the native Puppet language. These details are written in the language which Puppet can understand and are termed as Manifests. They are composed of Puppet code and their filenames use the .pp extension.
Now give an exampl. You can write a manifest in Puppet Master that creates a file and installs apache on all Puppet Agents (Slaves) connected to the Puppet Master.
For this answer, you can go with the below mentioned explanation:
A Puppet Module is a collection of Manifests and data (such as facts, files, and templates), and they have a specific directory structure. Modules are useful for organizing your Puppet code, because they allow you to split your code into multiple Manifests. It is considered best practice to use Modules to organize almost all of your Puppet Manifests.
Puppet programs are called Manifests which are composed of Puppet code and their file names use the .pp extension.
You are expected to answer what exactly Facter does in Puppet so according to me, you should say, “Facter gathers basic information (facts) about Puppet Agent such as hardware details, network settings, OS type and version, IP addresses, MAC addresses, SSH keys, and more. These facts are then made available in Puppet Master’s Manifests as variables.”
Begin this answer by defining Chef. It is a powerful automation platform that transforms infrastructure into code. Chef is a tool for which you write scripts that are used to automate processes. What processes? Pretty much anything related to IT.
Now you can explain the architecture of Chef, it consists of:
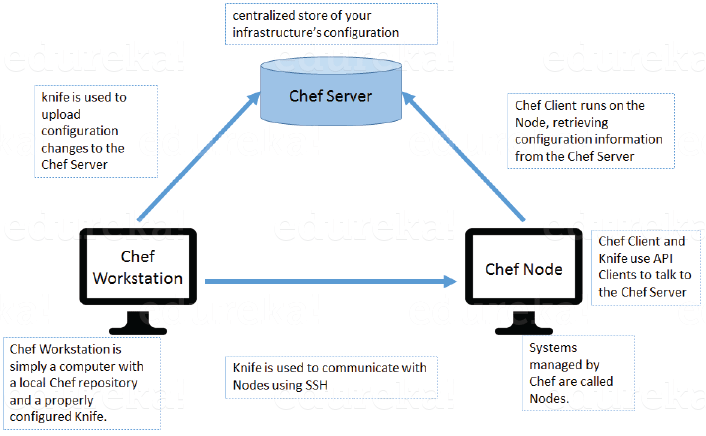
My suggestion is to first define Resource. A Resource represents a piece of infrastructure and its desired state, such as a package that should be installed, a service that should be running, or a file that should be generated.
You should explain about the functions of Resource for that include the following points:
For this answer, I will suggest you to use the above mentioned flow: first define Recipe. A Recipe is a collection of Resources that describes a particular configuration or policy. A Recipe describes everything that is required to configure part of a system.
After the definition, explain the functions of Recipes by including the following points:
The answer to this is pretty direct. You can simply say, “a Recipe is a collection of Resources, and primarily configures a software package or some piece of infrastructure. A Cookbook groups together Recipes and other information in a way that is more manageable than having just Recipes alone.”
My suggestion is to first give a direct answer: when you don’t specify a resource’s action, Chef applies the default action.
Now explain this with an example, the below resource:
file ‘C:UsersAdministratorchef-reposettings.ini’ do
content ‘greeting=hello world’
end
is same as the below resource:
file ‘C:UsersAdministratorchef-reposettings.ini’ do
action :create
content ‘greeting=hello world’
end
because: create is the file Resource’s default action.
Modules are considered to be the units of work in Ansible. Each module is mostly standalone and can be written in a standard scripting language such as Python, Perl, Ruby, bash, etc.. One of the guiding properties of modules is idempotency, which means that even if an operation is repeated multiple times e.g. upon recovery from an outage, it will always place the system into the same state.
Playbooks are Ansible’s configuration, deployment, and orchestration language. They can describe a policy you want your remote systems to enforce, or a set of steps in a general IT process. Playbooks are designed to be human-readable and are developed in a basic text language.
