
Data Science with Python Certification Course
- 131k Enrolled Learners
- Weekend
- Live Class
(49300)





 Copy Link!
Copy Link!Data visualization is an essential component of a data scientist’s skill set which you need to master in the journey of becoming Data Scientist. It is statistics and design combined in a meaningful way to interpret the data with graphs and plots. In this ggplot2 tutorial we will see how to visualize data using gglot2 package provided by R.
We see that data visualization tools help in exploring the data, as well as explaining the data.
This blog will cover the following topics:
Let us begin this blog by first looking at the types of visualization.
In statistics, we generally have two kinds of visualization:
We have a number of visualization tools to make aesthetic graphs. Let’s look at some of them:
Paid Tools: These tools might be initially costly to purchase but the solutions provided by them are definitely worth the money spent.
Open source Tools: Though not as effective as the paid tools, these do help in taking care of all the necessities.
In any language the grammatical rules are to be kept in mind to construct meaningful sentences, such as:
> “I am John” makes sense, because it follows proper grammar.
> “Am John I” doesn’t make sense because it doesn’t adhere to the grammatical rules.
Similarly, we have “grammar of graphics” which needs to be followed for creating perfect graphs.
| Component | Description |
| Data | The data-set being plotted |
| Aesthetics | The scales onto which we plot our data |
| Geometry | The visual elements used for our data |
| Facet | Groups by which we divide the data |
The ggplot2 package is a simplified implementation of grammar of graphics written by Hadley Wickham for R.
It takes care of many of the fiddly details that make plotting a hassle (like drawing legends) as well as providing a powerful model of graphics that makes it easy to produce complex multi-layered graphics.
So, let’s dive into the R code:
install.packages("ggplot2")library(ggplot2)install.packages("statisticalModeling")library(statisticalModeling)head(Birth_weight) ## baby_wt income mother_age smoke gestation mother_wt ## 1 120 level_1 27 nonsmoker 284 100 ## 2 113 level_4 33 nonsmoker 282 135 ## 3 128 level_2 28 smoker 279 115 ## 4 108 level_1 23 smoker 282 125 ## 5 132 level_2 23 nonsmoker 245 140 ## 6 120 level_2 25 nonsmoker 289 125
str(Birth_weight) This will give us the structure of the data-set
## 'data.frame': 884 obs. of 6 variables: ## $ baby_wt : int 120 113 128 108 132 120 143 144 141 110 ... ## $ income : chr "level_1" "level_4" "level_2" "level_1" ... ## $ mother_age: int 27 33 28 23 23 25 30 32 23 36 ... ## $ smoke : chr "nonsmoker" "nonsmoker" "smoker" "smoker" ... ## $ gestation : int 284 282 279 282 245 289 299 282 279 281 ... ## $ mother_wt : int 100 135 115 125 140 125 136 124 128 99 ...
And now, let’s start plotting!!!!
ggplot(data = Birth_weight,aes(x=baby_wt))+geom_bar()The above code has three parts:

ggplot2 tutorial:bar plot
We can easily say that the weight is in the range of 55-175 by just looking at this bar plot.
ggplot(data = Birth_weight,aes(x=mother_age))+geom_bar()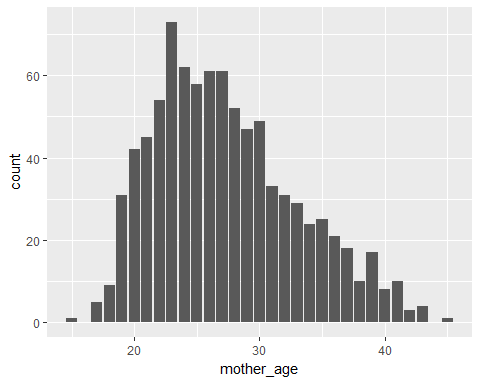
ggplot2 tutorial:bar plot
This graph shows that the mother’s age would lie in the range of 15-45.
ggplot(data = Birth_weight,aes(x=mother_age))+geom_bar(fill="aquamarine4")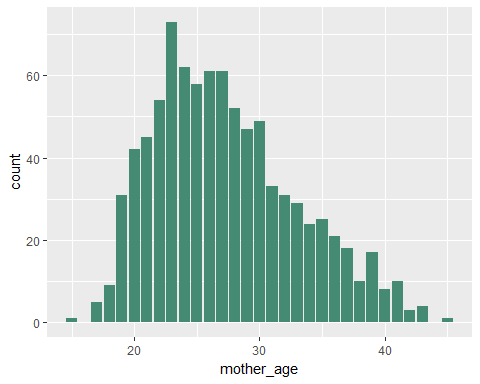
ggplot2 tutorial:bar plot
Same plot as above, but it looks prettier, doesn’t it?
