Full Stack Development Internship Program
- 29k Enrolled Learners
- Weekend/Weekday
- Live Class
(11300)





 Copy Link!
Copy Link!Ever utilized a program that creates blurriness-enhanced images or lifelike faces? Generative artificial intelligence underlies that magic, and the Variational Autoencoder (VAE) is a really effective instrument in that domain. Applied in everything from medical development to image creation, VAEs learn to compress and creatively replicate data. We will discuss VAEs in this blog, their differences from autoencoders and GANs, and walk through how to create one in TensorFlow using actual code examples.
Generative artificial intelligence is a class of artificial intelligence models capable of creating fresh content—text, images, audio, even code. These models learn data’s patterns and structure to produce like but unique outputs. For text, GPT; for images, GANs; for probabilistic modeling, VAEs.
Now that we understand generative AI, let’s look at one of the powerful tools within this space—Variational Autoencoders.
A variational autoencoder (VAE) is a kind of neural network designed to learn to encode input data into a distribution and subsequently decode it to rebuild the data. VAEs learn probability distributions—usually Gaussian—rather than fixed vectors unlike conventional autoencoders.
This lets VAEs create fresh data by sampling from the learnt distribution—a fundamental feature of generative models.
But how are VAEs different from regular autoencoders? Let’s compare the two.
| Feature | Autoencoder | Variational Autoencoder (VAE) |
|---|---|---|
| Latent space | Deterministic | Probabilistic (mean & variance) |
| Output | Exact reconstruction | Approximate (with variation) |
| Generative capability | Limited | Strong generative capabilities |
| Loss Function | Reconstruction loss | Reconstruction + KL divergence loss |
VAEs add a KL Divergence term to the loss function to ensure the learned distribution is close to a standard normal distribution.
Let’s understand how VAEs work under the hood
VAEs consist of two main parts:
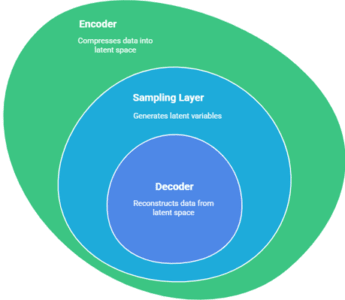
Encoder: Maps input data to a latent distribution (mean and variance).
Sampling Layer: Draws a latent vector from the encoded distribution using the reparameterization trick.
Decoder: Reconstructs the data from the sampled latent vector.
To enable backpropagation through a stochastic process, VAEs use:
data-start="2385" data-end="2450">z = mu + sigma * epsilon # epsilon ~ N(0, 1) data-start="2385" data-end="2450">
[/python]
This lets gradients flow through the sampling operation.
Now that we know the theory, let’s build one step by step.
We’ll use TensorFlow and Keras to build a VAE for the MNIST dataset.
1: Imports
import tensorflow as tf from tensorflow.keras import layers import numpy as np
2: Sampling Layer
class Sampling(layers.Layer): def call(self, inputs): z_mean, z_log_var = inputs epsilon = tf.random.normal(shape=tf.shape(z_mean)) return z_mean + tf.exp(0.5 * z_log_var) * epsilon
This custom layer implements the reparameterization trick.
Now, let’s implement the full VAE architecture.
3: Encoder
latent_dim = 2 encoder_inputs = tf.keras.Input(shape=(28, 28, 1)) x = layers.Flatten()(encoder_inputs) x = layers.Dense(128, activation='relu')(x) z_mean = layers.Dense(latent_dim)(x) z_log_var = layers.Dense(latent_dim)(x) z = Sampling()([z_mean, z_log_var]) encoder = tf.keras.Model(encoder_inputs, [z_mean, z_log_var, z], name="encoder")
4: Decoder
latent_inputs = tf.keras.Input(shape=(latent_dim,)) x = layers.Dense(128, activation='relu')(latent_inputs) x = layers.Dense(28 * 28, activation='sigmoid')(x) decoder_outputs = layers.Reshape((28, 28, 1))(x) decoder = tf.keras.Model(latent_inputs, decoder_outputs, name="decoder")
5: VAE Model
class VAE(tf.keras.Model):
def __init__(self, encoder, decoder, **kwargs):
super().__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def train_step(self, data):
if isinstance(data, tuple):
data = data[0]
with tf.GradientTape() as tape:
z_mean, z_log_var, z = self.encoder(data)
reconstruction = self.decoder(z)
reconstruction_loss = tf.reduce_mean(
tf.keras.losses.binary_crossentropy(data, reconstruction)
)
kl_loss = -0.5 * tf.reduce_mean(1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
return {"loss": total_loss}
With the model in place, let’s draw our blog to a close and cover common questions.
Variational autoencoders close the distance separating probabilistic graphical models from deep learning. For generative projects like image synthesis, anomaly detection, or representation learning—where we need control over the latent space—they are potent.
For a wide range of courses, training, and certification programs across various domains, check out Edureka’s website to explore more and enhance your skills!
1. What is the difference between variational and standard autoencoder?
Standard autoencoders learn a direct encoding → decoding.
VAEs learn a distribution over the latent space, enabling sampling and generative capabilities.
2. What are the uses of VAEs?
Image generation
Anomaly detection
Latent space interpolation
Data compression and reconstruction
3. What is the difference between PCA and Variational autoencoder?
| Feature | PCA | VAE |
|---|---|---|
| Transformation type | Linear transformation | Non-linear, deep network-based |
| Loss Function | No reconstruction loss | Uses reconstruction + KL loss |
| Generative Capability | No generative ability | Strong generative ability |
4. What is the drawback of VAE?
Reconstructions tend to be blurry, especially with images, due to the Gaussian assumption.
Less sharp than GANs for high-fidelity data generation.
5. What is better GANs or VAE?
| Criteria | GANs | VAEs |
|---|---|---|
| Sharpness | High | Moderate |
| Training Stability | Difficult (adversarial) | More stable |
| Latent Space | Unstructured | Structured & interpretable |
| Use Cases | Image synthesis, style transfer | Representation learning, interpolation |