At a basic level, playbooks can be used to manage configurations of and deployments to remote machines.
Ansible by default gathers “facts” about the machines under management, and these facts can be accessed in Playbooks and in templates. To see a list of all of the facts that are available about a machine, you can run the “setup” module as an ad-hoc action:
Ansible -m setup hostname
This will print out a dictionary of all of the facts that are available for that particular host.
WebLogic Server 8.1 allows you to select the load order for applications. See the Application MBean Load Order attribute in Application. WebLogic Server deploys server-level resources (first JDBC and then JMS) before deploying applications. Applications are deployed in this order: connectors, then EJBs, then Web Applications. If the application is an EAR, the individual components are loaded in the order in which they are declared in the application.xml deployment descriptor.
Yes, you can use weblogic.Deployer to specify a component and target a server, using the following syntax:
java weblogic.Deployer -adminurl http://admin:7001 -name appname -targets server1,server2 -deploy jsps/*.jsp
The auto-deployment feature checks the applications folder every three seconds to determine whether there are any new applications or any changes to existing applications and then dynamically deploys these changes.
The auto-deployment feature is enabled for servers that run in development mode. To disable auto-deployment feature, use one of the following methods to place servers in production mode:
Set -external_stage using weblogic.Deployer if you want to stage the application yourself, and prefer to copy it to its target by your own means.
Ansible and Puppet are two of the most popular configuration management tools among DevOps engineers.
Generally, SSH is used for connecting two computers and helps to work on them remotely. SSH is mostly used by the operations team as the operations team will be dealing with managing tasks with which they will require the admin system remotely. The developers will also be using SSH but comparatively less than the operations team as most of the time they will be working in the local systems. As we know, the DevOps development team and operation team will collaborate and work together.SSH will be used when the operations team faces any problem and needs some assistance from the development team then SSH is used.
Memcached is a Free & open-source, high-performance, distributed memory object caching system.
This is generally used in the management of memory in dynamic web applications by caching the data in RAM. This helps to reduce the frequency of fetching from external sources. This also helps in speeding up the dynamic web applications by alleviating database load.
Conclusion: DevOps is a culture of collaboration between the Development team and operation team to work together to bring out an efficient and fast software product. So these are a few top DevOps interview questions that are covered in this blog. This blog will be helpful to prepare for a DevOps interview.
By the name, we can say it is a type of meeting which is conducted at the end of the project. In this meeting, all the teams come together and discuss the failures in the current project. Finally, they will conclude how to avoid them and what measures need to be taken in the future to avoid these failures.
In DevOps, CAMS stands for Culture, Automation, Measurement, and Sharing.
Q29. Differentiate between Functional testing and Non-Functional testing.
Functional testing is a type of testing that verifies if a system meets the specified functional requirements and works as intended. It tests the functionality of the software, including inputs, outputs, and processes.
Non-functional testing, on the other hand, is a type of testing that evaluates the non-functional aspects of a system, such as performance, security, reliability, scalability, and usability. It ensures that the software is not only functional, but also meets the performance, security, and other quality criteria required by the user.
In summary, functional testing focuses on the functionality of the software, while non-functional testing focuses on the quality criteria of the software.
Q30. Define black box testing and its techniques.
Black box testing is a method of software testing that examines the functionality of an application without looking at its internal structures or codes. The tester is only concerned with inputs and expected outputs and does not have any knowledge of the internal workings of the application. The techniques used in black box testing include:
Automated testing in DevOps refers to the use of tools and scripts to automatically run tests on applications, infrastructure, and services. It is integrated into the continuous delivery pipeline and helps to ensure that new code changes do not introduce bugs or negatively impact performance. The following is a basic overview of how automated testing works in the DevOps lifecycle:
The goal of automated testing in DevOps is to increase the speed and efficiency of the testing process while also reducing the risk of bugs being introduced into the production environment.
Let’s test your knowledge on DevOps Engineer Interview Questions Continuous Monitoring.
