







Kubernetes has been the buzzword in today’s market and is the best orchestration tool. It attracts many experienced professionals who want to advance their careers by a notch. Multinational companies such as Huwaei, Pokemon, eBay, Yahoo Japan, SAP, Open AI, and Sound Cloud use Kubernetes in their day-to-day activities. But there is a lack of Kubernetes Certified professionals in the market. I believe you already know these facts, which have made you land on this Kubernetes Interview Questions article, which will help you know the top questions asked in interviews. For further details, refer to the Kubernetes Certification Course.
Top Kubernetes Interview Questions
- How is Kubernetes different from Docker Swarm?
- What is Kubernetes?
- How is Kubernetes related to Docker?
- What is the difference between deploying applications on hosts and containers?
- What is Container Orchestration?
- What is the need for Container Orchestration?
- What are the features of Kubernetes?
- How does Kubernetes simplify containerized Deployment?
- What do you know about clusters in Kubernetes?
- What is Google Container Engine?
In this blog on Kubernetes Interview Questions, I will be discussing the top Kubernetes related questions asked in your interviews. So, for your better understanding I have divided this blog into the following 4 sections:
- Kubernetes Basic Interview Questions
- Architecture-Based Kubernetes Interview Questions
- Scenario-Based Kubernetes Interview Questions
- Multiple Choice Kubernetes Interview Questions
Kubernetes Full Course in 7 Hours | Kubernetes Tutorial | Kubernetes Training | Edureka

This Edureka Kubernetes Full Course video will help you understand and learn the fundamentals of Kubernetes. This Kubernetes Tutorial is ideal for both beginners as well as professionals who want to master the fundamentals of Kubernetes.
Basic Kubernetes Interview Questions
This section of questions will consist of all those basic questions that you need to know related to the working of Kubernetes.
Q1. How is Kubernetes different from Docker Swarm?
| Features | Kubernetes | Docker Swarm |
| Installation & Cluster Config | Setup is very complicated, but once installed cluster is robust. | Installation is very simple, but the cluster is not robust. |
| GUI | GUI is the Kubernetes Dashboard. | There is no GUI. |
| Scalability | Highly scalable and scales fast. | Highly scalable and scales 5x faster than Kubernetes. |
| Auto-scaling | Kubernetes can do auto-scaling. | Docker swarm cannot do auto-scaling. |
| Load Balancing | Manual intervention needed for load balancing traffic between different containers and pods. | Docker swarm does auto load balancing of traffic between containers in the cluster. |
| Rolling Updates & Rollbacks | Can deploy rolling updates and does automatic rollbacks. | Can deploy rolling updates, but not automatic rollback. |
| DATA Volumes | Can share storage volumes only with the other containers in the same pod. | Can share storage volumes with any other container. |
| Logging & Monitoring | In-built tools for logging and monitoring. | 3rd party tools like ELK stack should be used for logging and monitoring. |
Q2. What is Kubernetes?
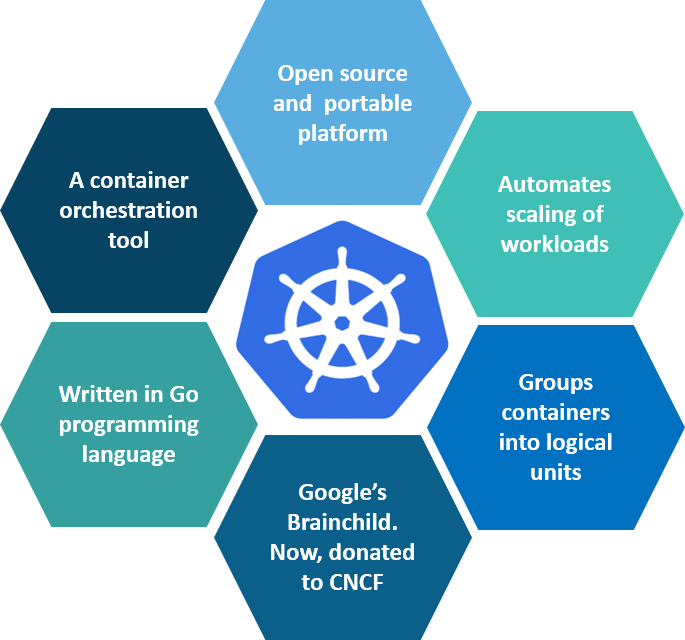

Fig 1: What is Kubernetes – Kubernetes Interview Questions
Kubernetes is an open-source container management tool that holds the responsibilities of container deployment, scaling & descaling of containers & load balancing. Being Google’s brainchild, it offers excellent community and works brilliantly with all the cloud providers. So, we can say that Kubernetes is not a containerization platform, but it is a multi-container management solution.
Q3. How is Kubernetes related to Docker?
It’s a known fact that Docker provides the lifecycle management of containers and a Docker image builds the runtime containers. But, since these individual containers have to communicate, Kubernetes is used. So, Docker builds the containers and these containers communicate with each other via Kubernetes. So, containers running on multiple hosts can be manually linked and orchestrated using Kubernetes.
Q4. What is the difference between deploying applications on hosts and containers?


