
Microsoft Azure Data Engineering Training Cou ...
- 15k Enrolled Learners
- Weekend
- Live Class
(3450)





 Copy Link!
Copy Link!Azure Data Factory (ADF) and Azure Synapse Analytics are some of the instrumental tools used when it comes to data integration and data transformation. Another element that can be identified in both services is the copy operation, with the help of which data can be transferred between different systems and formats.
This activity is rather critical of migrating data, extending cloud and on-premises deployments, and getting data ready for analytics. In this all-encompassing tutorial blog, we are going to give a detailed explanation of the Copy activity with special attention to datastores, file type, and options.
Azure Data Factory and Azure Synapse Analytics support a vast array of data stores for the Copy activity.
These include:
This broad list of supported data stores means that you can connect to data from nearly any source and pull it into Azure for further processing.
The copy activity in azure data factory supports a diverse set of file formats, making it flexible for various data scenarios:
The supported formats include editing of different data types to help achieve integration with your existing systems.
Azure Data Factory and Synapse Analytics are present in almost every Azure geography in the world. Regarding the setup of Your Copy activity, make sure that your services and data stores are in the same or a similar region to avoid the instance of unnecessary latency.
Configuring the Copy activity involves several steps:
Configure the Copy Activity: Once you have defined linked services and datasets in the Data Factory service, you then define the Copy activity, thereby completing the pipeline. Here you are setting such attributes as data integration units, parallel copies, and fault tolerance.
Synapse pipelines or copy activity in azure data factory syntax usually includes source and sink attributes as well as other optional parameters.
Below is a simple example:
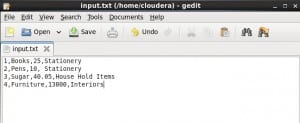
{
"name": "CopyFromBlobToSql",
"type": "Copy",
"inputs": [
{
"referenceName": "InputDataset"
}
],
"outputs": [
{
"referenceName": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink"
}
}
}
In the above syntax:
You can further configure additional properties, such as fault tolerance and logging options.
Azure provides robust monitoring features for tracking the progress and performance of your Copy activities. You can view pipeline run histories, monitor data movement in real-time, and set up alerts for failures or performance issues. This ensures that you can troubleshoot and optimize your data integration processes effectively.
Incremental copy is a feature that allows you to transfer only the data that has changed since the last run, rather than copying the entire dataset every time. This is particularly useful for large datasets where only a small portion of the data changes regularly. Incremental copy reduces the amount of data transferred, thereby improving performance and reducing costs.
Performance can be optimized in several ways:
In case of failure during data transfer, Azure Data Factory and Synapse Analytics allow you to resume the Copy activity from the last failed run, rather than starting over. This saves time and ensures data continuity.
When copying data, you can also choose to preserve metadata such as column names, data types, and file properties. This ensures that the data remains consistent and usable after transfer.
For file-based sinks, you can add metadata tags to the files during the copy process. These tags can include information like the source of the data, the date of transfer, and other custom tags that help in data management and organization.
Azure Data Factory supports schema and data type mapping between source and destination. This allows for seamless data transformation, ensuring that data types are compatible between different systems.
You can add additional columns to your data during the copy process. This can be useful for adding metadata or calculated fields to the data as it moves between systems.
The Copy activity can automatically create tables in the sink destination if they do not already exist. This is particularly useful when integrating with new or dynamic data sources.
Fault tolerance settings allow the copy activity in azure data factory to continue running even if some rows fail to copy. You can configure the activity to skip failed rows, log the errors, and continue with the rest of the data transfer.
After the Copy activity completes, you can verify data consistency between the source and the sink. This ensures that all data has been transferred correctly and that there are no discrepancies.
Session logs provide detailed information about the data transfer process, including the number of rows copied, any errors encountered, and the overall performance of the activity. These logs are essential for monitoring and troubleshooting your data integration processes.
For more in-depth knowledge and hands-on experience with Azure Data Factory, consider enrolling in an Azure Data Engineering Courses Online. This course covers data movement, transformation, and orchestration in detail, equipping you with the skills to manage complex data engineering tasks on Azure.
Allow to achieve parallelism, fine-tune queries, and perform massive data loading to Azure Blob Storage to reduce data transfer time.
Data Movement enables Copy; Data Transformation enables Data Flow; Control enables Execute Pipeline.
Use wildcard paths, or turn on recursive copy in datasets, or use the ‘ForEach’ activity in order to loop through many files.
It is recommended to employ Azure IR for cloud-based data, Self-hosted IR for the on-premises environment, and Azure-SSIS IR for SSIS packages.






































 Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP







