
Linux Administration Certification Training C ...
- 15k Enrolled Learners
- Weekend/Weekday
- Live Class
(5800)





 Copy Link!
Copy Link!
Did you know that more than 90% of the World’s Fastest Computers use Linux? No doubt why! Linux is fast, powerful, and a techies’ favorite. If you are looking to become a Linux Administrator, then this is the right place for you to prepare for the interview. In this article, I will be discussing some of the most common and important Linux Interview Questions and their Answers.
Interested in Linux Administration? Check out the Live Linux Certification Course online.
This Linux Interview Questions blog is divided into two parts: Part A-Theoretical Questions and Part B-Scenario Based Questions. Let’s get started!
In this part of Linux Interview Questions, we will discuss the most common theoretical and concept based questions.
Linux is an open-source and Unix-like operating system kernel that serves as the core component of many operating systems known as Linux distributions, or distros. Linux is known for its stability, security, and versatility, and it is widely used across various devices and platforms.
2. Who invented Linux? Explain the history of Linux.
On August 25, 1991, a Finnish computer science student named Linus Torvalds first released it. In fact, Linux is the result of the combined efforts of a large number of programmers from all over the world. Linux’s origins lie in the open-source and free software movements of the early 1990s.
The success of Linux demonstrates the power of collaboration and the impact of the open-source philosophy on the world of technology. It serves as a prominent example of how a freely shared and community-driven project can become a fundamental part of modern computing.
The main differences between Linux and UNIX are as follows:
| Parameter | Linux | Unix |
| Price | Both free distributions and paid distributions are available. | Different levels of UNIX have a different cost structure |
| Target User | Everyone (Home user, Developer, etc.) | Mainly Internet Server, Workstations, Mainframes. |
| File System Support | Ext2, Ext3, Ext4, Jfs, ReiserFS, Xfs, Btrfs, FAT, FAT32, NTFS. | jfs, gpfs, hfs, hfs+, ufs, xfs, zfs,vxfs. |
| GUI | KDE and Gnome | Common Desktop Environment |
| Viruses listed | 60-100 | 80-120 |
| Bug Fix Speed | Faster because Linux is Community driven | Slow |
| Portability | Yes | No |
| Examples | Ubuntu, Fedora, Red Hat, Kali Linux, Debian, Archlinux, Android, etc. | OS X, Solaris, All Linux |
Linux vs. Unix – Linux Interview Questions
Linux kernel refers to the low-level system software. It is used to manage resources and provide an interface for user interaction.
Yes, it is legal to edit Linux Kernel. Linux is released under the General Public License (General Public License). Any project released under GPL can be modified and edited by the end users.
The BASH (Bourne Again SHell) command-line interpreter and scripting language runs on Linux and macOS, among other Unix-based platforms. It has advanced scripting capabilities and a user-friendly command line interface, with support for things like variables, control structures, and tab completion. On Unix and Linux systems, BASH is commonly used for a variety of automation, administration, and interactive purposes.
6. What are two types of Linux User Mode?
In Linux, there are two primary user modes, known as User Mode and Kernel Mode.
The transition between User Mode and Kernel Mode occurs through system calls. When a user-level process needs to perform a privileged operation or access hardware resources, it requests the kernel’s assistance through a system call. The kernel then switches to Kernel Mode to fulfill the request, and after completing the operation, it returns control to User Mode.
The separation of User Mode and Kernel Mode helps ensure system stability, security, and protection, as the kernel controls and manages critical operations while user-level processes operate in a more restricted environment.
LILO stands for LInux LOader. LILO is a Linux Boot Loader that loads Linux Operating System into the main memory to begin execution. Most of the computers come with boot loaders for certain versions of Windows or Mac OS. So, when you want to use Linux OS, you need to install a special boot loader for it. LILO is one such boot loader.
When the computer is started, BIOS conducts some initial tests and transfers control to the Master Boot Record. From here, LILO loads the Linux OS and starts it.
The advantage of using LILO is that it allows fast boot of Linux OS.
The basic components of Linux are:
9. What is the Linux Shell? What types of Shells are there in Linux?
The Linux Shell, also known as a command-line shell or simply a shell, is a program that provides a command-line interface for interacting with the Linux operating system. It acts as an intermediary between the user and the operating system, allowing users to execute commands, run programs, and perform various tasks through the terminal.