Fig 2: Deploying Applications On Host vs Containers – Kubernetes Interview Questions
Refer to the above diagram. The left side architecture represents deploying applications on hosts. So, this kind of architecture will have an operating system and then the operating system will have a kernel that will have various libraries installed on the operating system needed for the application. So, in this kind of framework you can have n number of applications and all the applications will share the libraries present in that operating system whereas while deploying applications in containers the architecture is a little different.
This kind of architecture will have a kernel and that is the only thing that’s going to be the only thing common between all the applications. So, if there’s a particular application that needs Java then that particular application we’ll get access to Java and if there’s another application that needs Python then only that particular application will have access to Python.
The individual blocks that you can see on the right side of the diagram are basically containerized and these are isolated from other applications. So, the applications have the necessary libraries and binaries isolated from the rest of the system, and cannot be encroached by any other application.
Q5. What is Container Orchestration?
Consider a scenario where you have 5-6 microservices for an application. Now, these microservices are put in individual containers, but won’t be able to communicate without container orchestration. So, as orchestration means the amalgamation of all instruments playing together in harmony in music, similarly container orchestration means all the services in individual containers working together to fulfill the needs of a single server.
Q6. What is the need for Container Orchestration?
Consider you have 5-6 microservices for a single application performing various tasks, and all these microservices are put inside containers. Now, to make sure that these containers communicate with each other we need container orchestration.


Fig 3: Challenges Without Container Orchestration – Kubernetes Interview Questions
As you can see in the above diagram, there were also many challenges that came into place without the use of container orchestration. So, to overcome these challenges the container orchestration came into place.
Q7. What are the features of Kubernetes?
The features of Kubernetes, are as follows:


Fig 4: Features Of Kubernetes – Kubernetes Interview Questions
Q8. How does Kubernetes simplify containerized Deployment?
As a typical application would have a cluster of containers running across multiple hosts, all these containers would need to talk to each other. So, to do this you need something big that would load balance, scale & monitor the containers. Since Kubernetes is cloud-agnostic and can run on any public/private providers it must be your choice simplify containerized deployment.
Q9. What do you know about clusters in Kubernetes?
The fundamental behind Kubernetes is that we can enforce the desired state management, by which I mean that we can feed the cluster services of a specific configuration, and it will be up to the cluster services to go out and run that configuration in the infrastructure.


