








PySpark Certification Training Course
- 12k Enrolled Learners
- Weekend/Weekday
- Live Class
(4000)





 Copy Link!
Copy Link!Hadoop Components stand unrivalled when it comes to handling Big Data and with their outperforming capabilities, they stand superior. In this article, we shall discuss the major Hadoop Components which played the key role in achieving this milestone in the world of Big Data.
Hadoop can be defined as a collection of Software Utilities that operate over a network of computers with Software Frameworks on a distributed storage environment in order to process the Big Data applications in the Hadoop cluster.
Let us look into the Core Components of Hadoop.
The Core Components of Hadoop are as follows:

Let us discuss each one of them in detail.
MapReduce: It is a Software Data Processing model designed in Java Programming Language. MapReduce is a combination of two individual tasks, namely:
The MapReduce process enables us to perform various operations over the big data such as Filtering and Sorting and many such similar ones.
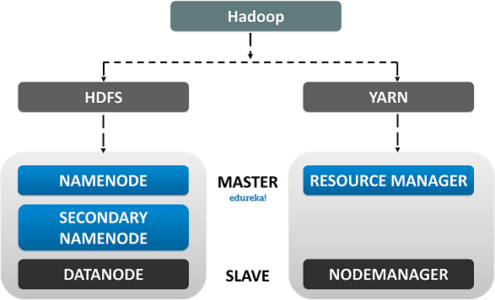
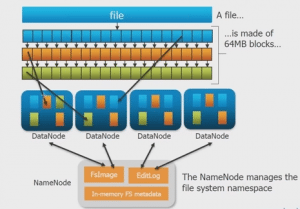
HDFS is the primary storage unit in the Hadoop Ecosystem. The HDFS is the reason behind the quick data accessing and generous Scalability of Hadoop.
You can get a better understanding with the Data Engineering Training in London.
The HDFS comprises the following components.
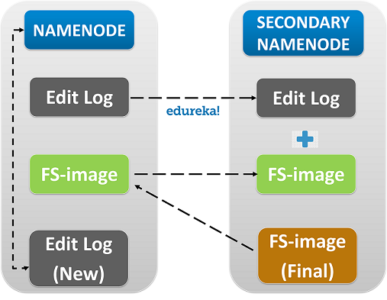
Explore and learn more about HDFS in this Big Data Course, which was designed by a Top Industry Expert from Big Data platform.
Let us Discuss each one of them in detail.
The next one in the docket is the YARN.

The YARN or Yet Another Resource Negotiator is the update to Hadoop since its second version. It is responsible for Resource management and Job Scheduling. Yarn comprises of the following components:
With this we are finished with the Core Components in Hadoop, now let us get into the Major Components in the Hadoop Ecosystem:
You can even check out the details of Big Data with the Data Engineer Training.
The Components in the Hadoop Ecosystem are classified into:
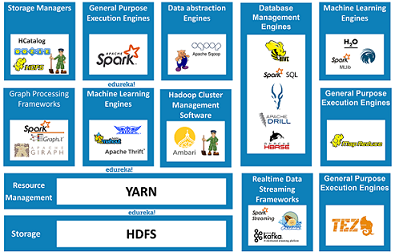

Data Storage

Hadoop Distributed File System, it is responsible for Data Storage. It provides Distributed data processing capabilities to Hadoop. HDFS is Fault Tolerant, Reliable and most importantly it is generously Scalable.

HCATALOG is a Table Management tool for Hadoop. It provides tabular data store of HIVE to users such that the users can perform operations upon the data using the advanced data processing tools such as the Pig, MapReduce etc.
 Zookeeper is known as the centralized Open Source server responsible for managing the configuration information, naming conventions and synchronisations for Hadoop clusters.
Zookeeper is known as the centralized Open Source server responsible for managing the configuration information, naming conventions and synchronisations for Hadoop clusters.

Oozie is a scheduler system responsible to manage and schedule jobs in a distributed environment. It runs multiple complex jobs in a sequential order to achieve a complex job done.
Now let us discuss a few General Purpose Execution Engines. The first one is
General Purpose Execution Engines

MapReduce is a Java–based parallel data processing tool designed to handle complex data sets in Hadoop so that the users can perform multiple operations such as filter, map and many more. MapReduce is used in functional programming.

Spark is an In-Memory cluster computing framework with lightning-fast agility. It can perform Real-time data streaming and ETL. Spark can also be used for micro-batch processing.