I will suggest you to go with the below mentioned flow:
Continuous Monitoring allows timely identification of problems or weaknesses and quick corrective action that helps reduce expenses of an organization. Continuous monitoring provides solution that addresses three operational disciplines known as:
You can answer this question by first mentioning that Nagios is one of the monitoring tools. It is used for Continuous monitoring of systems, applications, services, and business processes etc in a DevOps culture. In the event of a failure, Nagios can alert technical staff of the problem, allowing them to begin remediation processes before outages affect business processes, end-users, or customers. With Nagios, you don’t have to explain why an unseen infrastructure outage affect your organization’s bottom line.
Now once you have defined what is Nagios, you can mention the various things that you can achieve using Nagios.
By using Nagios you can:
This completes the answer to this question. Further details like advantages etc. can be added as per the direction where the discussion is headed.
I will advise you to follow the below explanation for this answer:
Nagios runs on a server, usually as a daemon or service. Nagios periodically runs plugins residing on the same server, they contact hosts or servers on your network or on the internet. One can view the status information using the web interface. You can also receive email or SMS notifications if something happens.
The Nagios daemon behaves like a scheduler that runs certain scripts at certain moments. It stores the results of those scripts and will run other scripts if these results change.
Now expect a few questions on Nagios components like Plugins, NRPE etc..
Begin this answer by defining Plugins. They are scripts (Perl scripts, Shell scripts, etc.) that can run from a command line to check the status of a host or service. Nagios uses the results from Plugins to determine the current status of hosts and services on your network.
Once you have defined Plugins, explain why we need Plugins. Nagios will execute a Plugin whenever there is a need to check the status of a host or service. Plugin will perform the check and then simply returns the result to Nagios. Nagios will process the results that it receives from the Plugin and take the necessary actions.
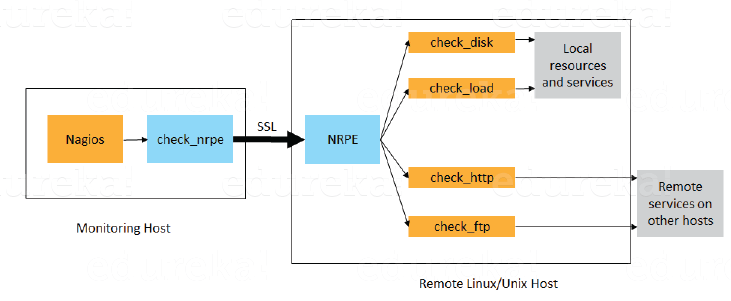
For this answer, give a brief definition of Plugins. The NRPE addon is designed to allow you to execute Nagios plugins on remote Linux/Unix machines. The main reason for doing this is to allow Nagios to monitor “local” resources (like CPU load, memory usage, etc.) on remote machines. Since these public resources are not usually exposed to external machines, an agent like NRPE must be installed on the remote Linux/Unix machines.
I will advise you to explain the NRPE architecture on the basis of diagram shown below. The NRPE addon consists of two pieces:
There is a SSL (Secure Socket Layer) connection between monitoring host and remote host as shown in the diagram below.
According to me, the answer should start by explaining Passive checks. They are initiated and performed by external applications/processes and the Passive check results are submitted to Nagios for processing.
Then explain the need for passive checks. They are useful for monitoring services that are Asynchronous in nature and cannot be monitored effectively by polling their status on a regularly scheduled basis. They can also be used for monitoring services that are Located behind a firewall and cannot be checked actively from the monitoring host.
Make sure that you stick to the question during your explanation so I will advise you to follow the below mentioned flow. Nagios check for external commands under the following conditions:
For this answer, first point out the basic difference Active and Passive checks. The major difference between Active and Passive checks is that Active checks are initiated and performed by Nagios, while passive checks are performed by external applications.
If your interviewer is looking unconvinced with the above explanation then you can also mention some key features of both Active and Passive checks:
Passive checks are useful for monitoring services that are:
The main features of Actives checks are as follows:
The interviewer will be expecting an answer related to the distributed architecture of Nagios. So, I suggest that you answer it in the below mentioned format:
With Nagios you can monitor your whole enterprise by using a distributed monitoring scheme in which local slave instances of Nagios perform monitoring tasks and report the results back to a single master. You manage all configuration, notification, and reporting from the master, while the slaves do all the work. This design takes advantage of Nagios’s ability to utilize passive checks i.e. external applications or processes that send results back to Nagios. In a distributed configuration, these external applications are other instances of Nagios.
First mention what this main configuration file contains and its function. The main configuration file contains a number of directives that affect how the Nagios daemon operates. This config file is read by both the Nagios daemon and the CGIs (It specifies the location of your main configuration file).
Now you can tell where it is present and how it is created. A sample main configuration file is created in the base directory of the Nagios distribution when you run the configure script. The default name of the main configuration file is nagios.cfg. It is usually placed in the etc/ subdirectory of you Nagios installation (i.e. /usr/local/nagios/etc/).
I will advise you to first explain Flapping first. Flapping occurs when a service or host changes state too frequently, this causes lot of problem and recovery notifications.
Once you have defined Flapping, explain how Nagios detects Flapping. Whenever Nagios checks the status of a host or service, it will check to see if it has started or stopped flapping. Nagios follows the below given procedure to do that:
A host or service is determined to have started flapping when its percent state change first exceeds a high flapping threshold. A host or service is determined to have stopped flapping when its percent state goes below a low flapping threshold.
According to me the proper format for this answer should be:
First name the variables and then a small explanation of each of these variables:
Then give a brief explanation for each of these variables. Name is a placeholder that is used by other objects. Use defines the “parent” object whose properties should be used. Register can have a value of 0 (indicating its only a template) and 1 (an actual object). The register value is never inherited.
Answer to this question is pretty direct. I will answer this by saying, “One of the features of Nagios is object configuration format in that you can create object definitions that inherit properties from other object definitions and hence the name. This simplifies and clarifies relationships between various components.”
I will advise you to first give a small introduction on State Stalking. It is used for logging purposes. When Stalking is enabled for a particular host or service, Nagios will watch that host or service very carefully and log any changes it sees in the output of check results.
Depending on the discussion between you and interviewer you can also add, “It can be very helpful in later analysis of the log files. Under normal circumstances, the result of a host or service check is only logged if the host or service has changed state since it was last checked.”
Want to get trained in monitoring tools like Nagios? Want to certified as a DevOps Engineer? Make sure you check out our DevOps Engineer Certification Course Masters Program.
Q15. Justify the statement — Nagios is Object-Oriented?
Nagios is considered object-oriented because it uses a modular design, where elements in the system are represented as objects with specific properties and behaviors. These objects can interact with each other to produce a unified monitoring system. This design philosophy allows for easier maintenance and scalability, as well as allowing for more efficient data management.
A Nagios backend refers to the component of Nagios that stores and manages the data collected by the monitoring process, such as monitoring results, configuration information, and event history. The backend is usually implemented as a database or a data store, and is accessed by the Nagios frontend to display the monitoring data. The backend is a crucial component of Nagios, as it enables the persistence of monitoring data and enables historical analysis of the monitored systems.
Let’s see how much you know about containers and VMs.
My suggestion is to explain the need for containerization first, containers are used to provide consistent computing environment from a developer’s laptop to a test environment, from a staging environment into production.
Now give a definition of containers, a container consists of an entire runtime environment: an application, plus all its dependencies, libraries and other binaries, and configuration files needed to run it, bundled into one package. Containerizing the application platform and its dependencies removes the differences in OS distributions and underlying infrastructure.
