








Data Cleaning is very important for correct analysis and the performance of the model. Wrong data, like names spelled wrong, values not present, or records that aren’t correct, can make it hard to draw the right conclusions. Inconsistencies like negative sales or empty revenue fields, for instance, can throw off figures and trends. Cleaning data makes sure it is consistent, accurate, and in the right style, which stops mistakes and raises the quality of insights. Models and studies can give wrong results if the data isn’t cleaned properly. This step is necessary for every project.
When you begin a new data project, the data you collect is rarely ideal for your analysis straight away. As a result, you must clean your data before starting every new project.
Cleaning your data is the process of removing errors, outliers, and inconsistencies and ensuring that all of your data is in the correct format for your research. Data that contains several errors or has not undergone this data-cleaning process is referred to as filthy data.
This step may appear unnecessary to many junior data professionals, but be assured that it is critical! Without adequate data cleansing, your model may arrive at the incorrect result, your graph may display a fictitious trend, and your statistics may be completely false.
Suppose a manager needs to distribute a limited number of work hours or budget across a small team for a specific task. The dataset might look like this:
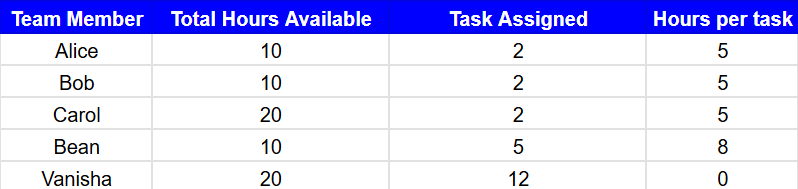

In this case, each team member is allocated an equal share of the resources, ensuring fair distribution and efficiency in task management. This approach can be applied to workload balancing, budget allocation, or even meeting scheduling.
Now, let us see why it is essential
Why Is Data Cleaning Essential?
The most crucial thing a data science practitioner should do is use Pandas to clean data in Python. Processes and analyses can suffer from inaccurate or poor-quality data. Overall productivity will eventually rise with clean data, which will also enable the highest quality information to be used in decision-making.

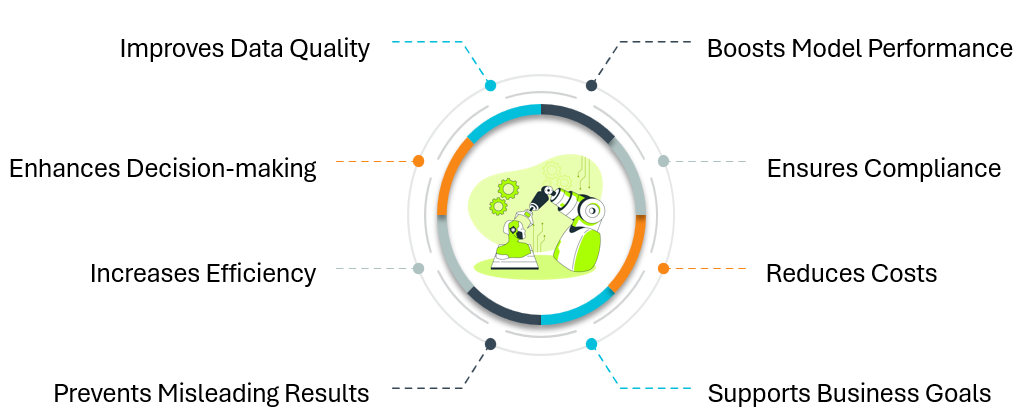
The above image shows why data cleaning is important, let’s discuss them one by one:
- Improves Data Quality: Assures data dependability, accuracy, and consistency.
- Enhances Decision-making: Offers reliable information for deeper understanding.
- Increases Efficiency: Cuts down on analytical errors and expedites troubleshooting.
- Prevents Misleading Results: Inaccurate judgments brought on by subpar data are avoided.
- Boosts Model Performance: Machine learning models become more accurate and dependable.
- Ensures Compliance: Adheres to privacy and usability requirements and data rules.
- Reduces Costs: Less money is wasted on inaccurate or insufficient data.
- Supports Business Goals: By coordinating data with strategic goals, better results are guaranteed.
Now that we understand why data cleaning is necessary, let us understand what is dirty data.
Understanding Dirty Data
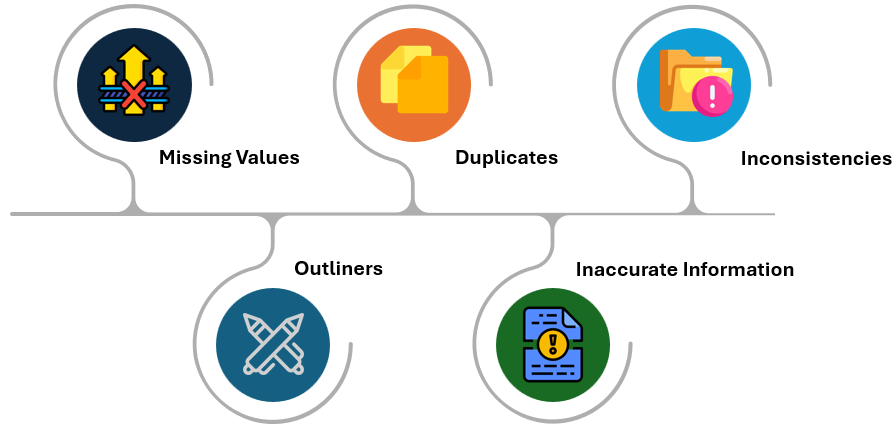