The shell interprets user input (linux commands) and converts them into system calls that the Linux kernel can understand. It also provides features like command history, tab completion, scripting capabilities, and environment variable management.
There are several types of shells available in Linux, including:
Each shell has its unique features, syntax, and advantages, making them suitable for different user preferences and specific tasks. The choice of shell depends on individual needs and familiarity with their respective features. Bash remains the default shell for most Linux distributions due to its widespread usage, extensive support, and compatibility with scripts written for the Bourne shell.
The most common Shells used in Linux are
Swap Space is the additional spaced used by Linux that temporarily holds concurrently running programs when the RAM does not have enough space to hold the programs. When you run a program, it resides on the RAM so that the processor can fetch data quickly. Suppose you are running more programs than the RAM can hold, then these running programs are stored in the Swap Space. The processor will now look for data in the RAM and the Swap Space.
Swap Space is used as an extension of RAM by Linux.
There are 3 main differences between BASH and DOS:
| Sl. no. | BASH | DOS |
| 1. | Commands are case-sensitive. | Commands are not case-sensitive. |
| 2. | ‘/’ (forward slash) is used as a directory separator. ” (backslash) is used as an escape character. | ‘/’ (forward slash) is used as command argument delimiter. ” (backslash) is used as a directory separator. |
| 3. | Follows naming convention: 8 characters for file name postfixed with 3 characters for the extension. | No naming convention. |
Bash vs Dos – Linux Interview Questions
You can use any of the following commands:
free -mvmstattophtopThere are 3 kinds of permission in Linux:
You can change the permission of a file or a directory using the chmodcommand. There are two modes of using the chmod command:
The general syntax to change permission using Symbolic mode is as follows:
$ chmod <target>(+/-/=)<permission> <filename>
where <permissions> can be r: read; w: write; x: execute.
<target> can be u : user; g: group; o: other; a: all
'+' is used for adding permission
'-' is used for removing permission
'=' is used for setting the permission
For example, if you want to set the permission such that the user can read, write, and execute it and members of your group can read and execute it, and others may only read it.
Then the command for this will be:
$ chmod u=rwx,g=rx,o=r filename
The general syntax to change permission using Absolute mode is as follows:
$ chmod <permission> filename
The Absolute mode follows octal representation. The leftmost digit is for the user, the middle digit is for the user group and the rightmost digit is for all.
Below is the table that explains the meaning of the digits that can be used and their effect.
| 0 | No permission | – – – |
| 1 | Execute permission | – – x |
| 2 | Write permission | – w – |
| 3 | Execute and write permission: 1 (execute) + 2 (write) = 3 | – wx |
| 4 | Read permission | r – – |
| 5 | Read and execute permission: 4 (read) + 1 (execute) = 5 | r – x |
| 6 | Read and write permission: 4 (read) + 2 (write) = 6 | rw – |
| 7 | All permissions: 4 (read) + 2 (write) + 1 (execute) = 7 | rwx |
For example, if you want to set the permission such that the user can read, write, and execute it and members of your group can read and execute it, and others may only read it.
Then the command for this will be:
$ chmod 754 filename
inode is the unique name given by the operating system to each file. Similarly, process id is the unique id given to each process.
LVM, which stands for Logical Volume Manager, is a storage management technology used in Linux and other Unix-like operating systems. It provides a flexible and advanced method for managing storage devices, allowing administrators to create, resize, and manage logical volumes that span multiple physical disks.
Key concepts and features of LVM include:
LVM is not a strict requirement for Linux, and the operating system can be installed and used without LVM. However, LVM provides significant benefits in terms of storage flexibility and management, making it highly recommended for servers and systems with dynamic storage requirements. LVM is commonly used in enterprise environments and in scenarios where administrators need to manage storage efficiently and without disrupting existing data.
Using LVM can simplify tasks such as adding storage space, resizing volumes, and managing storage resources across multiple disks. It provides a higher level of abstraction for storage management, allowing administrators to work with logical volumes independently of the physical hardware.
Overall, while LVM is not an absolute necessity, it is a valuable tool for storage management in Linux and offers advantages for those seeking flexible and dynamic storage solutions.
There are 5 main Directory Commands in Linux:
pwd: Displays the path of the present working directory.
Syntax: $ pwd
ls: Lists all the files and directories in the present working directory.