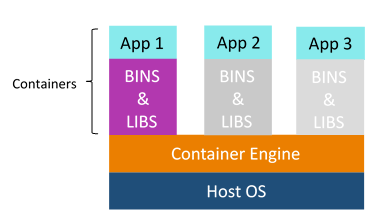
Below are the advantages of containerization over virtualization:
Given below are some differences. Make sure you include these differences in your answer:
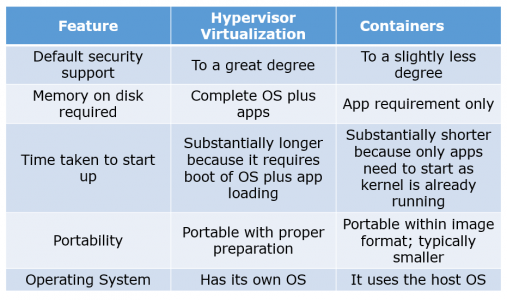
I suggest that you go with the below mentioned flow:
Docker image is the source of Docker container. In other words, Docker images are used to create containers. Images are created with the build command, and they’ll produce a container when started with run. Images are stored in a Docker registry such as registry.hub.docker.com because they can become quite large, images are designed to be composed of layers of other images, allowing a minimal amount of data to be sent when transferring images over the network.
Tip: Be aware of Dockerhub in order to answer questions on pre-available images.
This is a very important question so just make sure you don’t deviate from the topic. I advise you to follow the below mentioned format:
Docker containers include the application and all of its dependencies but share the kernel with other containers, running as isolated processes in user space on the host operating system. Docker containers are not tied to any specific infrastructure: they run on any computer, on any infrastructure, and in any cloud.
Now explain how to create a Docker container, Docker containers can be created by either creating a Docker image and then running it or you can use Docker images that are present on the Dockerhub.
Docker containers are basically runtime instances of Docker images.
Answer to this question is pretty direct. Docker hub is a cloud-based registry service which allows you to link to code repositories, build your images and test them, stores manually pushed images, and links to Docker cloud so you can deploy images to your hosts. It provides a centralized resource for container image discovery, distribution and change management, user and team collaboration, and workflow automation throughout the development pipeline.
According to me, below points should be there in your answer:
Docker containers are easy to deploy in a cloud. It can get more applications running on the same hardware than other technologies, it makes it easy for developers to quickly create, ready-to-run containerized applications and it makes managing and deploying applications much easier. You can even share containers with your applications.
If you have some more points to add you can do that but make sure the above the above explanation is there in your answer.
You should start this answer by explaining Docker Swarn. It is native clustering for Docker which turns a pool of Docker hosts into a single, virtual Docker host. Docker Swarm serves the standard Docker API, any tool that already communicates with a Docker daemon can use Swarm to transparently scale to multiple hosts.
I will also suggest you to include some supported tools:
This answer according to me should begin by explaining the use of Dockerfile. Docker can build images automatically by reading the instructions from a Dockerfile.
Now I suggest you to give a small definition of Dockerfle. A Dockerfile is a text document that contains all the commands a user could call on the command line to assemble an image. Using docker build users can create an automated build that executes several command-line instructions in succession.
Now expect a few questions to test your experience with Docker.
You can use json instead of yaml for your compose file, to use json file with compose, specify the filename to use for eg:
docker-compose -f docker-compose.json up
Explain how you have used Docker to help rapid deployment. Explain how you have scripted Docker and used Docker with other tools like Puppet, Chef or Jenkins. If you have no past practical experience in Docker and have past experience with other tools in similar space, be honest and explain the same. In this case, it makes sense if you can compare other tools to Docker in terms of functionality.
I will suggest you to give a direct answer to this. We can use Docker image to create Docker container by using the below command:
docker run -t -i <image name> <command name>
This command will create and start container.
You should also add, If you want to check the list of all running container with status on a host use the below command:
docker ps -a
In order to stop the Docker container you can use the below command:
docker stop <container ID>
Now to restart the Docker container you can use:
docker restart <container ID>
Large web deployments like Google and Twitter, and platform providers such as Heroku and dotCloud all run on container technology, at a scale of hundreds of thousands or even millions of containers running in parallel.