Fig 5: Representation Of Kubernetes Cluster – Kubernetes Interview Questions
So, as you can see in the above diagram, the deployment file will have all the configurations required to be fed into the cluster services. Now, the deployment file will be fed to the API and then it will be up to the cluster services to figure out how to schedule these pods in the environment and make sure that the right number of pods are running.
So, the API which sits in front of services, the worker nodes & the Kubelet process that the nodes run, all together make up the Kubernetes Cluster.
Q11. How to do maintenance activity on the K8 node?
Performing maintenance activities on a Kubernetes (K8s) node requires careful planning and execution to minimize disruption to running applications and ensure the overall health and stability of the cluster. Here are the general steps to perform maintenance on a Kubernetes node:
- **Drain the Node**: Before performing maintenance, you should drain the node to gracefully evict all the running pods from the node. The Kubernetes control plane will schedule the evicted pods to other healthy nodes in the cluster. Use the following command to drain the node:
“`
kubectl drain <node_name> –ignore-daemonsets
“`
Replace `<node_name>` with the name of the node you want to drain.
- **Mark the Node as Unschedulable**: Prevent new pods from being scheduled on the node during maintenance:
“`
kubectl cordon <node_name>
“`
- **Perform Maintenance Tasks**: Perform any required maintenance tasks on the node, such as OS upgrades, kernel updates, hardware replacements, etc.
- **Verify Node Status**: After the maintenance is completed, verify that the node is back online and functioning correctly.
- **Uncordon the Node**: Allow the node to accept new pods again:
“`
kubectl uncordon <node_name>
“`
- **Validate Pod Status**: Check the status of the pods that were running on the node before draining to ensure they have been successfully rescheduled to other nodes.
- **Rollout Updates (if applicable)**: If you have made any changes that require pod updates (e.g., container image updates), trigger a controlled rollout of the affected pods to the updated version.
- **Monitor Cluster Health**: Keep an eye on the overall health of the cluster after maintenance. Monitor the logs and metrics to ensure that all components and nodes are functioning as expected.
It’s crucial to plan maintenance windows during low-traffic periods or periods of reduced load to minimize the impact on running applications. For critical production environments, consider using Kubernetes features like PodDisruptionBudgets and readiness probes to ensure high availability during maintenance activities.
Always document your maintenance activities and follow best practices recommended by the Kubernetes community to maintain a stable and reliable cluster.
Q12. How do we control the resource usage of POD?
Controlling the resource usage of a Pod in Kubernetes is essential to ensure fair allocation of resources and prevent individual Pods from consuming excessive CPU and memory, which could negatively impact other Pods and the overall cluster performance. Kubernetes provides several mechanisms to control the resource usage of Pods:
- **Resource Requests and Limits**: Kubernetes allows you to set resource requests and limits for CPU and memory on a per-container basis within a Pod.
– Resource Requests: It specifies the minimum amount of CPU and memory required for a container to run. Kubernetes will use this information for scheduling and determining the amount of resources allocated to a Pod.
– Resource Limits: It specifies the maximum amount of CPU and memory that a container can consume. Kubernetes enforces these limits to prevent a single container from using more resources than specified, which helps in avoiding resource contention.
Here’s an example of setting resource requests and limits in a Pod’s container specification:
“`yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
– name: my-container
image: my-image
resources:
requests:
cpu: “0.5”
memory: “512Mi”
limits:
cpu: “1”
memory: “1Gi”
“`2. **Resource Quotas**: Kubernetes allows you to define Resource Quotas at the namespace level to limit the total amount of CPU and memory that can be consumed by all Pods within the namespace. Resource Quotas help prevent resource hogging and ensure a fair distribution of resources among different applications.
- **Horizontal Pod Autoscaler (HPA)**: HPA automatically adjusts the number of replicas of a Pod based on CPU utilization or custom metrics. It can scale up or down the number of replicas to maintain a target CPU utilization, helping to optimize resource usage dynamically.
- **Vertical Pod Autoscaler (VPA)**: VPA automatically adjusts the resource requests and limits of Pods based on their actual resource usage. It can resize the resource requests and limits to optimize resource allocation based on real-time usage patterns.
- **Quality of Service (QoS) Classes**: Kubernetes assigns QoS classes to Pods based on their resource requirements and usage. There are three classes: Guaranteed, Burstable, and BestEffort. The QoS classes help prioritize resource allocation and eviction decisions during resource contention.
By using these mechanisms, you can effectively control the resource usage of Pods in your Kubernetes cluster, ensuring efficient resource allocation, high availability, and optimal performance for all applications running in the cluster.
Q13. What are the various K8 services running on nodes and describe the role of each service?
In a Kubernetes (K8s) cluster, several essential services run on nodes to ensure proper cluster management, networking, and communication between components. Here are some of the key services and their roles:
- **kubelet**: The kubelet is an agent that runs on each node and is responsible for managing the containers running on that node. It communicates with the Kubernetes control plane and ensures that the containers specified in Pod manifests are running and healthy.
- **kube-proxy**: The kube-proxy is responsible for network proxying and load balancing for services running in the cluster. It enables communication between Pods and services and maintains network rules to forward traffic to the appropriate destinations.
- **container runtime**: The container runtime is the software responsible for pulling container images and running containers on the node. Kubernetes supports various container runtimes, such as Docker, containerd, and others.
- **kube-dns/coredns**: The kube-dns or CoreDNS service provides DNS resolution within the cluster. It allows Pods to discover and communicate with each other using DNS names instead of direct IP addresses.
- **kubelet-certificate-controller**: This service ensures that each node has the necessary TLS certificates required for secure communication with the control plane.
- **kubelet-eviction-manager**: The kubelet-eviction-manager monitors the resource usage of the node and triggers Pod eviction when there is a lack of resources, helping to maintain node stability and prevent node resource exhaustion.
- **kube-proxy (IPVS mode)**: In clusters running with IPVS (IP Virtual Server) mode, kube-proxy uses IPVS to handle the load balancing of services more efficiently.
- **metrics-server**: The metrics-server collects resource usage metrics (CPU, memory, etc.) from nodes and Pods and provides them to Kubernetes Horizontal Pod Autoscaler (HPA) and other components for scaling decisions.
- **node-problem-detector**: The node-problem-detector detects and reports node-level issues, such as kernel panics or unresponsive nodes, to the Kubernetes control plane for further actions.
- **kube-reserved and kube-system-reserved cgroups**: These are control groups that reserve CPU and memory resources for the kubelet and critical system components to ensure their stability and proper functioning.
These services, running on every node, play a crucial role in maintaining the health, networking, and performance of the Kubernetes cluster. They ensure seamless communication, resource management, and container orchestration, providing the foundation for deploying and managing containerized applications effectively in the Kubernetes environment.
Q14. What is PDB (Pod Disruption Budget)?
A Pod Disruption Budget (PDB) is a Kubernetes resource that allows you to set policies on how many Pods of a particular ReplicaSet or Deployment can be simultaneously unavailable during voluntary disruptions. Voluntary disruptions can occur during planned maintenance, scaling events, or other administrative actions.
The main purpose of a Pod Disruption Budget is to ensure high availability and reliability of applications running in a Kubernetes cluster while allowing for necessary maintenance and updates. By setting a PDB, you define the maximum tolerable disruption to a group of Pods, ensuring that a minimum number of replicas remain available and operational at all times.
A typical use case for PDB is during rolling updates or scaling events. When you update a deployment or scale it up or down, Kubernetes will try to ensure that the disruption does not exceed the defined PDB. This prevents scenarios where all instances of an application are taken down simultaneously, leading to service outages or degraded performance.
Here’s how a Pod Disruption Budget is defined in a Kubernetes manifest:
“`yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: example-pdb
spec:
selector:
matchLabels:
app: example-app
maxUnavailable: 1
“`
In this example, we create a Pod Disruption Budget named “example-pdb” for Pods labeled with `app: example-app`. The `maxUnavailable` parameter is set to 1, meaning that only one Pod can be unavailable at any time due to voluntary disruptions.
It’s important to note that a PDB does not prevent involuntary disruptions caused by node failures or other unforeseen issues. Instead, it focuses on controlling voluntary disruptions to maintain application availability during planned events. PDBs are particularly useful for applications that require a certain level of redundancy or have strict availability requirements.
Q15. What’s the init container and when it can be used?
An init container is a special type of container in Kubernetes that runs and completes its tasks before the main containers in a Pod start running. Init containers are used to perform setup, initialization, or configuration tasks required by the main application containers before they can start processing requests or performing their primary functions.
Here are some key points about init containers:
- **Sequential Execution**: Init containers run one after another, and each init container must successfully complete before the next one starts. This allows for a sequential setup of required resources or configurations.
- **Temporary Nature**: Init containers are temporary and are not part of the main application’s ongoing lifecycle. Once their tasks are completed, they terminate, and the main containers start.
- **Different Image**: Init containers can use a different container image than the main application containers. This allows for separate tools or configurations to be used for initialization tasks.
Use Cases for Init Containers:
- **Data Initialization**: Init containers can be used to fetch or generate initial data required by the main application containers. For example, an init container might fetch static configuration files or set up a database schema before the main application starts.
- **Dependency Handling**: When an application has dependencies on external services, an init container can be used to check and ensure that those services are available before the main application attempts to use them.
- **Database Schema Migration**: In scenarios where the application requires a specific database schema or migration, an init container can handle database schema setup or migration tasks before the main application connects to the database.
- **Certificate or Secret Injection**: Init containers can fetch secrets or SSL certificates from external sources and make them available to the main application containers securely.
Here’s an example of a Pod definition with an init container:
“`yaml
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
– name: main-container
image: my-app-image
# Main application container specification
initContainers:
– name: init-container
image: busybox
command: [‘sh’, ‘-c’, ‘echo “Performing initialization…” && sleep 10’]
# Init container specification
“`
In this example, the Pod contains an init container named “init-container” with a simple command to echo a message and sleep for 10 seconds. The main application container is named “main-container” and is specified below the init container. When the Pod starts, the init container will run and complete its task before the main application container starts.
Using init containers can help ensure that the required setup and configuration tasks are completed successfully before the main application starts, improving the reliability and stability of the overall application deployment.
Q16. What is the role of Load Balance in Kubernetes?