Syntax: $ ls
cd: Used to change the present working directory.
Syntax: $ cd <path to new directory>
mkdir: Creates a new directory
Syntax: $ mkdir <name (and path if required) of new directory>
rmdir: Deletes a directory
Syntax: $ rmdir <name (and path if required) of directory>
Virtual Desktop is a feature that allows users to use the desktop beyond the physical limits of the screen. Basically, Virtual Desktop creates a virtual screen to expand the limitation of the normal screen.
There are two ways Virtual Desktop can be implemented:
In the case of Switching Desktops, you can create discrete virtual desktops to run programs. Here, each virtual desktop will behave as an individual desktop and the programs running on each of these desktops is accessible only to the users who are using that particular desktop.
Oversized Desktops do not offer a discrete virtual desktop but it allows the user to pan and scroll around the desktop that is larger in size than the physical screen.
There are 3 modes of vi editor:
A daemon is a computer program that runs as a background process to provide functions that might not be available in the base Operating System. Daemons are usually used to run services in the background without directly being in control of interactive users. The purpose of Daemons are to handle periodic requests and then forward the requests to appropriate programs for execution.
The process states are as follows:
Grep stands for Global Regular Expression Print. The grep command is used to search for a text in a file by pattern matching based on regular expression.
Syntax: grep [options] pattern [files]
Example:
$ grep -c "linux" interview.txt
This command will print the count of the word “linux” in the “interview.txt” file.
The System Calls to manage the process are:
And the System Calls used to get Process ID are:
The ls command is used to list the files in a specified directory. The general syntax is:
$ ls <options> <directory>
For example, if you want to list all the files in the Example directory, then the command will be as follows:
$ ls Example/
There are different options that can be used with the ls command. These options give additional information about the file/ folder. For example:
| -l | lists long format (shows the permissions of the file) |
| -a | lists all files including hidden files |
| -i | lists files with their inode number |
| -s | lists files with their size |
| -S | lists files with their size and sorts the list by file size |
| -t | sorts the listed files by time and date |
The redirection operator is used to redirect the output of a particular command as an input to another command or file.
There are two ways of using this:
‘>’ overwrites the existing content of the file or creates a new file.
‘>>’ appends the new content to the end of the file or creates a new file.
Suppose the content of the file is as follows:

Now when you use the ‘>’ redirection operator, the contents of the file are overwritten.

and when you use ‘>>’, the contents are appended:

The tar command is used to extract or create an archived file.
Suppose you want to extract all the files from the archive named sample.tar.gz, then the command will be:
$ tar -xvzf sample.tar.gz
Suppose you want to create an archive of all the files stored in the path /home/linux/, then the command will be:
$ tar -cvzf filename.tar.gz
where c: create archive, x: extract, v: verbose, f: file
A Latch is a temporary storage device controlled by timing signal which can either store 0 or 1. A Latch has two stable states (high-output or 1, and low-output or 0) and is mainly used to store state information. A Latch can store one bit of data as long as it is powered on.
A Microprocessor is a device that executes instructions. It is a single-chip device that fetches the instruction from the memory, decodes it and executes it. A Microprocessor can carry out 3 basic functions:
Regular Expressions are used to search for data having a particular pattern. Some of the commands used with Regular Patterns are: tr, sed, vi and grep.
Some of the common symbols used in Regular Expressions are:
| . | Match any character |
| ^ | Match the beginning of the String |
| $ | Match the end of the String |
| * | Match zero or more characters |
| Represents special characters | |
| ? | Match exactly one character |
Suppose the content of a file is as follows:

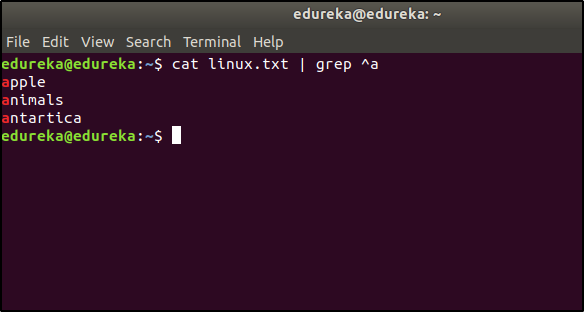
If you want to list the entries that start with the character ‘a’, then the command would be:
$ cat linux.txt | grep ^a
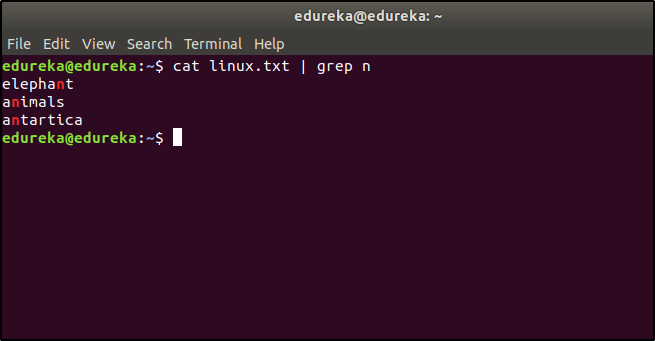
If you want to list the entries that start has the character ‘n’, then the command would be:
$ cat linux.txt | grep n
The minimum number of partitions required is 2.