I will start this answer by saying Docker runs on only Linux and Cloud platforms and then I will mention the below vendors of Linux:
Cloud:
Note that Docker does not run on Windows or Mac.
You can answer this by saying, no I won’t lose my data when the Docker container exits. Any data that your application writes to disk gets preserved in its container until you explicitly delete the container. The file system for the container persists even after the container halts.
DevOps Pipeline can be defined as a set of tools and processes in which both the development team and operations team work together. In DevOps automation, CI/CD plays an important role. Now if we look into the flow of DevOps, First when we complete continuous integration. Then the next step towards continuous delivery is triggered. After the continuous delivery, the next step of continuous deployment will be triggered. The connection of all these functions can be defined as a pipeline.
You can check the version of the Docker Client by running the following command in your terminal:
docker version
And you can check the version of the Docker Server (also known as the Docker Engine) by running the following command:
docker info
The output of the above command will include the Docker Engine version.
You can use the “man” or “–help” command to get information on a specific command in most Unix-like systems. For example, if you’re trying to recall the syntax for the “grep” command, you can type “man grep” or “grep –help” in the terminal. This will display the manual page for the command, which includes usage examples and options.
| Continuous Deployment | Continuous Delivery |
| Deployment to production is automated | Deployment to production is manual |
| App deployment to production can be done, as soon as the code passes all the tests. There is no release day, in continuous Deployment | App deployment to production is done manually on a certain day, called “release day” |
And, that’s it!
I hope these DevOps interview questions help you crack your interview. If you’re searching for a demanding and rewarding career. Whether you’ve worked in DevOps or are new to the field, the Post Graduate Program in DevOps is what you need to learn how to succeed. From the basic to the most advanced techniques, we cover everything.
All the best for your interview!
Got a question for us? Please mention it in the comments section and we will get back to you.
Related Posts:-






























 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







nice information….
thank you ……….
+N Chandrakanth, thanks for checking out our blog and for sharing feedback! We’re glad you found the information useful. Here are a few more DevOps blogs that you might like: https://www.edureka.co/blog?s=devops. Cheers!
One of the most informative and brilliant blog’s I have come across for DevOps. It has adequate information with crisp details. Brilliant Stuff!!!!!!!!!!
Hey Vinod, thanks for your feedback! :) We’re glad we could help. Do subscribe to our blog to stay updated on upcoming DevOps posts. Cheers!
Hi good information,
Ma i know the main differences between docker and chef?
why we need to use chef other than docker?
this is the question iam facing from interviewer. could you please elaborate the same
please reply me
Chef: config management tool
Docker: Container tool. It packs the piece of code into work units, which later can be deployed to test or production environment with greater ease.
Hey Prasad, thanks for checking out our blog. Here’s the explanation:
Chef is an automation platform to transform your infrastructure into code. It is generally called Configuration Management Software. You can define the state with different parameters as your config files, s/w, tools, access types and resource types etc. Chef allows you to write scripts to quickly provision servers (including instances of Vagrant and/or Docker).
Dockerfile also partially takes on configuration management tools in the way of providing “infrastructure as code” into the table
Docker is not a full-fledged Virtual Machine, but rather a container. Docker enables you to run instances of services/servers in a specific virtual environment. A good example of this would be running a Docker container with Ruby on Rails on Ubuntu Linux.
Hope this answers your query. Good luck!
great work !! Keep it up :)
Thanks for the wonderful feedback, Sandeep! Do check out our DevOps tutorials too: https://www.youtube.com/playlist?list=PL9ooVrP1hQOE5ZDJJsnEXZ2upwK7aTYiX. We thought you might find them useful. Cheers!
Really Great work done.
Hey Sairam, thanks for checking out our blog and for sharing feedback! Do subscribe to our blog to stay posted on upcoming DevOps blogs. Cheers!
Excellent article.
Hey Vijay, thanks for checking out our blog. We’re glad you found it useful. Here’s another blog that we thought you might like: https://www.edureka.co/blog/devops-engineer-career-path-your-guide-to-bagging-top-devops-jobs. Cheers!
Awesome info. Everything is covered but I don’t see much scripting questions. Will there be any scripting questions in the interview? such as white board questions on scripting on Ruby or python?
Hey Mahesh, thanks for checking out the blog. We have noted your feedback and passed it on to the relevant team. We may come up with an update to the questions in the future. Do subscribe to our blog to stay posted. Cheers!
please help me on my prob
chef-client
[2016-09-29T16:47:16-07:00] INFO: Forking chef instance to converge…
[2016-09-29T16:47:16-07:00] WARN:
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
SSL validation of HTTPS requests is disabled. HTTPS connections are still
encrypted, but chef is not able to detect forged replies or man in the middle
attacks.
To fix this issue add an entry like this to your configuration file:
“`
# Verify all HTTPS connections (recommended)
ssl_verify_mode :verify_peer
# OR, Verify only connections to chef-server
verify_api_cert true
“`
To check your SSL configuration, or troubleshoot errors, you can use the
`knife ssl check` command like so:
“`
knife ssl check -c /etc/chef/client.rb
“`
* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *
Starting Chef Client, version 11.18.12
[2016-09-29T16:47:17-07:00] INFO: *** Chef 11.18.12 ***
[2016-09-29T16:47:17-07:00] INFO: Chef-client pid: 25737
[2016-09-29T16:48:12-07:00] INFO: HTTP Request Returned 401 Unauthorized: error
================================================================================
Chef encountered an error attempting to load the node data for “node.com”
================================================================================
Authentication Error:
———————
Failed to authenticate to the chef server (http 401).
Server Response:
—————-
Invalid signature for user or client ‘node.com’
Relevant Config Settings:
————————-
chef_server_url “https://192.168.113.143”
node_name “node.com”
client_key “/etc/chef/client.pem”
If these settings are correct, your client_key may be invalid, or
you may have a chef user with the same client name as this node.
[2016-09-29T16:48:12-07:00] FATAL: Stacktrace dumped to /var/chef/cache/chef-stacktrace.out
Chef Client failed. 0 resources updated in 55.215306981 seconds
[2016-09-29T16:48:12-07:00] ERROR: 401 “Unauthorized”
[2016-09-29T16:48:12-07:00] FATAL: Chef::Exceptions::ChildConvergeError: Chef run process exited unsuccessfully (exit code 1)
[root@node ~]# knife bootstrap 192.168.113.143
WARNING: No knife configuration file found
Connecting to 192.168.113.143
ERROR: Errno::ENOENT: No such file or directory – /etc/chef/validation.pem
Hey Ravindra, thanks for checking out the blog. With regard to the error you’re getting, either the key is wrong or the validator username is wrong.
Try running the ssl fetch command on your chef client:
knife ssl fetch -c /etc/chef/client.rb
Also, try including -N nodeName parameter during initial knife bootstrap operation.
Hope this helps. Cheers!
After reading this blog I finally understand the prerequisite for Devops
Looking forward for training in Configuration management tools like Chef and Continuous Integration Jenkins and also Monitoring Nagios.
Hey Raj, thanks for checking out the blog! We’re glad you found it useful. You may like this DevOps career opportunities blog too: https://www.edureka.co/blog/devops-engineer-career-path-your-guide-to-bagging-top-devops-jobs. We will be coming up with blogs on DevOps tools and DevOps lifecycle very soon. Do subscribe to our blog to stay posted. Cheers!
very useful questions and answers thank you..
Simply Superb !!!
Thanks for your wonderful feedback! Do check out this DevOps career opportunities blog too: https://www.edureka.co/blog/devops-engineer-career-path-your-guide-to-bagging-top-devops-jobs. We thought you may find it useful. Cheers!