ggplot(data = Birth_weight,aes(x=mother_age,fill=income))+geom_bar()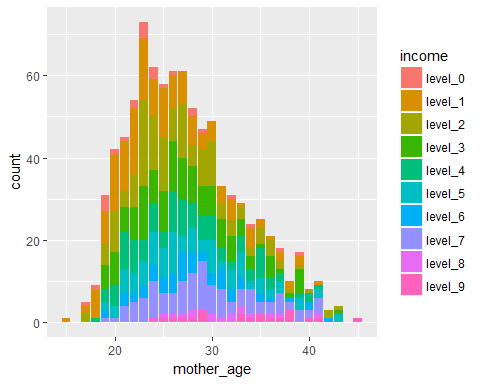
ggplot2 tutorial:bar plot
We see the variation In income levels across the distribution of mother’s age, i.e. across each bar, we are also depicting the variation in income levels.
ggplot(data = Birth_weight,aes(x=mother_age,fill=income))+geom_bar()+coord_flip()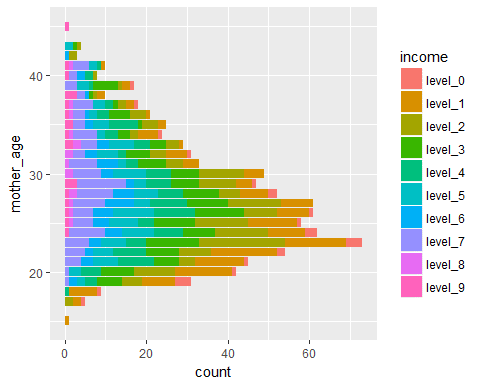
ggplot2 tutorial:bar plot
What do we observe? Nothing much to be honest…
We’ll also be working with the “mtcars” dataset. Thus, let’s observe the first six rows of this dataset.
head(mtcars)## mpg cyl disp hp drat wt qsec vs am gear carb ## Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4 ## Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4 ## Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1 ## Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1 ## Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2 ## Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
ggplot(data = mtcars,aes(x=cyl,fill=factor(gear)))+geom_bar()
ggplot2 tutorial:bar plot
We see that:
ggplot(data = mtcars,aes(x=cyl,fill=factor(gear)))+geom_bar(position = "fill")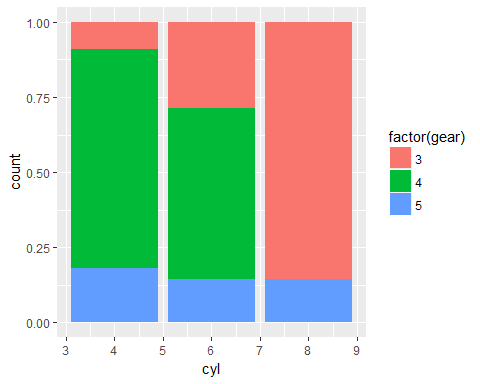
ggplot2 tutorial:bar plot
Same bar plot, showing proportion instead of count.
ggplot(data = mtcars,aes(x=cyl,fill=factor(gear)))+geom_bar(position = "dodge")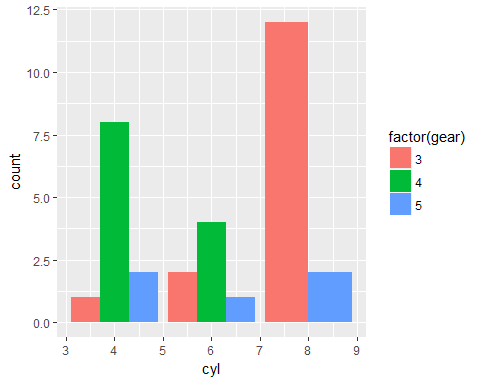
ggplot2 tutorial:bar plot
We see individual bars for number of gears.
The same inference can be drawn but it is much clear from this graph.