One partition is used as the local file system where all the files are stored. This includes files of the OS, files of applications and services, and files of the user. And the other partition is used as Swap Space which acts as an extended memory for RAM.
The “/proc” file system is a virtual file system in Linux that provides real-time information about running processes and kernel configurations. It is a dynamic interface, representing data in memory rather than physical files on disk. It is valuable for monitoring, debugging, and accessing system information.
For example, to view information about the current CPU utilization, you can read the “/proc/stat” file. To see the memory usage of a specific process with PID 12345, you can check the “/proc/12345/status” file.
Overall, the “/proc” file system is a powerful and dynamic interface that provides valuable system information and insights for system administrators, developers, and monitoring tools in Linux-based systems.
The daemon that controls the print spooling process in Linux is called the “CUPS” daemon. CUPS stands for Common Unix Printing System. It is a modular printing system that provides a standard interface for printing on Unix-like operating systems, including Linux.
The CUPS daemon, typically named `cupsd`, manages the print queues, processes print jobs, and handles communication with printers. It allows users to send print jobs to printers connected to the system or network and provides features like print job scheduling, printer sharing, and support for various print protocols.
CUPS has become the standard printing system in many Linux distributions and is widely used for managing print services in both desktop and server environments. It simplifies the process of printing and provides a flexible and efficient way to handle printing tasks on Linux systems.
“Sun Java Desktop System,” or “Java Desktop System” for short, was the name of the Linux release that Sun Microsystems made. Sun Microsystems created an operating system that was based on Linux. Oracle Corporation later bought Sun Microsystems.
Sun Java Desktop System was designed to give business users an easy-to-use desktop environment. It came with a selection of software programs, including the GNOME desktop environment, the Mozilla web browser, the Evolution email client, StarOffice (later replaced by OpenOffice.org), and other productivity tools.
The Sun Java Desktop System’s main goal was to provide an alternative to standard operating systems like Windows and give business users a familiar and efficient desktop environment. However, not many people used it, and Oracle stopped producing it after purchasing Sun Microsystems in 2010.
Please keep in mind that even though Sun Java Desktop System was built on Linux, it was a program made by Sun Microsystems and not a different Linux distribution like Ubuntu, Fedora, or CentOS.
Sun Microsystems designed the Unix-based operating system called “Solaris.” It was known for its scalability and advanced features.
The size of the swap partition in a Linux system typically depends on various factors, including the system’s RAM size, intended use, and specific requirements. However, a common rule of thumb for setting the swap partition size is to make it equal to or slightly larger than the system’s RAM.
Here are some general recommendations for swap partition size:
It’s important to note that modern systems with ample RAM may not heavily rely on swap space unless they handle memory-intensive tasks or run specific applications that require significant memory usage.
Additionally, if the system has a solid-state drive (SSD), some users opt to reduce the swap partition size or avoid using a dedicated swap partition altogether to minimize unnecessary wear on the SSD. In such cases, a swap file (a file used as swap space) may be used instead of a dedicated swap partition.
Ultimately, the ideal swap partition size depends on the system’s RAM, workload, and the administrator’s preferences. It’s essential to strike a balance between having enough swap space for emergency situations and avoiding excessive use of swap, which can impact performance on systems with plenty of RAM.
A Zombie Process is a terminated process that still has an entry in the process table. It occurs when a process finishes execution, but its termination status is not yet retrieved by its parent process. Zombie processes consume minimal resources and are automatically cleaned up by the operating system once the parent process reaps them.