The role of Load Balancing in Kubernetes is to distribute incoming network traffic across multiple instances of a service or a set of Pods that are part of a Kubernetes Deployment or ReplicaSet. Load balancing ensures that each instance or Pod receives a fair share of requests, optimizing resource utilization and providing high availability for applications.
Here’s how load balancing works in Kubernetes:
- Service: In Kubernetes, a Service is an abstraction that defines a logical set of Pods and a policy for accessing them. A Service acts as a stable endpoint for other applications to access the Pods running your application.
- Load Balancer: When a Service is created, Kubernetes can automatically provision a load balancer (external or internal, depending on the cloud provider and configuration) to distribute incoming traffic across the Pods associated with the Service.
- Traffic Distribution: The load balancer continuously monitors the health and availability of the Pods associated with the Service. It uses different algorithms, such as round-robin, least connections, or IP hash, to evenly distribute incoming requests to the available Pods. This ensures that each Pod gets its fair share of traffic, preventing any single Pod from being overwhelmed.
- High Availability: Load balancing also provides high availability. If a Pod becomes unhealthy or unresponsive, the load balancer automatically routes traffic to the remaining healthy Pods, ensuring that the application remains accessible even if individual Pods fail.
- Scaling and Rolling Updates: Load balancing plays a critical role in scaling and rolling updates. When new Pods are added due to scaling or updates, the load balancer automatically starts routing traffic to these new Pods, gradually replacing the older ones. This allows for seamless scaling and updates with minimal or no disruption to the application.
- Service Discovery: Load balancing facilitates service discovery within the cluster. Clients do not need to know the exact locations or IP addresses of individual Pods; they can simply access the Service, and the load balancer routes their requests to the appropriate Pod.
Overall, load balancing in Kubernetes ensures that applications are efficiently distributed across the available Pods, that they remain highly available, and that traffic is managed effectively as the cluster scales or undergoes updates. This enhances the overall performance, reliability, and scalability of applications running in a Kubernetes cluster.
Q17. What are the various things that can be done to increase Kubernetes security?
Increasing Kubernetes security is crucial to protect your cluster, applications, and sensitive data from potential threats and unauthorized access. Here are several essential practices and measures to enhance Kubernetes security:
- Use RBAC (Role-Based Access Control): Implement RBAC to control and restrict access to different resources within the cluster. Assign roles and permissions based on the principle of least privilege, ensuring that users and applications have only the necessary access rights.
- Enable Network Policies: Use Network Policies to control network traffic between Pods within the cluster. Network Policies help enforce communication rules, limiting the attack surface and preventing unauthorized access between Pods.
- Secure API Server: Ensure that the Kubernetes API server is properly secured. Use TLS certificates for communication, disable insecure ports, and enable audit logging to monitor API server activity.
- Image Security: Scan container images for vulnerabilities and use trusted sources for images. Implement container image signing and verification to ensure image integrity.
- Pod Security Policies: Utilize Pod Security Policies to enforce security standards and best practices for Pod specifications. Pod Security Policies can prevent the creation of Pods that do not meet security requirements.
- Secure Secrets Management: Use Kubernetes Secrets to store sensitive information securely. Avoid exposing sensitive data directly in Pod specifications or YAML files.
- Regularly Update and Patch: Keep all components of the Kubernetes cluster, including nodes, control plane, and add-ons, up to date with the latest security patches and updates.
- Secure etcd: Ensure that the etcd data store used by the Kubernetes control plane is secure. Configure TLS encryption for etcd communication and consider enabling role-based access control for etcd.
- Limit External Access: Minimize external access to the Kubernetes API server and use a VPN or private network for secure access.
- Implement Pod Security Context: Set appropriate security context for Pods to control their privileges and capabilities. Avoid running containers with excessive permissions.
- Monitoring and Logging: Implement robust monitoring and logging solutions to detect and respond to security incidents. Monitor cluster activity, audit logs, and network traffic for suspicious behavior.
- Secure Network Communication: Use TLS for secure communication between components in the cluster. Enable mutual TLS authentication for enhanced security.
- Limit Host OS Access: Restrict direct access to the host OS from within containers, as it can pose security risks.
- Regular Security Audits: Conduct regular security audits and vulnerability assessments of your Kubernetes cluster and applications.
- Training and Education: Educate your team about Kubernetes security best practices and conduct security training regularly.
By following these security measures and best practices, you can significantly enhance the security of your Kubernetes cluster, reducing the risk of potential threats and ensuring a more resilient and protected environment for your applications.
Q17. How to monitor the Kubernetes cluster?
Monitoring a Kubernetes cluster involves setting up various tools and practices to collect and analyze data on the cluster’s health, performance, and resource usage. Here’s a step-by-step guide to monitoring a Kubernetes cluster effectively:
- Choose a Monitoring Solution: Select a monitoring solution suitable for your needs. Popular choices include Prometheus, Grafana, Datadog, New Relic, and others. Prometheus and Grafana are widely used in Kubernetes environments due to their flexibility and strong community support.
- Deploy Monitoring Components: Set up the monitoring components within the Kubernetes cluster. For Prometheus and Grafana, you can use Helm charts or manifests to deploy them. Prometheus scrapes metrics from Kubernetes components and applications, while Grafana provides visualization and dashboard capabilities.
- Node-Level Metrics: Collect and monitor node-level metrics (CPU, memory, disk, network) using tools like Node Exporter or cAdvisor. These tools export metrics to Prometheus, which stores and manages the data.
- Application Metrics: Instrument your applications with client libraries like Prometheus client libraries or OpenTelemetry to expose custom metrics. These metrics can be scraped by Prometheus and visualized in Grafana.
- Kubernetes Metrics: Use kube-state-metrics to expose Kubernetes-specific metrics like the status of deployments, replicasets, pods, and services. These metrics provide insights into the state of Kubernetes resources.
- Monitor Cluster Components: Keep an eye on the health of Kubernetes components like API server, controller manager, etcd, and scheduler. Prometheus can scrape metrics from these components, and alerting rules can be configured to notify of any issues.
- Alerting: Configure alerting rules in Prometheus or through your monitoring solution to get notified of critical issues or abnormal behavior. Use Alertmanager to manage and route alerts to various channels like email, Slack, or other messaging platforms.
- Visualize Data: Create custom dashboards in Grafana to visualize the collected metrics. Display critical cluster metrics, application-specific metrics, and any other relevant data for easy monitoring.
- Long-Term Storage: Consider setting up long-term storage for historical metrics data. Tools like Thanos or VictoriaMetrics can help store and query historical data from Prometheus.
- Log Aggregation: Use a centralized logging solution (e.g., ELK Stack, Fluentd, Loki) to collect and analyze container logs for debugging and troubleshooting purposes.
- Security Monitoring: Implement security monitoring to detect potential security threats and unauthorized access attempts in your Kubernetes cluster.
- Regular Review and Maintenance: Regularly review the monitoring data, analyze trends, and fine-tune alerting thresholds. Keep monitoring components updated and ensure that they are functioning correctly.
By following these steps and continuously monitoring your Kubernetes cluster, you can gain valuable insights, detect and resolve issues promptly, and maintain a stable and well-performing environment for your applications.
Q18. How to get the central logs from POD?
To collect central logs from Pods running in a Kubernetes cluster, you can use a centralized logging solution. One popular approach is to use the ELK Stack, which consists of three main components: Elasticsearch, Logstash (or Fluentd), and Kibana. Here’s how you can set up central logging using the ELK Stack:
- Install Elasticsearch: Deploy Elasticsearch as a central log storage and indexing solution. Elasticsearch will store and index the logs collected from various Pods.
- Install Logstash or Fluentd: Choose either Logstash or Fluentd as the log collector and forwarder. Both tools can collect logs from different sources, including application logs from Pods, and send them to Elasticsearch.
– If using Logstash: Install and configure Logstash on a separate node or container. Create Logstash pipelines to process and forward logs to Elasticsearch.
– If using Fluentd: Deploy Fluentd as a DaemonSet on each node in the Kubernetes cluster. Fluentd will collect logs from containers running on each node and send them to Elasticsearch.
- Configure Application Logs: Inside your Kubernetes Pods, ensure that your applications are configured to log to the standard output and standard error streams. Kubernetes will collect these logs by default.
- Install Kibana: Set up Kibana as a web-based user interface to visualize and query the logs stored in Elasticsearch. Kibana allows you to create custom dashboards and perform complex searches on your log data.
- Configure Log Forwarding: Configure Logstash or Fluentd to forward logs from the Kubernetes Pods to Elasticsearch. This may involve defining log collection rules, filters, and log parsing configurations.
- View Logs in Kibana: Access Kibana using its web interface and connect it to the Elasticsearch backend. Once connected, you can create visualizations, search logs, and analyze log data from your Kubernetes Pods.
Additionally, you can consider using other centralized logging solutions like Loki or Splunk for log aggregation and analysis. The process may vary slightly depending on the logging tool you choose, but the core concept remains the same: collect logs centrally from Kubernetes Pods and make them available for analysis and visualization in a user-friendly interface.
Keep in mind that setting up and maintaining a centralized logging solution requires careful planning and consideration of resource usage, especially if you have a large number of Pods generating a significant volume of logs.
Q10. What is Google Container Engine?
Google Container Engine (GKE) is an open-source management platform for Docker containers and clusters. This Kubernetes based engine supports only those clusters which run within Google’s public cloud services.
Kubernetes Interview | Kubernetes Interview Questions and Answers | Kubernetes Training | Edureka
In this Edureka video on 𝐊𝐮𝐛𝐞𝐫𝐧𝐞𝐭𝐞𝐬 𝐈𝐧𝐭𝐞𝐫𝐯𝐢𝐞𝐰 𝐐𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬, you will learn everything about Kubernetes interview questions with detailed answers. We have covered Kubernetes basic to advanced questions so this video will be helpful to a beginner as well as an expert.
Kubernetes Interview Questions
Q11. What is Heapster?
Heapster is a cluster-wide aggregator of data provided by Kubelet running on each node. This container management tool is supported natively on Kubernetes cluster and runs as a pod, just like any other pod in the cluster. So, it basically discovers all nodes in the cluster and queries usage information from the Kubernetes nodes in the cluster, via on-machine Kubernetes agent.
Q12. What is Minikube?
Minikube is a tool that makes it easy to run Kubernetes locally. This runs a single-node Kubernetes cluster inside a virtual machine.
Q13. What is Kubectl?
Kubectl is the platform using which you can pass commands to the cluster. So, it basically provides the CLI to run commands against the Kubernetes cluster with various ways to create and manage the Kubernetes component.
Q14. What is Kubelet?
This is an agent service which runs on each node and enables the slave to communicate with the master. So, Kubelet works on the description of containers provided to it in the PodSpec and makes sure that the containers described in the PodSpec are healthy and running.
Q15. What do you understand by a node in Kubernetes?


