Ashutosh PandeyGenerative AI enthusiast with expertise in RAG (Retrieval-Augmented Generation) and LangChain, passionate...Generative AI enthusiast with expertise in RAG (Retrieval-Augmented Generation) and LangChain, passionate about building intelligent AI-driven solutions
Artificial Intelligence (AI) research is rapidly advancing, with DeepSeek AI emerging as one of the most promising models in the field. The new DeepSeek AI study paper goes into great detail about the system’s architecture, how it is trained, how it is optimized, and how it can be used in the real world.
Table of Content
This blog will break down the research paper’s key aspects, helping you understand how DeepSeek AI works and why it stands out in the AI landscape.
Overview of DeepSeek AI’s Research Paper
DeepSeek AI’s research paper goes into great depth about the architecture, dataset selection, model training, and performance benchmarks. The following are some of the main study goals:
Developing an efficient and scalable transformer-based AI model.
Enhancing multilingual support for diverse user applications.
Implementing optimized training techniques to reduce computational costs.
Benchmarking performance against other state-of-the-art AI models like GPT-4 and LLaMA.
The paper discusses how DeepSeek AI is designed to give quick, correct, and appropriate answers based on the situation. This makes it very competitive in areas like content creation, business automation, and conversational AI.
DeepSeek AI’s Core Architecture
The study paper talks about how DeepSeek AI is based on a transformer-based architecture, which is similar to OpenAI’s GPT models but has some important improvements. The most important parts are:
Transformer Model with Optimized Self-Attention
Uses an enhanced self-attention mechanism to improve computational efficiency.
Employs multi-head attention layers to capture deep contextual relationships.
Implements sparse attention mechanisms to handle longer sequences efficiently.
Pre-Training on Large-Scale Datasets
The model is trained on massive multilingual datasets, including:
Publicly available text data (news articles, books, research papers, and web content).
Domain-specific corpora to improve AI’s ability to understand industry-specific terminology.
Optimized tokenization ensures better handling of rare and out-of-vocabulary words.
Advanced Fine-Tuning and RLHF (Reinforcement Learning with Human Feedback)
Fine-tuned using domain-specific datasets to improve real-world applications.
RLHF (Reinforcement Learning with Human Feedback) aligns model responses with human expectations and reduces biases.
Training Methodologies & Optimization Techniques
The study paper from DeepSeek AI talks about different ways to train models that make them more efficient and effective:
Efficient Training with Low Latency
Uses model parallelism to distribute computations efficiently.
Implements gradient checkpointing to reduce memory usage during training.
Mixed-precision training (FP16, BF16) for faster processing with minimal performance loss.
Dataset Filtering & Preprocessing
Data deduplication techniques are used to remove redundant content and prevent overfitting.
The model is trained to identify and filter low-quality or biased data, improving response quality.
Hyperparameter Tuning for Stability
Learning rate schedules such as cosine annealing help prevent training instability.
Performance Benchmarks & Comparison with Other AI Models
The study paper compares DeepSeek AI to other models like GPT-4, LLaMA, and PaLM using a number of performance benchmarks. Important things to remember are:
Metric
DeepSeek AI
GPT-4
LLaMA 2
Response Speed
Faster
Moderate
Fast
Multilingual Support
Strong
Good
Limited
Memory Retention
Moderate
High
Moderate
Creativity in Text Generation
Good
Best
Average
Computational Efficiency
Optimized
High Cost
Efficient
DeepSeek AI surpasses many competitors in response speed and computational efficiency.
GPT-4 remains superior in deep contextual reasoning and creative writing.
LLaMA 2 struggles with multilingual support but is more lightweight.
Real-World Applications of DeepSeek AI
The study paper says that DeepSeek AI is made to do well in a number of real-world situations, such as
Content Generation & Writing
AI-powered blogging, scriptwriting, and marketing content creation.
Advanced summarization and paraphrasing for research and education.
AI Coding Assistance
Code generation, debugging, and software documentation.
AI-powered pair programming for developers.
Business & Enterprise Solutions
AI-driven customer support chatbots.
Automated document processing and analytics.
Healthcare & Legal Tech
Medical AI chatbots for diagnosis assistance.
AI-assisted contract analysis and legal document review.
Current Limitations
Memory retention for long conversations is not as advanced as ChatGPT-4 Pro.
Requires continual fine-tuning to adapt to real-world biases and misinformation.
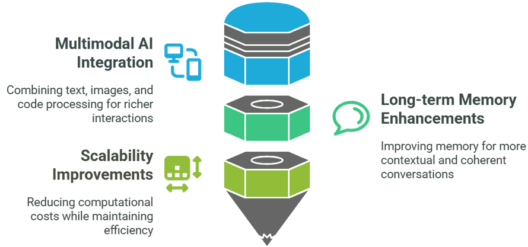
Future Improvements
Integration of multimodal AI (text, images, and code processing).
Enhanced long-term memory capabilities for better contextual conversations.
Scalability improvements to reduce computational costs.
Conclusion
The DeepSeek AI research paper provides valuable insights into the model’s architecture, training methodologies, and performance benchmarks. It highlights DeepSeek AI’s strengths in efficiency, multilingual capabilities, and real-world applications while also acknowledging areas that require further improvement.
FAQs
1. What is DeepSeek AI?
The artificial intelligence model DeepSeek AI is built on transformers and is made for advanced natural language processing (NLP). As a goal, it wants to offer effective, scalable, and multilingual AI answers for a wide range of real-world problems.
2. How is DeepSeek AI different from GPT-4 and LLaMA?
DeepSeek AI focuses on making computers work more efficiently, responding faster, and supporting many languages well. GPT-4 is better at deep contextual reasoning and creativity, while LLaMA is lighter. DeepSeek AI, on the other hand, strikes a good mix between speed, accuracy, and usefulness in the real world.
3. What are the core architectural improvements in DeepSeek AI?
Optimized self-attention mechanism for improved computational efficiency.
Enhanced multi-head attention layers to capture deep contextual relationships.
Sparse attention mechanisms to handle longer sequences more effectively.
4. What type of data is DeepSeek AI trained on?
DeepSeek AI is trained on big, multilingual datasets, such as
Publicly available text data (news, books, research papers, and web content).
Domain-specific corpora for industry-specific language understanding.
5. How does DeepSeek AI handle training efficiency?
Model parallelism distributes computations efficiently.
Gradient checkpointing reduces memory usage.
Mixed-precision training (FP16, BF16) speeds up processing with minimal performance loss.









 Copy Link!
Copy Link!