The main difference between cron and anacron lies in how they schedule and run tasks on a Unix-like operating system, such as Linux.
– `cron` is a time-based job scheduler in Unix-like systems. It allows users to schedule recurring tasks or jobs at specific intervals using a configuration file called the “crontab.”
– Tasks scheduled with `cron` run at specified times or intervals (e.g., every hour, daily, weekly) and require the system to be continuously running. If the system is powered off during the scheduled time, the task is not executed until the next scheduled interval.
– `cron` is suitable for tasks that need to run regularly and predictably on a system that is always powered on, such as system maintenance, log rotation, and backups.
– `anacron` is also a time-based job scheduler like `cron`, but it is designed to handle tasks that are meant to be executed on systems that may not be continuously running, such as laptops or desktop computers that are regularly powered off or in sleep mode.
– Tasks scheduled with `anacron` have more flexibility in execution time and do not depend on specific intervals. Instead, they have a defined delay before execution, typically measured in days. When the system is powered on, `anacron` checks if the specified delay has passed since the last execution, and if so, it runs the task.
– Unlike `cron`, `anacron` ensures that tasks are executed regardless of whether the system was powered off during the scheduled time. It is designed to prevent tasks from being missed due to system downtime.
Load average in Linux represents the average number of processes in the run queue over different time periods: 1-minute, 5-minute, and 15-minute intervals. It indicates system activity and resource utilization, helping identify potential bottlenecks and capacity planning.
A Shell Script is a script or program written in a coding language called “shell,” which is used as a command-line processor in Unix-like operating systems like Linux. It’s a list of orders put in a plain text file that the shell can run to automate jobs and do other things. Users can mix multiple shell commands and control structures like loops and conditionals to make scripts that are more complicated and powerful. They are often used to automate jobs that are done over and over again, to handle systems, files, and do other things that require interaction with the operating system.
Shell scripts are flexible and make it easy to work with the command-line interface of a machine. They are small, easy to write, and used by system managers, coders, and power users on Unix-based systems to improve workflows and get things done quickly.
CLI and GUI are two different types of user interfaces used to interact with a computer system:
| CLI (Command-Line Interface) | GUI (Graphical User Interface) | |
| Definition | Text-based interface with commands | Visual interface with windows, icons, etc. |
| Interaction | Users type commands into a terminal | Users interact with mouse or touch input |
| Output | Text-based output | Visual feedback and graphical elements |
| Flexibility | Highly flexible and powerful | Less flexible, but user-friendly |
| Learning Curve | Requires learning commands and syntax | Generally easier to learn and use |
| Automation | Suitable for automation through scripts | Limited automation capabilities |
| Target Audience | Experienced users and system administrators | Casual users and non-technical individuals |
| Examples | Windows Command Prompt, Unix/Linux Terminal | Windows Desktop, macOS graphical interface, Linux desktop environments (e.g., GNOME, KDE) |
CLI and GUI are both ways to talk to a computer system, but they are different. CLI uses text-based orders and replies, while GUI uses graphical features to show the user what to do. Each system has its own benefits and is used in different situations depending on what the user wants and how hard the job is. CLI is often preferred by experienced users and system administrators because it is fast and can be automated. On the other hand, because it is simple to use and attractive, GUI is popular with casual users.
The `/etc/resolv.conf` and `/etc/hosts` files are used in Unix-like operating systems, including Linux, to handle network-related configurations and name resolution.
– The `/etc/resolv.conf` file is used to configure the Domain Name System (DNS) resolver on the system. DNS is a system that translates human-readable domain names (e.g., www.example.com) into IP addresses (e.g., 192.168.1.1) that computers can understand.
– The `resolv.conf` file contains information about DNS name servers that the system should use to resolve domain names. It specifies the IP addresses of one or more DNS servers to be queried for name resolution.
– When a user or application on the system tries to access a website or connect to a remote server using a domain name, the system consults the `resolv.conf` file to find the DNS servers to use for name resolution.
– The `/etc/hosts` file is a simple text file that maps IP addresses to hostnames. It serves as a local DNS lookup table for the system, allowing users to define hostname-to-IP address mappings without relying on external DNS servers.
– Entries in the `hosts` file are typically used to override or supplement the DNS resolution provided by external DNS servers.