Fig 6: Node In Kubernetes – Kubernetes Interview Questions
Architecture-Based Kubernetes Interview Questions
This section of questions will deal with the questions related to the architecture of Kubernetes.
Q1. What are the different components of Kubernetes Architecture?
The Kubernetes Architecture has mainly 2 components – the master node and the worker node. As you can see in the below diagram, the master and the worker nodes have many inbuilt components within them. The master node has the kube-controller-manager, kube-apiserver, kube-scheduler, etcd. Whereas the worker node has kubelet and kube-proxy running on each node.


Fig 7: Architecture Of Kubernetes – Kubernetes Interview Questions
Q2. What do you understand by Kube-proxy?
Kube-proxy can run on each and every node and can do simple TCP/UDP packet forwarding across backend network service. So basically, it is a network proxy that reflects the services as configured in Kubernetes API on each node. So, the Docker-linkable compatible environment variables provide the cluster IPs and ports which are opened by proxy.
Q3. Can you brief on the working of the master node in Kubernetes?
Kubernetes master controls the nodes and inside the nodes the containers are present. Now, these individual containers are contained inside pods and inside each pod, you can have a various number of containers based upon the configuration and requirements. So, if the pods have to be deployed, then they can either be deployed using user interface or command-line interface. Then, these pods are scheduled on the nodes, and based on the resource requirements, the pods are allocated to these nodes. The kube-apiserver makes sure that there is communication established between the Kubernetes node and the master components.


