
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!DataFrame is the pinnacle of Spark’s Technological advancements that helped to achieve multiple potentialities in Big-data environment. It is an integrated data structure that helps programmers to perform multiple operations on data with a single API. Ill line up the docket of key points for understanding the DataFrames in Spark as below.
In simple terms, A Spark DataFrame is considered as a distributed collection of data which is organized under named columns and provides operations to filter, group, process, and aggregate the available data. DataFrames can also be used with Spark SQL. We can construct DataFrames from structured data files, RDDs, tables in Hive, or from an external database as shown below.

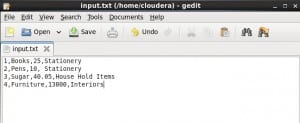
Here we have created a DataFrame about employees which has Name of the employee as string datatype, Employee-ID as string datatype, Employee phone number as an integer datatype, Employee address as a string datatype, Employee salary as a float datatype. The data of each employee is stored in each row as shown above.
Why do we need DataFrames?
DataFrames are designed to be multifunctional. We need DataFrames for:
Multiple Programming languages
Multiple data sources

Processing Structured and Semi-Structured Data
Slicing and Dicing the data
Now that we have understood the need for DataFrames, Let us move to the next stage where we would understand the features of DataFrames which give it an edge over other alternatives.
Features of DataFrames in Spark

So, these were the features of DataFrames, Let us now look into the sources of data for the DataFrames in Spark.
Sources for Spark DataFrame

Redefine your data analytics workflow and unleash the true potential of big data with Pyspark Course.
Creation of DataFrame in Spark
val Employee = seq(Row("Mike","Robert","Mike09@gmail.com",10000),Row("John","Milers","John09@gmail.com",20000),Row("Brett","Lee","Brett09@gmail.com",25000),
Row("Letty","Brown","Brown09@gmail.com",35000))
val EmployeeSchema = List(StructField("FirstName", StringType, true), StructField("LastName", StringType, true), StructField("MailAddress", StringType, true), StructField("Salary", IntegerType, true))
val EmpDF = spark.createDataFrame(spark.sparkContext.parallelize(Employee),StructType(EmployeeSchema))
EmpDF.show

val Department = Seq(Row(1001,"Admin"),Row(1002,"IT-Support"),Row(1003,"Developers"),Row(1004,"Testing"))
val DepartmentSchema = List(StructField("DepartmentID", IntegerType, true), StructField("DepartmentName", StringType, true))
val DepDF = spark.createDataFrame(spark.sparkContext.parallelize(Department),StructType(DepartmentSchema))
DepDF.show


import org.apache.spark.sql.types._ import org.apache.spark.storage.StorageLevel import scala.io.Source import scala.collection.mutable.HashMap import java.io.File import org.apache.spark.sql.Row import org.apache.spark.sql.types._ import scala.collection.mutable.ListBuffer import org.apache.spark.util.IntParam import org.apache.spark.rdd.RDD import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf import org.apache.spark.sql.SQLContext import org.apache.spark.rdd._ val sqlContext = new org.apache.spark.sql.SQLContext(sc) import sqlContext.implicits._ import sqlContext._
val schema = StructType(Array(StructField("ID", IntegerType, true),StructField("Name", StringType, true),StructField("Age", IntegerType, true),StructField("
Nationality", StringType, true),StructField("Potential", IntegerType, true),StructField("Club", StringType, true),StructField("Value", StringType, true),StructFiel
d("Preferred Foot", StringType, true),StructField("International Reputation", IntegerType, true),StructField("Skill Moves", IntegerType, true),StructField("Positio
n", StringType, true),StructField("Jersey Number", IntegerType, true),StructField("Crossing", IntegerType, true),StructField("Finishing", IntegerType, true),Struct
Field("HeadingAccuracy", IntegerType, true),StructField("ShortPassing", IntegerType, true),StructField("Volleys", IntegerType, true),StructField("Dribbling", Integ
erType, true),StructField("Curve", IntegerType, true),StructField("FKAccuracy", IntegerType, true),StructField("LongPassing", IntegerType, true),StructField("BallC
ontrol", IntegerType, true),StructField("Acceleration", IntegerType, true),StructField("SprintSpeed", IntegerType, true),StructField("Agility", IntegerType, true),
StructField("Balance", IntegerType, true),StructField("ShotPower", IntegerType, true),StructField("Jumping", IntegerType, true),StructField("Stamina", IntegerType,
true)))

val FIFAdf = spark.read.format("csv").option("header", true").load("/user/edureka_566977/FIFA2k19file/FIFA2k19.csv")
FIFAdf.printSchema()

#count FIFAdf.count()

FIFAdf.columns.foreach(println)

#describe
FIFAdf.describe("Value").show

#select
FIFAdf.select("Name","Nationality").show

#select and distinct
FIFAdf.select("Name","Club").distinct.show()

#select and filter
FIFAdf.select("Index","ID","Name","Age","Nationality","Overall","Potential","Value","Skill Moves","Body Type","Position","Jersey Number").filter(" Age < 30 ").show