Tez is an extensible, high-performance data processing framework designed to provide batch processing as well as interactive data processing. It can execute a series of MapReduce jobs collectively, in the form of a single Job. This improves the processing to an exponential level.
With this let us now move into the Hadoop components dealing with the Database management system. Firstly,
Database Management Tools
Hive is a Data warehouse project by the Apache Software Foundation, and it was designed to provide SQL like queries to the databases. Hive is also used in performing ETL operations, HIVE DDL and HIVE DML.
Spark SQL is a module for structured data processing. It acts as a distributed Query engine. It provides programming abstractions for data frames and is mainly used in importing data from RDDs, Hive, and Parquet files.

Impala is an in-memory Query processing engine. It is used in Hadoop Clusters. it is designed to integrate itself with Hive meta store and share table information between the components.

Apache Drill is a low latency distributed query engine. Its major objective is to combine a variety if data stores by just a single query. It is capable to support different varieties of NoSQL databases.
HBase is an open-source, non-relational distributed database designed to provide random access to a huge amount of distributed data. Like Drill, HBase can also combine a variety of data stores just by using a single query.
With this, let us now get into Hadoop Components dealing with Data Abstraction.
Find out our Azure Data Engineer Course in Top Cities
Data Abstraction Engines
Pig is a high-level Scripting Language. It was designed to provide users to write complex data transformations in simple ways at a scripting level. The pig can perform ETL operations and also capable enough to analyse huge data sets.
Apache Sqoop is a simple command line interface application designed to transfer data between relational databases in a network. It is basically a data ingesting tool. it enables to import and export structured data at an enterprise level.
Now let us learn about, the Hadoop Components in Real-Time Data Streaming.
Real-Time Data Streaming Tools

Spark Streaming is basically an extension of Spark API. It was designed to provide scalable, High-throughput and Fault-tolerant Stream processing of live data streams.
Kafka is an open source Data Stream processing software designed to ingest and move large amounts of data with high agility. it uses Publish, Subscribes and Consumer model.
Flume is an open source distributed and reliable software designed to provide collection, aggregation and movement of large logs of data.
Now, let us understand a few Hadoop Components based on Graph Processing
Graph Processing Engines

Giraph is an interactive graph processing framework which utilizes Hadoop MapReduce implementation to process graphs. It is majorly used to analyse social media data.

GraphX is Apache Spark’s API for graphs and graph-parallel computation. GraphX unifies ETL (Extract, Transform & Load) process, exploratory analysis and iterative graph computation within a single system
Let’s get things a bit more interesting. Now we shall deal with the Hadoop Components in Machine Learning.
Machine Learning Engines

H2O is a fully open source, distributed in-memory machine learning platform with linear scalability. The H2O platform is used by over R & Python communities

Oryx is a general lambda architecture tier providing batch/speed/serving Layers. Its major objective is towards large scale machine learning.
Spark MLlib is a scalable Machine Learning Library. It was designed to provide Machine learning operations in spark.

Avro is a row-oriented remote procedure call and data Serialization tool. It is used in dynamic typing. Avro is majorly used in RPC.

Thrift is an interface definition language and binary communication protocol which allows users to define data types and service interfaces in a simple definition file. Thrift is mainly used in building RPC Client and Servers.

Mahout was developed to implement distributed Machine Learning algorithms. It is capable to store and process big data in a distributed environment across a cluster using simple programming models.
now finally, let’s learn about Hadoop component used in Cluster Management.
Cluster Management
 Ambari is a Hadoop cluster management software which enables system administrators to manage and monitor a Hadoop cluster.
Ambari is a Hadoop cluster management software which enables system administrators to manage and monitor a Hadoop cluster.
ZooKeeper is essentially a centralized service for distributed systems to a hierarchical key-value store It is used to provide a distributed configuration service, synchronization service, and naming registry for large distributed systems.
 With this we come to an end of this article, I hope you have learnt about the Hadoop and its Architecture with its Core Components and the important Hadoop Components in its ecosystem.
With this we come to an end of this article, I hope you have learnt about the Hadoop and its Architecture with its Core Components and the important Hadoop Components in its ecosystem.
For details, You can even check out tools and systems used by Big Data experts and its concepts with the Masters in data engineering.
Now that you have understood Hadoop Core Components and its Ecosystem, check out the Hadoop training in Pune by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka’s Big Data Architect Course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.





































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