Fig 8: Representation Of Kubernetes Master Node – Kubernetes Interview Questions
Q4. What is the role of kube-apiserver and kube-scheduler?
The kube – apiserver follows the scale-out architecture and is the front end of the master node control panel. This exposes all the APIs of the Kubernetes Master node components and is responsible for establishing communication between Kubernetes Node and the Kubernetes master components.
The kube-scheduler is responsible for distributing and managing the workload on the worker nodes. So, it selects the most suitable node to run the unscheduled pod based on resource requirements and keeps track of resource utilization. It ensures that the workload is not scheduled on already full nodes.
Q5. Can you brief me about the Kubernetes controller manager?
Multiple controller processes run on the master node but are compiled together to run as a single process: the Kubernetes Controller Manager. So, Controller Manager is a daemon that embeds controllers and does namespace creation and garbage collection. It owns the responsibility and communicates with the API server to manage the end-points.
So, the different types of controller manager running on the master node are :


Fig 9: Types Of Controllers – Kubernetes Interview Questions
Q6. What is ETCD?
Etcd is written in Go programming language and is a distributed key-value store used for coordinating distributed work. So, Etcd stores the configuration data of the Kubernetes cluster, representing the state of the cluster at any given point in time.
Q7. What are the different types of services in Kubernetes?
The following are the different types of services used:


Fig 10: Types Of Services – Kubernetes Interview Questions
Q8. What do you understand by load balancer in Kubernetes?
A load balancer is one of the most common and standard ways of exposing service. There are two types of load balancer used based on the working environment i.e. either the Internal Load Balancer or the External Load Balancer. The Internal Load Balancer automatically balances load and allocates the pods with the required configuration whereas the External Load Balancer directs the traffic from the external load to the backend pods.
Kubernetes Interview Questions
Q9. What is Ingress network, and how does it work?
Ingress network is a collection of rules that acts as an entry point to the Kubernetes cluster. This allows inbound connections, which can be configured to give services externally through reachable URLs, load balance traffic, or by offering name-based virtual hosting. So, Ingress is an API object that manages external access to the services in a cluster, usually by HTTP and is the most powerful way of exposing service.
Now, let me explain to you the working of Ingress network with an example.
There are 2 nodes having the pod and root network namespaces with a Linux bridge. In addition to this, there is also a new virtual ethernet device called flannel0(network plugin) added to the root network.
Now, suppose we want the packet to flow from pod1 to pod 4. Refer to the below diagram.