The above image shows that Data contamination can result from various mistakes and discrepancies. Let’s discuss them one by one:
1. Missing values:
It is very typical to have incomplete data sets. It’s possible that your dataset lacks several years’ worth of data, only includes partial client information, or doesn’t include the entire range of products offered by your business.
Your analysis may be impacted by missing values in a number of ways. The absence of significant amounts of important data may skew your findings. Furthermore, missing cells in a DataFrame or NaN values may cause some Python code to malfunction, which can be very frustrating when creating your model.
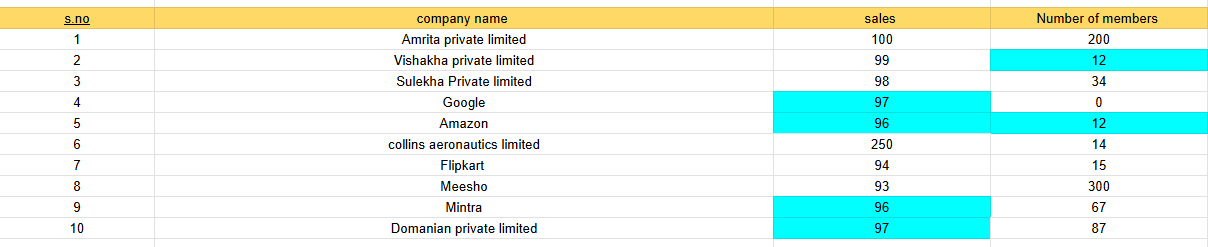
In the image below is the dataset of sales by different companies as you can see, the rows marked in red show how the dataset is missing some values:


2. Outliners:
Values that deviate significantly from the norm and are not indicative of the data are called outliers. Typographical errors or unusual situations may cause outliers. Making the distinction between informative extreme events and actual outliers is crucial. Outliers have the potential to distort your data and eventually point to an incorrect response.
We used the same dataset of sales from several different businesses to make the picture below. Because the range of sales is between 1 and 100, the rows that are colored in green are outliers. Similarly, the column “number of members,” which has a range between 1 and 200, has 300 outliers.


3. Duplicates:
As we saw above, duplicate data entries can overrepresent one entry in your analysis, which could result in an incorrect conclusion. Look for duplicates that appear more than once and those that provide updated or contradicting information.
You can refer to the image below, the rows colored in green are the duplicates in a dataset:

4. Inaccurate information:
Occasionally, our data set contains incorrect values. You might have obsolete information, improperly labeled data, an erroneous product number, or a customer’s name spelled wrong.
Verifying your source is crucial because it can occasionally be difficult to tell if your info is inaccurate! The quality of your data determines the quality of your analysis.
The below dataset shows a comparison between grades of students , the rows marked in yellow show inaccurate information:


5. Inconsistencies:
Inconsistencies can take many different forms. Inconsistent data entry could indicate a typo or other problem. If you see a product with two prices displayed at once, an ingredient that changes the ID number, or a customer’s age displayed backward, it is worth checking to make sure everything is proper.
Data format inconsistency is another difficult kind of inconsistency. Other values may be reported in different formats (Month Day, Year vs. Day-Month-Year), data types (floats vs. integers), file types (.jpg vs. .png), or even in different units (kilometers vs. miles vs. inches).
If we take the same dataset from outlines and carefully see the sales row, then values of Mintra and domanian private limited have inconsistencies in the data, also the same for the number of members:

Because of these discrepancies, your code will have difficulty, if not impossible, comprehending the values appropriately. Now that we understand dirty data, let’s discuss how to clean it using Python.
How to Clean Your Data in Python?
For cleaning your data, you can use famous libraries like Pandas and numpy, here are the code snippets given below:
1. Load the dataset
import pandas as pd
# Load your dataset=
df = pd.read_csv('your_dataset.csv')
2. Handle Missing Data
- Checking for missing values:
print(df.isnull().sum())
- Filling missing values:
df['column_name'].fillna(value, inplace=True) # Replace missing values
- Remove rows/columns with too many missing values:
df.dropna(inplace=True) # Drops rows with missing values
3. Remove Duplicates
df.drop_duplicates(inplace=True)
4. Fix Inconsistent Formatting
- Standardize text:
df['column_name'] = df['column_name'].str.lower() # Convert to lowercase
- Standardize dates:
df['date_column'] = pd.to_datetime(df['date_column'])
5. Handle Outliers
- Identify outliers:
print(df['column_name'].describe())
- Remove outliers using thresholds:
df = df[df['column_name'] < threshold] # Keep values below a threshold
6. Convert Data Types
df['column_name'] = df['column_name'].astype('int') # Convert to integer
7. Rename Columns
df.rename(columns={'old_name': 'new_name'}, inplace=True)
8. Save Cleaned Data
df.to_csv('cleaned_dataset.csv', index=False)
By following these steps, you ensure your data is accurate, consistent, and ready for analysis or machine learning tasks.
After you have a good idea of why data cleaning is important, you may move on to data exploration and preprocessing, where you look over and get your cleaned data ready for analysis.
Data Exploration and Preprocessing
You must understand your dataset before using it in a sophisticated study. To gain this level of comprehension, you should conduct some data exploration, which can be considered the pre-analytical analysis.
Steps for Data Exploration and Preprocessing Data are as follows:
- Learn from the Data:
- Bring up the dataset and look at how it is structured (columns, data types, and amount).
Check to see if there are any missing, duplicate, or strange numbers.
- Bring up the dataset and look at how it is structured (columns, data types, and amount).
- EDA stands for exploratory data analysis.
- To figure out central trends, use summary statistics like mean, median, and mode.
Use plots (like histograms, scatterplots, and heatmaps) to see how data is distributed, how it correlates, and how it relates to other data.
Find patterns, oddities, and outliers.
- To figure out central trends, use summary statistics like mean, median, and mode.
- Deal with missing data:
- Get rid of rows and columns that have too many empty spaces if they’re not important.
Use statistical methods (mean, median) or predictive models to fill in missing numbers.
- Get rid of rows and columns that have too many empty spaces if they’re not important.
- Deal with Outliers:
- Use mathematical tools (IQR, Z-score) or visual aids (boxplots) to find outliers.
Determine whether to get rid of or limit the outliers based on how much they affect the data.
- Use mathematical tools (IQR, Z-score) or visual aids (boxplots) to find outliers.
- Changing the data:
- Scale numerical traits (for example, by normalizing or standardizing them).
Use one-hot encoding or label encoding to encode categorical traits.
- Scale numerical traits (for example, by normalizing or standardizing them).
Since you know the common procedures for performing data exploration on a dataset, let’s discuss how to clean data in Python.

This “Python Full Course” video provides a comprehensive overview of Python programming. This Python tutorial for beginners has foundational concepts such as variables and data types to advanced topics like functions, modules, and object-oriented programming.
Techniques for Data Cleaning in Python


Let’s get down to the specifics of some Python data cleaning methods by looking at how to fix some common issues with dirty data.
1. Taking care of missing numbers
When you have a big dataset, some fields will always be missing from at least some of the records. The NaN entries can mess up some Python functions, which means your model is wrong. Also, you are losing out on important data.
You can either remove the missing value from the analysis or try to guess an acceptable value to put in its place when you find one. I think that if your dataset is pretty small, you should look at the rows that are missing numbers to figure out what to do next.
import pandas as pd Identify rows with NaN valuesrows_with_nan = df[df.isnull().any(axis=1)] View the rows with NaN valuesprint(rows_with_nan)
Most of the time, deleting an item is not the first option because it takes out information that could be useful from the analysis.
But sometimes the best thing to do is to delete the entry. For example, if the entry is just a date and doesn’t give you any other useful information, then it shouldn’t be kept.
Also, the best way to deal with entries that are missing values is to delete them. You can delete entries with NaNs if you are short on time and the rest of the entry is not important to the study.
To get rid of rows in a DataFrame that have NaNs, you can use the.dropna() method from the Pandas library.
import pandas as pd # Assuming df is your DataFramedf.dropna(inplace=True)
Putting in a reasonable number is usually the best way to deal with missing values. It can be an art to figure out what a reasonable value is, but there are a few tried-and-true ways that can help you get started.
Pandas’.fillna() method will fill in missing numbers with the mean so that the distribution doesn’t change.
import pandas as pd # Assuming df is your DataFrame # Replace NaN values with the mean of the columndf.fillna(df.mean(), inplace=True)
Simple imputation works well in the sci-kit learn package as well.
from sklearn.impute import SimpleImputerimport pandas as pd
# Assuming df is your DataFrameimputer = SimpleImputer(strategy='mean')df_imputed = pd.DataFrame(imputer.fit_transform(df), columns=df.columns)
You could use a KNN or regression imputation to find a good value if you need a more complicated replacement method. At the end of the day, the method you pick will rest on your data, your needs, and the resources you have access to.
2. Finding and dealing with outliers
It can be hard to deal with outliers. Some data that doesn’t make sense, like how the stock market reacts to disasters like COVID-19 and the Global Recession, is actually very important. Others, on the other hand, may be typos or not important in very few cases and should be taken out.
To tell the difference, you usually need to know how your data fits into the bigger picture, which you should have learned from looking at it before, and you need to know what you want to achieve with your study.
You can see a lot of outliers when you plot the data, but you can also use statistical methods to find them.
One popular way is to give each data point a Z-score and get rid of the values that have the highest or lowest Z-score.
import numpy as npimport pandas as pd
#Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)
Add some outliersdata[0] = 100data[1] = -100 =
# Calculate Z-scoresz_scores = (data - np.mean(data)) / np.std(data)
# Identify outliers based on Z-score threshold (e.g., 3)threshold = 3outliers = np.where(np.abs(z_scores); threshold)[0] print("Outliers identified using Z-score method:")
print(data[outliers])
You can also find the interquartile range (IQR) of the distribution and mark as possible outliers any numbers that are Q1-(1.5 x IQR) or Q3 + (1.5 x IQR).
import numpy as npimport pandas as pd
#Generate some sample datanp.random.seed(0)data = np.random.randint(low=0, high=11, size=1000)
#Add some outliersdata[0] = 100data[1] = -100
# Calculate quartiles and IQRq1 = np.percentile(data, 25)q3 = np.percentile(data, 75)iqr = q3 - q1
# Identify outliers based on IQRlower_bound = q1 - (1.5 * iqr)upper_bound = q3 + (1.5 * iqr)outliers = np.where((data < lower_bound) | (data > upper_bound))[0] print("Outliers identified using IQR method:")print(data[outliers])
Once you’ve found any outliers and decided they’re a problem, there are a number of ways to handle them. After figuring out that the oddity is caused by a mistake, you might be able to get rid of it by fixing the mistake.
Sometimes, you might be able to get rid of the outlier or replace it with a number that is less extreme while keeping the shape of the distribution as a whole.
Set a limit, or threshold, on the range of values in your data and change any values that are outside that range with a certain value. This is called capping.
import pandas as pdimport numpy as np
<code># Create a sample DataFrame with outliersdata = { 'A': [100, 90, 85, 88, 110, 115, 120, 130, 140], 'B': [1, 2, 3, 4, 5, 6, 7, 8, 9]}df = pd.DataFrame(data)
# Define the lower and upper thresholds for capping (Here I used the 5th and 95th percentiles)lower_threshold = df.quantile(0.05)upper_threshold = df.quantile(0.95)
# Cap outlierscapped_df = df.clip(lower=lower_threshold, upper=upper_threshold, axis=1) print("Original DataFrame:")print(df)print("nCapped DataFrame:")print(capped_df)
You can change your data in some situations so that outliers don’t have as much of an effect. For example, you can use a square root or logarithmic transformation.
When you change your data, be careful. If you’re not careful, you could cause more problems in the future. Before you change your info, there are a few things you should think about.
- Figure out how the data is distributed: Before you apply any transformation, you should figure out how your data is distributed and how different changes will affect it.
- Pick out the right transformation: Choose a transformation method that works for how you want to distribute your information.
- Deal with zeros and negative numbers: Some changes might not work with data containing zeros or negative numbers. For example, when taking logarithms, adding a small constant can help prevent problems.
- Check info that has been changed: Once you’re done changing the data, you need to make sure that the new distribution fits with the assumptions of your study.
- Think about how it can be interpreted: Transformed data may be harder to understand than the original data. Make sure that everyone who has a stake in the matter knows how the change will affect the interpretation of the results.
Take a statistics class like DataCamp’s Introduction to Statistics in Python or Statistics Fundamentals with Python to learn more about how to change data. Now that we have discuss the techniques lets deep dive into data transformation and feature engineering.
3. Data Transformation and Feature Engineering
Data transformation and feature engineering are two types of preprocessing that are used to change raw data into a shape that machine learning algorithms and statistical analysis can use better. We’ll take a quick look at some common data transformation and feature engineering methods in Python in this section.
4. The process of normalizing and standardizing
Normalization and standardization are two ways to make features of the same size, which is important for many machine learning methods.
When you normalize data, you set the range to a specific number, usually between 0 and 1. This makes sure that all the features are on the same size and stops bigger features from taking over smaller ones.
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler()scaled_data = scaler.fit_transform(data)
On the other hand, standardization changes the numbers so that the mean is 0 and the standard deviation is 1. This method works well when the data has a range of different scales and ranges, and it makes sure that each trait has the same effect on the model.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler()standardized_data = scaler.fit_transform(data)
How you scale your data will depend on the specifics of your data and the needs of the model you want to use.
5. Putting categorical values into code
In machine learning, encoding categorical factors is an important step before working with features that are not numbers. Qualitative data, like types, classes, or names, are stored in categorical variables. These factors need to be turned into numbers so that they can be used in machine learning algorithms.
When you encode categorical variables, one-hot encoding is often used. This method turns each group into a binary vector. It is best to use this method with nominal categorical variables, where the groups don’t naturally fall in a certain order or hierarchy.
import pandas as pdencoded_data = pd.get_dummies(data, columns=['categorical_column'])
import pandas as pd
#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5]}df = pd.DataFrame(data)
#Performe one-hot encoding encoded_data = pd.get_dummies(df, columns==['Color'])print("Original DataFrame")print(df)print("nEncoded DataFrame:")print(encoded_data)
Label encoding is another method. It gives each group its own unique integer. There is a number value assigned to each category, which turns the names for the categories into ordinal numbers. This method works for ordinal categorical variables, where the groups naturally fall into a certain order.
from sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()encoded_data['categorical_column'] = encoder.fit_transform(data['categorical_column'])
from sklearn.preprocessing import LabelEncoderimport pandas as pd
#Create a sample DataFrame with categorical column data = { 'ID' : [1, 2, 3, 4, 5] 'Color' : [ 'Red', 'Blue', 'Green', 'Red', 'Green' ]}df = pd.DataFrame(data)
#Perform label encodingencoder = LabelEncoder()df ['Color_LabelEncoded'] = encoder.fit_transform(df['Color'])print("Original DataFrame:")print(df[['ID', 'Color']])print("nDataFrame with Label Encoded Column:")print(df[['ID', 'Color_LabelEncoded']])
It is important to pick the right encoding method based on the type of categorical variable and what the machine learning program needs. Label encoding works well for ordinal variables while one-hot encoding works better for nominal variables.
Techniques for Feature Engineering


Feature engineering is a step in the process of building a machine learning model that involves adding new features or changing old ones. This is a normal thing to do when the raw data doesn’t have any features that help with the learning task or when the features that are there aren’t in a form that the learning algorithm can use.
Imagine that you have a set of data about house prices and you want to guess how much each house will sell for based on things like the number of rooms, the size of the living area in square feet, and the property’s state. But the dataset doesn’t have a feature that directly measures how good or bad the house is generally.
You can make a new feature by putting together current ones or getting the information you need.
For example, you could make a feature called “Overall Condition” by adding up the scores of the condition of different parts of the house, like the kitchen’s condition, the basement’s condition, the house’s age, any recent renovations, and so on.
If there isn’t a straight line between the features and the goal variable, you can make polynomial features by raising existing features to different powers. This method helps show complicated connections between variables that might not be able to be separated in a straight line.
from sklearn.preprocessing import PolynomialFeaturespoly = PolynomialFeatures(degree=2)polynomial_features = poly.fit_transform(data)
Sometimes, you may have to deal with datasets with a lot of dimensions or traits that aren’t linearly related to each other. You can lower the number of dimensions in the dataset while keeping most of the useful data by using methods like Principal Component Analysis (PCA).
from sklearn.decomposition import PCApca = PCA(n_components=2)transformed_features = pca.fit_transform(data)
Feature engineering makes sure that your model has the right data in the right shape. Feature engineering has a lot of different techniques. Which one you use will rely on what you want to do.
This study on feature engineering might teach you some more skills that will help you.
Cleaning Data in Python: Best Practices and Tips