So, this was about the FIFA 2019 dataset example that we dealt with, Now let me walk you through a use case which will help you learn more about DataFrames in spark with the most trending topic which is none other than “The Game of Thrones”
DataFrames in Spark: Game of Thrones Use Case

Now we have successfully loaded all the libraries we needed for processing our DataFrames in Spark.
val schema = StructType(Array(StructField("Name", StringType, true), StructField("Allegiances", StringType, true), StructField("Death Year", IntegerType, tr
ue), StructField("Book of Death", IntegerType, true), StructField("Death Chapter", IntegerType, true), StructField("Book Intro Chapter", IntegerType, true), Struct
Field("Gender", IntegerType, true), StructField("Nobility", IntegerType, true), StructField("GoT", IntegerType, true), StructField("CoK", IntegerType, true), Struc
tField("SoS", IntegerType, true), StructField("FfC", IntegerType, true), StructField("DwD", IntegerType, true)))

val schema2 = StructType(Array(StructField("name", StringType, true), StructField("year", IntegerType, true), StructField("battle_number", IntegerType, true
), StructField("attacker_king", StringType, true), StructField("defender_king", StringType, true), StructField("attacker_1", StringType, true), StructField("attack
er_2", StringType, true), StructField("attacker_3", StringType, true), StructField("attacker_4", StringType, true), StructField("defender_1", StringType, true), St
ructField("defender_2", StringType, true), StructField("defender_3", StringType, true), StructField("defender_4", StringType, true), StructField("attacker_outcome"
, StringType, true), StructField("battle_type", StringType, true), StructField("major_death", StringType, true), StructField("major_capture", IntegerType, true), S
tructField("attacker_size", IntegerType, true), StructField("defender_size", IntegerType, true), StructField("attacker_commander", StringType, true), StructField("
defender_commander", StringType, true), StructField("summer", IntegerType, true), StructField("location", StringType, true), StructField("region", StringType, true
), StructField("note", StringType, true)))

val GOTdf = spark.read.option("header", "true").schema(schema).csv("/user/edureka_566977/GOT/character-deaths.csv")
val GOTbattlesdf = spark.read.option("header", "true").schema(schema2).csv("/user/edureka_566977/GOT/battles.csv")

GOTdf.printSchema()

GOTbattlesdf.printSchema()

After verifying the schema, let us print the data present in our DataFrame. We can use the following code to print the data present in our DataFrame.
#select
GOTdf.select("Name","Allegiances","Death Year","Book of Death","Death Chapter","Book Intro Chapter","Gender","Nobility","GoT","CoK","SoS","FfC","DwD").show

#select and groupBy
sqlContext.sql("select attacker_1, count(distinct(' ')) from battles group by attacker_1").show

#select and filter
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 298").show

#select
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 299").show

#select and filter
GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location").filter("year == 300").show

#groupBy
sqlContext.sql("select battle_type, count(' ') from battles group by battle_type").show

#and
sqlContext.sql("select year, attacker_king, defender_king, attacker_outcome, battle_type, attacker_commander, defender_commander from battles where attacker_outcome == 'win' and battle_type =='ambush'").show

#groupBy
sqlContext.sql("select attacker_1, count(' ') from battles group by attacker_1").show

#select
sqlContext.sql("select attacker_king, count(' ') from battles group by attacker_king").show

#count
sqlContext.sql("select defender_1, count(' ') from battles group by defender_1").show

#groupBy
sqlContext.sql("select defender_king, count(' ') from battles group by defender_king").show

#select
val df1 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Allegiances == 'Lannister' and Gender == '1'")

#Select
val df2 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Allegiances == 'Lannister' and Gender == '0'")

#where
val df4 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Nobility == '1'")

#select and where
val df5 = sqlContext.sql("select Name, Allegiances, Gender from deaths where Nobility == '0'")

#and
val df6 = sqlContext.sql("select Name, Allegiances, Gender from deaths where GoT == '1' and Cok == '1' and SoS == '1' and FfC == '1' and DwD == '1' and Nobility == '1'")

#OrderBy
val dat = GOTbattlesdf.select("name","year","battle_number","attacker_king","defender_king","attacker_outcome","attacker_commander","defender_commander","location")orderBy(desc("battle_number"))
dat.show

#DropDuplicates
GOTbattlesdf.select("attacker_king","defender_king").dropDuplicates().show()

So, with this, we come to an end of this DataFrames in Spark article. I hope we sparked a little light upon your knowledge about DataFrames, their features and the various types of operations that can be performed on them.
This article based on Apache Spark and Scala Certification Training is designed to prepare you for the Cloudera Hadoop and Spark Developer Certification Exam (CCA175). You will get in-depth knowledge on Apache Spark and the Spark Ecosystem, which includes Spark DataFrames, Spark SQL, Spark MLlib and Spark Streaming. You will get comprehensive knowledge on Scala Programming language, HDFS, Sqoop, Flume, Spark GraphX and Messaging System such as Kafka.



































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