Fig 11: Working Of Ingress Network – Kubernetes Interview Questions
- So, the packet leaves pod1’s network at eth0 and enters the root network at veth0.
- Then it is passed on to cbr0, which makes the ARP request to find the destination and it is found out that nobody on this node has the destination IP address.
- So, the bridge sends the packet to flannel0 as the node’s route table is configured with flannel0.
- Now, the flannel daemon talks to the API server of Kubernetes to know all the pod IPs and their respective nodes to create mappings for pods IPs to node IPs.
- The network plugin wraps this packet in a UDP packet with extra headers changing the source and destination IP’s to their respective nodes and sends this packet out via eth0.
- Now, since the route table already knows how to route traffic between nodes, it sends the packet to the destination node2.
- The packet arrives at eth0 of node2 and goes back to flannel0 to de-capsulate and emits it back in the root network namespace.
- Again, the packet is forwarded to the Linux bridge to make an ARP request to find out the IP that belongs to veth1.
- The packet finally crosses the root network and reaches the destination Pod4.
Q10. What do you understand by Cloud controller manager?
The Cloud Controller Manager is responsible for persistent storage, network routing, abstracting the cloud-specific code from the core Kubernetes specific code, and managing the communication with the underlying cloud services. It might be split out into several different containers depending on which cloud platform you are running on and then it enables the cloud vendors and Kubernetes code to be developed without any inter-dependency. So, the cloud vendor develops their code and connects with the Kubernetes cloud-controller-manager while running the Kubernetes.
The various types of cloud controller manager are as follows:


Fig 12: Types Of Cloud Controller Manager – Kubernetes Interview Questions
Q11. What is Container resource monitoring?
As for users, it is really important to understand the performance of the application and resource utilization at all the different abstraction layer, Kubernetes factored the management of the cluster by creating abstraction at different levels like container, pods, services and whole cluster. Now, each level can be monitored and this is nothing but Container resource monitoring.
The various container resource monitoring tools are as follows:


Fig 13: Container Resource Monitoring Tools – Kubernetes Interview Questions
Q12. What is the difference between a replica set and a replication controller?
Replica Set and Replication Controller do almost the same thing. Both ensure that a specified number of pod replicas are running at any given time. The difference comes with the usage of selectors to replicate pods. Replica Set uses Set-Based selectors while replication controllers use Equity-Based selectors.
- Equity-Based Selectors: This type of selector allows filtering by label key and values. So, in layman’s terms, the equity-based selector will only look for the pods with the exact same phrase as the label.
Example: Suppose your label key says app=nginx; then, with this selector, you can only look for those pods with label app equal to nginx. - Selector-Based Selectors: This type of selector allows filtering keys according to a set of values. So, in other words, the selector-based selector will look for pods whose label has been mentioned in the set.
Example: Say your label key says app in (Nginx, NPS, Apache). Then, with this selector, if your app is equal to any of Nginx, NPS, or Apache, the selector will take it as a true result.
Q13. What is a Headless Service?
Headless Service is similar to that of a ‘Normal’ service but does not have a Cluster IP. This service enables you to directly reach the pods without the need to access them through a proxy.
Q14. What are the best security measures that you can take while using Kubernetes?
The following are the best security measures that you can follow while using Kubernetes:


Fig 14: Best Security Measures – Kubernetes Interview Questions
Q15. What are federated clusters?
Multiple Kubernetes clusters can be managed as a single cluster with the help of federated clusters. So, you can create multiple Kubernetes clusters within a data center/cloud and use federation to control/manage them all at one place.
The federated clusters can achieve this by doing the following two things. Refer to the below diagram.