ggplot(data = Birth_weight,aes(x=mother_age,fill=smoke))+geom_bar()+facet_grid(. ~smoke)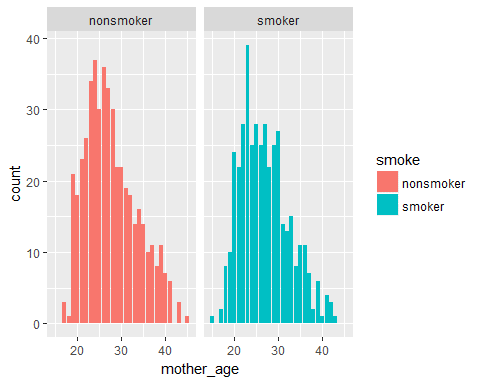
ggplot2 tutorial:barplot
ggplot(data = mtcars,aes(x=mpg,y=hp,col=factor(cyl)))+geom_point()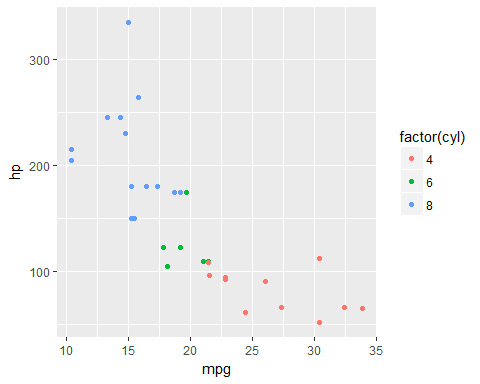
ggplot2 tutorial:scatter plot
We can infer that:
ggplot(data = mtcars,aes(x=mpg,y=hp,col=factor(cyl),size=factor(gear)))+geom_point()+labs(size="gear",col="cyl")
ggplot2 tutorial:Scatter plot
We can infer that:
ggplot(data = Birth_weight,aes(x=smoke,y=baby_wt,fill=income))+geom_boxplot()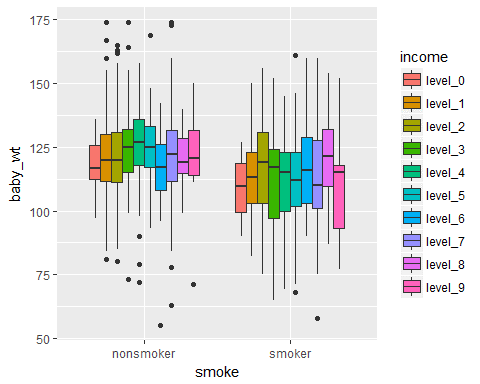
ggplot2 tutorial:Box plot
ggplot(data = Birth_weight,aes(x=mother_wt,y=baby_wt))+geom_smooth()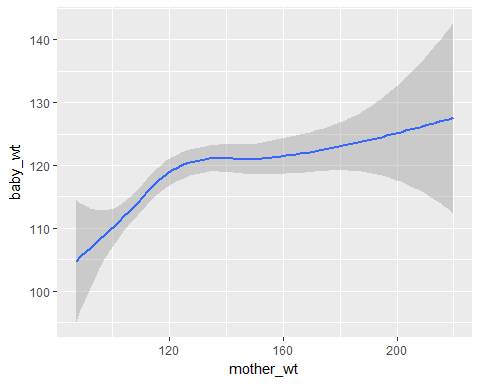
ggplot2 tutorial:line plot
We see that as the mother’s weight(mother_wt) increases, the baby’s weight(baby_wt) also increases.
ggplot(data = Birth_weight,aes(x=mother_wt,y=baby_wt,col=smoke))+geom_smooth()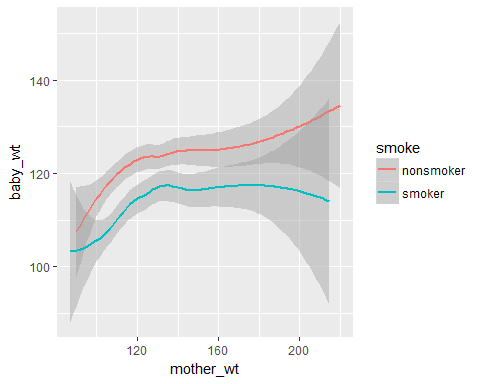
ggplot2 tutorial:Line plot
We see that if the mother is a non-smoker then the baby’s weight will be higher.
ggplot(data = Birth_weight,aes(x=smoke,y=baby_wt,col=smoke))+geom_jitter()
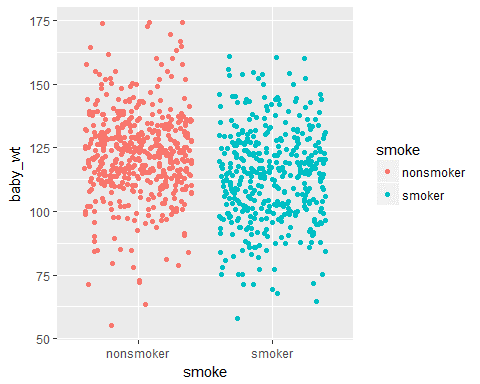
ggplot2 tutorial:Jitter plot
Prior to the statistical analysis and model building, it is essential to visually observe the relationship between the different data elements. This helps us in obtaining meaningful insights from the data to build better models. R’s ggplot2 package is one such data visualization tool which helps us in understanding the data.
Check out the R Certification Training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. Edureka’s Data Analytics with R training will help you gain expertise in R Programming, Data Manipulation, Exploratory Data Analysis, Data Visualization, Data Mining, Regression, Sentiment Analysis and using RStudio for real life case studies on Retail, Social Media.






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