– When a user or application on the system tries to access a domain name, the system first checks the `hosts` file for a corresponding entry. If a match is found, the system uses the IP address specified in the `hosts` file, bypassing the need to query external DNS servers.
Both files play critical roles in name resolution and network configuration. The `/etc/resolv.conf` file is primarily used for configuring the system’s DNS resolver settings, while the `/etc/hosts` file is used for local hostname-to-IP address mappings, providing a way to customize name resolution behavior on the local system.
NIC teaming, also known as network interface card teaming or bonding, is a technique used to combine multiple network interfaces into a single logical interface. This aggregation offers several advantages for improving network performance, redundancy, and load balancing. Some of the key advantages of using NIC teaming are:
Overall, NIC teaming enhances network performance, reliability, and availability, making it a valuable technique for organizations that require high-bandwidth, fault-tolerant, and resilient network configurations. It is commonly used in server environments, data centers, and other critical network infrastructure setups.
Network bonding, also known as NIC bonding or link aggregation, is a technique that combines multiple network interfaces into a single logical interface. This virtual interface offers increased bandwidth, load balancing, and redundancy for improved network performance and reliability. By distributing network traffic across multiple interfaces and providing failover capabilities, network bonding enhances overall network efficiency and ensures continuous connectivity even if one interface fails. It is commonly used in server environments and data centers to optimize network utilization and achieve high availability.
In Linux, network bonding supports several bonding modes, each designed to offer different functionalities and benefits. The bonding modes available in Linux are:
Each bonding mode serves different purposes and is suitable for specific network scenarios. The choice of bonding mode depends on the network requirements, the capabilities of the network equipment, and the desired balance between performance, load distribution, and redundancy. Administrators can select the most appropriate bonding mode based on their network environment and application needs.
Here are the default ports used for some common network services:
It’s important to note that while these are the default port numbers, some services and applications may be configured to use different ports based on administrator preferences or specific network configurations. Additionally, for services running over SSL/TLS, different port numbers may be used for the secure versions (e.g., SMTPS over port 465, HTTPS over port 443).
SSH, which stands for Secure Shell, is a cryptographic network protocol used for secure remote access to computers and servers over a network. It provides a secure and encrypted communication channel between a client (your local machine) and a server (remote machine) to enable secure data exchange and remote command execution.
To connect to a remote server via SSH, follow these steps:
“`
ssh username@remote_server_ip
“`
Replace `username` with your actual username on the remote server and `remote_server_ip` with the IP address or domain name of the remote server.
Keep in mind that SSH is a powerful tool that allows remote access to a server. Ensure that you have proper authorization to access the remote server, and always use strong passwords or SSH key pairs to enhance security. Additionally, if you are connecting to a remote server on a public network, consider using a VPN or other security measures to further protect your communication.
Soft links (symbolic links) and hard links are two types of links used in Unix-like operating systems, including Linux. They both allow multiple directory entries (filenames) to point to the same underlying file, but they have some key differences:
| Soft Link (Symbolic Link) | Hard Link | |
| Type of Link | A reference to the target file/directory | Additional directory entry to the same file |
| Data | Does not contain the actual data | Shares the same data with the original file |
| Impact on Target | Deleting the link does not affect target | Deleting any link does not affect data or other links |
| Cross File Systems | Can span across different file systems | Limited to the same file system |
| Supported for | Works for both files and directories | Only supported for files, not directories |
In short, soft links are references to the target file or directory, but hard links are new directory entries going directly to the same physical data. Hard links are confined to files and cannot traverse file system borders, but soft links can bridge file systems and work for files and directories. Furthermore, deleting a soft link leaves the target file or directory untouched, whereas hard links keep the data accessible as long as at least one hard link exists.
Apologies for the repetition. The three standard streams in Linux are:
Interviewers will ask scenario based questions along with theoretical questions to check how much hands-on knowledge you have. In this part of Linux Interview Questions, we will discuss such questions.
You can use the cp command to copy a file in Linux. The general syntax is:
$ cp <source> <destination>
Suppose you want to copy a file named questions.txt from the directory /new/linux to /linux/interview, then the command will be:
$ cp questions.txt /new/linux /linux/interview
Every process has a unique process id. To terminate the process, we first need to find the process id. The ps command will list all the running processes along with the process id. And then we use the kill command to terminate the process.
The command for listing down all the processes:
$ ps
Suppose the process id of the process you want to terminate is 3849, then you will have to terminate it like this:
$ kill 3849
There is no specific command to rename a file in Linux. But you use the copy or move command to rename the file.
Using the Move command
$ mv <oldname> <newname>
Using the Copy command
$ cp <oldname> <newname>
And then delete the old file.
$ rm <oldname>
You can use the redirection operator (>) to do this.
Syntax: $ (command) > (filename)
By running the following command:
$ mount -l
You can use the locate command to find the path to the file.
Suppose you want to find the locations of a file name sample.txt, then your command would be:
$ locate sample.txt
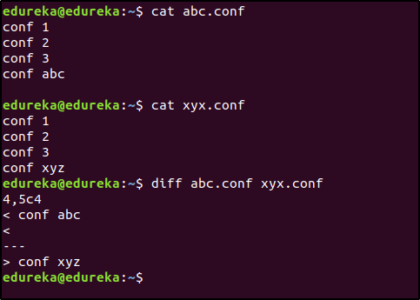
You can use the diff command for this:
$ diff abc.conf xyz.conf
for i in *linux*; do rm $i; done
The touch command can be used to create a text file without opening it. The touch command will create an empty file. The syntax is as follows:
$ touch <filename>
Suppose you want to create a file named sample.txt, then the command would be:
$ touch sample.txt
There are two commands that can be used to delete a directory in Linux.
$ rmdir <directory name>
$ rm -rf <directory name>
Note: The command rm -rf should be used carefully because it will delete all the data without any warnings.
There are two commands to schedule tasks in Linux: cron and at.
The cron command is used to repeatedly schedule a task at a specific time. The tasks are stored in a cron file and then executed using the cron command. The cron command reads the string from this file and schedules the task. The syntax for the string to enter in the cron file is as follows:
<minute> <hour> <day> <month> <weekday> <command>
Suppose you want to run a command at 4 pm every Sunday, then the string would be:
0 16 * * 0 <command>
The at command is used to schedule a task only once at the specified time.
Suppose you want to shut down the system at 6 pm today, then the command for this would be:
$ echo "shutdown now" | at -m 18:00
The .z extension means that the file has been compressed. To look at the contents of the compressed file, you can use the zcat command. Example:
$ zcat sample.z
Follow these steps to copy files to a Floppy Disk safely:
If you don’t unmount the floppy disk, then the data might become corrupted.
Open the terminal and run:
$ echo $SHELL
This will print the name of the Shell being used.
SSH can be used for this. The Syntax is as follows:
ssh <username>@<ip address>
Suppose you want to login into a system with IP address 192.168.5.5 as a user “mike”, then the command would be:
$ ssh mike@192.168.5.5
$ vim -R <filename>
$ vim +/<employee id to be searched> <filename>
$ vim +<line number> <filename>
This can be done using the sort command.
$ sort sample.txt
The export command is used to set and reload the environment variables. For example, if you want to set the Java path, then the command would be:
$ export JAVA_HOME = /home/user/Java/bin
$ service <servicename> status
$ service --status-all
To start:
$ service <servicename> start
To stop:
$ service <servicename> start
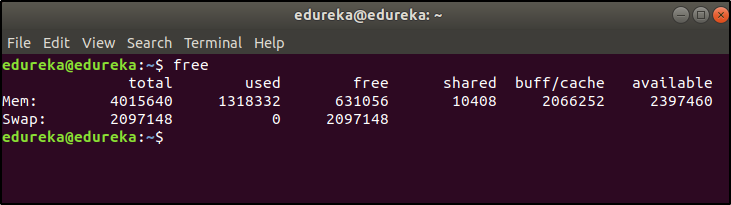
This command is used to display the free, used, swap memory available in the system.
Typical free command output. The output is displayed in bytes.
$ free
I hope these Linux Interview Questions will help you perform well in your interview. And I wish you all the best!
Got a question for us? Please post it on Edureka Community and we will get back to you.

















 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP

rest all commands are very useful for interview
thank you !
l love this Q&A really very nice it is..,
Thank you, great Q&A for the interview. I’ve found a mistake where the command to stop a service is actually to start, just a note:
To stop:
$ service start———->should be “stop”
Thanks.