Fig 15: Federated Clusters – Kubernetes Interview Questions
Scenario-Based Kubernetes Interview Questions
This section of questions will consist of various scenario-based questions that you may face in your interviews.
Scenario 1: Suppose a company built on monolithic architecture handles numerous products. Now, as the company expands in today’s scaling industry, their monolithic architecture started causing problems.
How do you think the company shifted from monolithic to microservices and deploy their services containers?
Solution:
As the company’s goal is to shift from their monolithic application to microservices, they can end up building piece by piece, in parallel and just switch configurations in the background. Then they can put each of these built-in microservices on the Kubernetes platform. So, they can start by migrating their services once or twice and monitor them to make sure everything is running stable. Once they feel everything is going good, then they can migrate the rest of the application into their Kubernetes cluster.
Scenario 2: Consider a multinational company with a very much distributed system, with a large number of data centers, virtual machines, and many employees working on various tasks.
How do you think can such a company manage all the tasks in a consistent way with Kubernetes?
Solution:
As all of us know that I.T. departments launch thousands of containers, with tasks running across a numerous number of nodes across the world in a distributed system.
In such a situation the company can use something that offers them agility, scale-out capability, and DevOps practice to the cloud-based applications.
So, the company can, therefore, use Kubernetes to customize their scheduling architecture and support multiple container formats. This makes it possible for the affinity between container tasks that gives greater efficiency with an extensive support for various container networking solutions and container storage.
Scenario 3: Consider a situation, where a company wants to increase its efficiency and the speed of its technical operations by maintaining minimal costs.
How do you think the company will try to achieve this?
Solution:
The company can implement the DevOps methodology, by building a CI/CD pipeline, but one problem that may occur here is the configurations may take time to go up and running. So, after implementing the CI/CD pipeline the company’s next step should be to work in the cloud environment. Once they start working on the cloud environment, they can schedule containers on a cluster and can orchestrate with the help of Kubernetes. This kind of approach will help the company reduce their deployment time, and also get faster across various environments.
Scenario 4: Suppose a company wants to revise it’s deployment methods and wants to build a platform which is much more scalable and responsive.
How do you think this company can achieve this to satisfy their customers?
Solution:
In order to give millions of clients the digital experience they would expect, the company needs a platform that is scalable, and responsive, so that they could quickly get data to the client website. Now, to do this the company should move from their private data centers (if they are using any) to any cloud environment such as AWS. Not only this, but they should also implement the microservice architecture so that they can start using Docker containers. Once they have the base framework ready, then they can start using the best orchestration platform available i.e. Kubernetes. This would enable the teams to be autonomous in building applications and delivering them very quickly.
Scenario 5: Consider a multinational company with a very much distributed system, looking forward to solving the monolithic code base problem.
How do you think the company can solve their problem?
Solution
Well, to solve the problem, they can shift their monolithic code base to a microservice design and then each and every microservices can be considered as a container. So, all these containers can be deployed and orchestrated with the help of Kubernetes.
Kubernetes Interview Questions
Scenario 6: All of us know that the shift from monolithic to microservices solves the problem from the development side, but increases the problem at the deployment side.
How can the company solve the problem on the deployment side?
Solution
The team can experiment with container orchestration platforms, such as Kubernetes and run it in data centers. So, with this, the company can generate a templated application, deploy it within five minutes, and have actual instances containerized in the staging environment at that point. This kind of Kubernetes project will have dozens of microservices running in parallel to improve the production rate as even if a node goes down, then it can be rescheduled immediately without performance impact.
Scenario 7: Suppose a company wants to optimize the distribution of its workloads, by adopting new technologies.
How can the company achieve this distribution of resources efficiently?
Solution
The solution to this problem is none other than Kubernetes. Kubernetes makes sure that the resources are optimized efficiently, and only those resources are used which are needed by that particular application. So, with the usage of the best container orchestration tool, the company can achieve the distribution of resources efficiently.
Scenario 8: Consider a carpooling company wants to increase their number of servers by simultaneously scaling their platform.
How do you think will the company deal with the servers and their installation?
Solution
The company can adopt the concept of containerization. Once they deploy all their application into containers, they can use Kubernetes for orchestration and use container monitoring tools like Prometheus to monitor the actions in containers. So, with such usage of containers, giving them better capacity planning in the data center because they will now have fewer constraints due to this abstraction between the services and the hardware they run on.
Scenario 9: Consider a scenario where a company wants to provide all the required hand-outs to its customers having various environments.
How do you think they can achieve this critical target in a dynamic manner?
Solution
The company can use Docker environments, to put together a cross-sectional team to build a web application using Kubernetes. This kind of framework will help the company achieve the goal of getting the required things into production within the shortest time frame. So, with such a machine running, the company can give the hands-outs to all the customers having various environments.
Scenario 10: Suppose a company wants to run various workloads on different cloud infrastructure from bare metal to a public cloud.
How will the company achieve this in the presence of different interfaces?
Solution
The company can decompose its infrastructure into microservices and then adopt Kubernetes. This will let the company run various workloads on different cloud infrastructures.
Top 10 Technologies To Learn In 2025 | Top Trending Technologies in 2025 | Edureka
In this video, we explore the Top 10 Technologies to Learn in 2025 that will shape the future of industries and careers. From Generative AI driving innovation and creativity to Cybersecurity safeguarding the digital landscape, this video has it all. Learn how DevOps streamlines development processes, Cloud Computing enables flexibility and scalability, and Extended Reality (XR) transforms the way we interact with virtual and real-world environments. Along with these technologies, we also dive into the salary potential for each field, giving you insights into the most rewarding career paths. Whether you’re a student, professional, or tech enthusiast, this video highlights the essential skills and trends you need to future-proof your career. Watch now to stay ahead in the ever-evolving world of technology!
Multiple Choice Kubernetes Interview Questions
This section of questions will consist of multiple-choice interview questions, that are frequently asked in interviews.
Q1. What are minions in the Kubernetes cluster?
- They are components of the master node.
- They are the work-horse / worker node of the cluster.[Ans]
- They are monitoring engine used widely in kubernetes.
- They are docker container service.
Q2. Kubernetes cluster data is stored in which of the following?
- Kube-apiserver
- Kubelet
- Etcd[Ans]
- None of the above
Q3. Which of them is a Kubernetes Controller?
- ReplicaSet
- Deployment
- Rolling Updates
- Both ReplicaSet and Deployment[Ans]
Q4. Which of the following are core Kubernetes objects?
- Pods
- Services
- Volumes
- All of the above[Ans]
Q5. The Kubernetes Network proxy runs on which node?
- Master Node
- Worker Node
- All the nodes[Ans]
- None of the above
Q6. What are the responsibilities of a node controller?
- To assign a CIDR block to the nodes
- To maintain the list of nodes
- To monitor the health of the nodes
- All of the above[Ans]
Q7. What are the responsibilities of Replication Controller?
- Update or delete multiple pods with a single command
- Helps to achieve the desired state
- Creates a new pod, if the existing pod crashes
- All of the above[Ans]
Q8. How to define a service without a selector?
- Specify the external name[Ans]
- Specify an endpoint with IP Address and port
- Just by specifying the IP address
- Specifying the label and api-version
Q9. What did the 1.8 version of Kubernetes introduce?
- Taints and Tolerations[Ans]
- Cluster level Logging
- Secrets
- Federated Clusters
Q10. The handler invoked by Kubelet to check if a container’s IP address is open or not is?
- HTTPGetAction
- ExecAction
- TCPSocketAction[Ans]
- None of the above
Overwhelmed with all these questions?
We at edureka! Are here to help you with every step on your journey of becoming a certified DevOps professional, therefore besides this Kubernetes Interview Questions blog, we have come up with DevOps Interview Questions blog which will help you to crack the DevOps-related questions!
Got a question for us? Please mention to our edureka community, and our experts will revert at the earliest.