Cleaning up the data is an important part of any project that uses data analysis or machine learning. As you try to make your data cleaning process run more smoothly, here are some tips to keep in mind:
1. Keep raw info separate.
Keep the original at all times!
When you clean up data, this is the most important thing you can do. Keep a copy of the original data files away from the ones that have been cleaned up and worked on. This way, you’ll always have a point of reference and can quickly go back to the original info if you need to.
I always make a copy of the raw data file before making any changes. To tell which copy is the original, I add the word “-RAW” to the file name.
2. Write down your code for cleaning up info.
Add comments to your code to show what each step of cleaning does and what assumptions were made.
3. Keep an eye out for unexpected results.
You should make sure that cleaning up the data doesn’t change the spread too much or add any biases that weren’t meant to be there. After cleaning up the data, exploring it again and again can help you make sure you are on the right track.
4. Keep a log of data cleaning.
If your cleaning process takes a long time or is automated, you might want to keep a different document where you write down the specifics of each step.
It might be good in the future to know things like the date, the exact action taken, and any problems that came up.
Don’t forget to put this paper somewhere easy to get to, like in the same project folder as the code or data. If you have an automated pipeline that is updated regularly, you might want to make this log a natural part of the process of cleaning the data. In this way, you can check in and make sure everything is going well.
5. Write functions that can be used again and again.
Find common data-cleaning jobs and turn them into functions that can be used again and again. This lets you clean up more than one file with the same steps. This is very helpful if you want to map the abbreviations used by your business.
To make sure you don’t forget anything, use DataCamp’s Data Cleaning Checklist!
Conclusion
Cleaning up data isn’t just a boring job; it’s an important step that sets the stage for all successful machine learning and data analysis projects. By making sure your data is correct, consistent, and dependable, you set yourself up to make smart choices and gain useful insights.
If you use dirty data, you might come to wrong conclusions and studies, which can have big effects whether you’re making business decisions or dividing candy among friends. Cleaning your data takes time and work, but it’s worth it in the end because it makes your studies more reliable and your results useful.
Check out DataCamp’s course on cleaning up data for more information and hands-on tasks. This data-cleaning code-along is a fun way to get your hands dirty.


FAQ
1. What does it mean to clean data, and why is it important?
Fixing or getting rid of wrong, damaged, or missing data is what data cleaning is all about. It makes sure that the data is correct, reliable, and usable for jobs like machine learning or analysis.
2. What should I do when I need to use missing info in Python?
Fill in blanks with a default value with fillna().
You can get rid of rows or columns with missing data by calling dropna().
For example:
df['column'].fillna(0, inplace=True) # Replace with 0df.dropna(inplace=True) # Drop rows with missing values
3. How do you remove duplicates from a dataset?
Use drop_duplicates() to remove duplicate rows:
df.drop_duplicates(inplace=True)
4. What are the best tools for cleaning up data in Python?
Pandas are used to work with and clean up organized data.
NumPy: For working with numbers.
OpenPyXL lets you work with Excel files.
5. How do you detect and handle outliers?
Use statistical methods like the IQR (Interquartile Range) or Z-scores.
For a wide range of courses, training, and certification programs across various domains, check out Edureka’s website to explore more and enhance your skills!